Declaration officielle
Ce qu'il faut comprendre
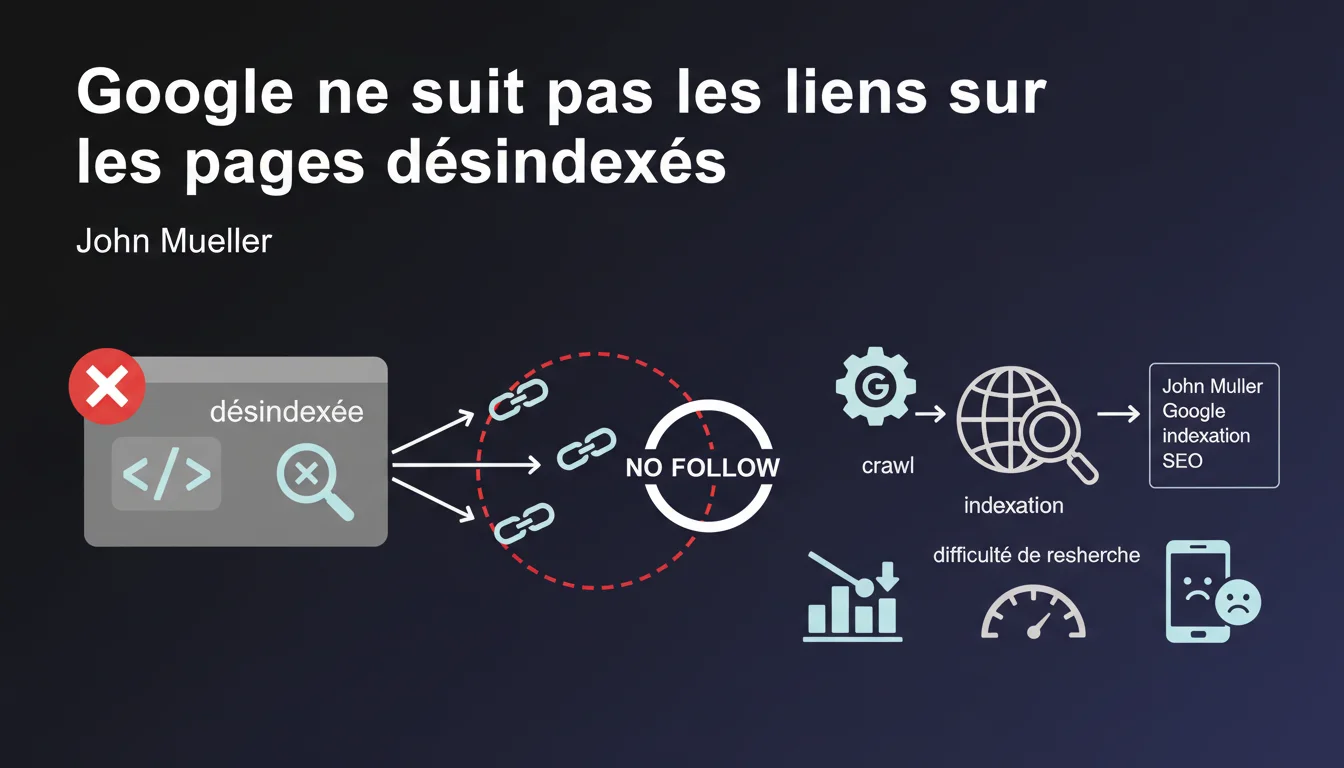
Cette déclaration de Google apporte une clarification majeure sur le comportement du crawler face aux pages désindexées. Lorsqu'une page est bloquée à l'indexation (via noindex ou robots.txt), Google considère que son contenu, y compris les liens qu'elle contient, n'est pas pertinent.
Concrètement, cela signifie que Google ne suivra pas les liens présents sur ces pages pour découvrir ou évaluer d'autres contenus. Cette logique s'applique aussi bien aux liens internes qu'externes, créant potentiellement des zones orphelines dans votre architecture.
Le commentaire éditorial ajoute une précision technique importante : l'utilisation conjointe de noindex et follow est inefficace. Même si vous tentez d'indiquer à Google de ne pas indexer une page mais de suivre ses liens, le moteur ignorera cette directive contradictoire.
- Les pages noindex ne transmettent pas leur jus de lien vers les pages qu'elles pointent
- Le crawl des liens est stoppé sur les pages désindexées, quelle que soit la directive follow
- Les pages uniquement liées depuis des pages noindex risquent de ne jamais être découvertes
- Cette règle s'applique uniformément aux liens internes et externes
Avis d'un expert SEO
Cette position de Google est parfaitement cohérente avec les observations terrain que nous effectuons depuis plusieurs années. De nombreux sites ont constaté une baisse de crawl et d'indexation de sections entières après avoir placé en noindex des pages hub ou de navigation.
La nuance importante à apporter concerne les méthodes alternatives de désindexation. Si vous utilisez robots.txt pour bloquer le crawl, Google ne verra même pas la page ni ses liens. Avec noindex, il crawle la page mais ignore tout son contenu, liens compris. Dans les deux cas, le résultat est similaire pour les liens.
Il existe toutefois des cas particuliers : les liens découverts via sitemaps XML, Search Console ou backlinks externes permettront à Google de contourner ce problème. Mais ne comptez pas sur cette découverte alternative comme stratégie principale.
Impact pratique et recommandations
- Auditez toutes vos pages en noindex pour identifier celles qui contiennent des liens vers des contenus importants
- Supprimez le noindex des pages hub (pagination, filtres, catégories) qui servent de pont vers des contenus stratégiques
- Créez des chemins de crawl alternatifs depuis des pages indexées vers vos contenus profonds actuellement orphelins
- Utilisez plutôt l'obfuscation JavaScript ou les paramètres URL pour les liens de navigation que vous ne voulez pas voir suivis
- Privilégiez la canonical plutôt que noindex pour gérer les contenus dupliqués tout en préservant le crawl des liens
- Vérifiez dans Search Console que vos pages stratégiques sont bien découvertes et crawlées régulièrement
- Documentez votre maillage interne pour identifier les dépendances critiques avant toute modification d'indexation
- Testez l'impact sur un échantillon avant de déployer des changements massifs de stratégie noindex
La gestion optimale du crawl et de l'indexation nécessite une compréhension fine de l'architecture technique et de ses implications sur la visibilité organique. Ces optimisations touchent au cœur même de la performance SEO et requièrent une approche méthodique et expérimentée. Pour les sites complexes ou à fort enjeu, l'accompagnement par une agence SEO spécialisée permet de cartographier précisément les flux de crawl, d'identifier les points de blocage et de mettre en place une stratégie d'indexation cohérente qui maximise la découvrabilité de vos contenus tout en préservant la qualité de votre index.
💬 Commentaires (0)
Soyez le premier à commenter.