Official statement
Other statements from this video 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
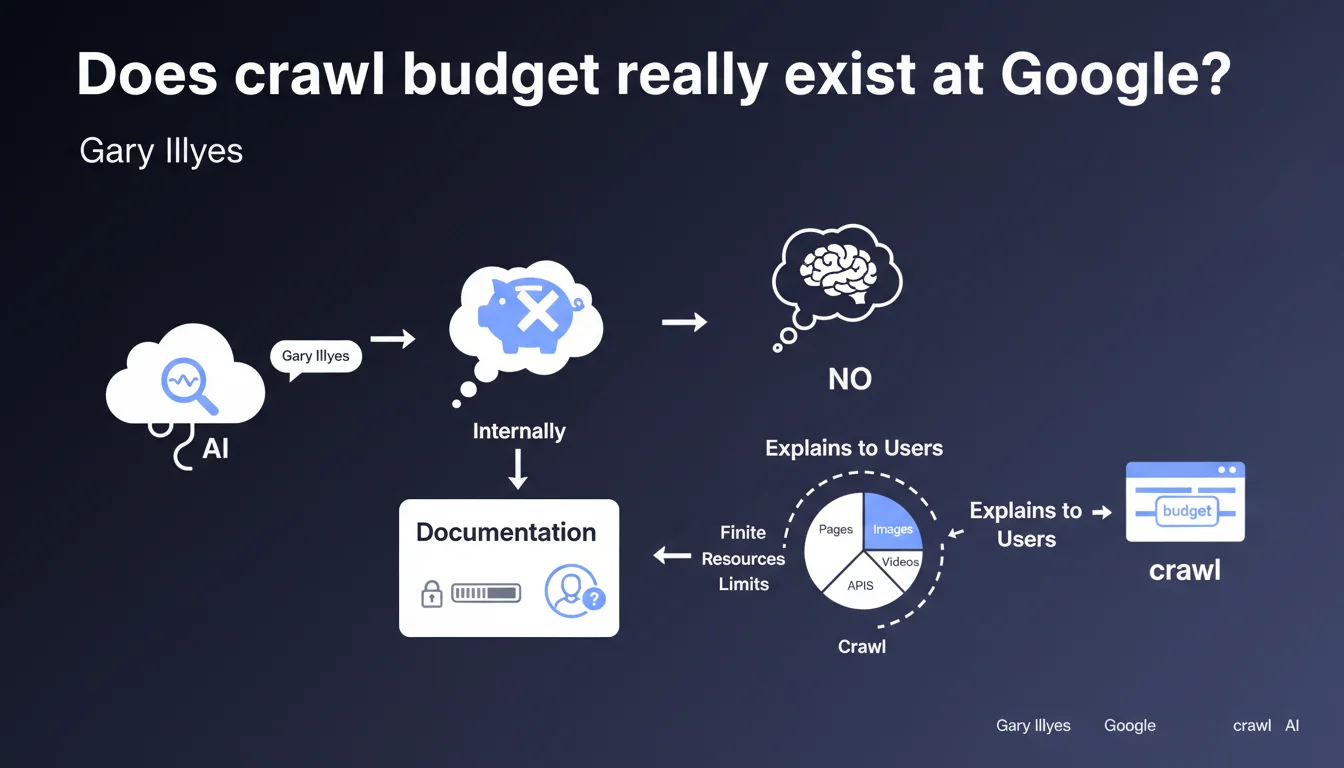
Gary Illyes claims that Google does not use the term "crawl budget" internally. This concept was invented for public documentation to explain to webmasters that crawl resources are limited. In reality, Google's technical teams think differently.
What you need to understand
Why did Google create a term it doesn't use internally?
Google designed the concept of crawl budget to simplify a complex mechanism for webmasters. The goal was to make people understand that there are physical limits to the number of pages a bot can explore on a given site.
Internally, Google's teams don't talk about "budget" — they use different technical terms to describe crawl prioritization algorithms, server constraints, and processing capacity. The formulation "crawl budget" was therefore an educational simplification, not a faithful translation of their technical jargon.
What does this mean in concrete terms for a website?
Even though Google doesn't think in terms of an "allocated budget", crawl limits definitely exist. A site with millions of useless URLs, repeated server errors, or chaotic architecture will see part of its pages ignored — not because it has "consumed its budget", but because the crawl algorithm prioritizes what seems important.
Prioritization signals include: page popularity (backlinks, traffic), content freshness, server performance, and perceived quality of the site. Google therefore allocates more resources to sites it deems important, but this allocation is not a fixed quota — it constantly fluctuates.
Does this statement call into question our SEO practices?
No. The essentials remain valid: making Googlebot's job easier improves indexation. Whether Google calls it "crawl budget", "resource allocation" or "algorithmic prioritization" doesn't change the practical approach.
What matters is understanding that Google doesn't distribute a fixed number of "crawl credits" per site. It adjusts in real time based on quality signals and technical constraints. A page can be crawled once a day or once a month depending on its perceived importance.
- The term "crawl budget" is an educational simplification, not an internal technical concept at Google
- Crawl limits exist, but they don't work like a fixed quota
- Google dynamically prioritizes pages based on quality and relevance signals
- SEO best practices remain identical: clean architecture, fresh content, server performance
- No need to panic about a "budget" — focus on crawl efficiency instead
SEO Expert opinion
Does this wording reflect a desire to minimize the problem?
Possibly. Gary Illyes specifies that the concept was "created for documentation", which suggests that Google may have regretted introducing this term. Since then, too many SEO consultants have turned it into an obsession, multiplying tools and dashboards to "optimize crawl budget" — when for 99% of sites, it's not a limiting factor.
This statement reads like a reminder: focus on content quality and logical architecture, not on metrics that only make sense for sites with millions of pages. Google may want to discourage a consulting industry that oversells this concept.
Do field observations contradict this vision?
Yes and no. On massive e-commerce sites or content aggregators, we do see certain sections being under-crawled for weeks. Server logs clearly show that Googlebot doesn't visit all URLs with the same frequency.
But calling it a "budget" is misleading. It's more of a matter of intelligent prioritization: Google detects duplicate pages, useless facets, infinite pagination, and intentionally ignores them. It's not an exhausted quota, it's an active filter. [To verify]: Google has never published a detailed study on its crawl prioritization algorithms.
Should we abandon the term "crawl budget" in our audits?
No, but we need to redefine it. Rather than talking about "budget consumed", we should talk about crawl efficiency. The goal isn't to "not waste credits", but to ensure that important URLs are discovered quickly and crawled frequently.
Practically speaking, this changes almost nothing about our recommendations: eliminate orphaned pages, block useless facets, optimize server response time, structure internal linking. The semantics change, the method remains.
Practical impact and recommendations
What concrete actions should we prioritize now?
Forget dashboards that display a pseudo "crawl budget remaining" — they measure nothing real. Instead, focus on the signals Google uses to prioritize: content freshness, page popularity, code quality, server performance.
Analyze your server logs to identify over-crawled sections (often useless) and under-crawled ones (sometimes strategic). If Googlebot visits 10,000 facet pages a day and 50 editorial content pages, you have a prioritization problem, not a "budget" problem.
- Audit server logs to identify inefficient crawl patterns
- Block via robots.txt or noindex low-value URLs: facets, filters, excessive pagination
- Optimize server response time — a slow site slows down Googlebot
- Strengthen internal linking to strategic pages to increase their crawl frequency
- Publish fresh content regularly on important sections to maintain Googlebot's interest
- Monitor 5xx errors in Search Console — they drive the bot away
- Avoid redirect chains that slow down crawling
How do we measure if these optimizations work?
Track the evolution of crawl frequency in Search Console ("Crawl statistics" section). A gradual increase signals that Google considers your site more important or better structured.
Also compare the indexation rate: number of indexed pages vs number of submitted pages. If the gap shrinks, it means Google is exploring your content more efficiently.
When should we really worry about crawl?
If your site has fewer than 10,000 pages, crawl is probably not your problem. Google easily crawls this volume, even for modest sites.
However, for massive e-commerce sites, marketplaces, or content aggregators, crawl optimization becomes strategic. There, each architectural decision (facets, filters, pagination) has a direct impact on indexation.
Crawl optimization remains essential, especially for high-volume sites. However, these interventions require specialized technical expertise: server log analysis, robots.txt management, fine-tuning of internal linking, continuous monitoring.
If you manage a complex site and notice indexation issues, it may be wise to get support from a specialized SEO agency that masters these technical aspects. A personalized approach, based on your actual data, will always be more effective than a generic recipe.
❓ Frequently Asked Questions
Google utilise-t-il un quota fixe de pages crawlées par site ?
Le terme crawl budget est-il obsolète ?
Dois-je encore optimiser le crawl de mon site ?
Quels sites doivent vraiment se préoccuper du crawl ?
Comment savoir si Google crawle efficacement mon site ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 14/03/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.