Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
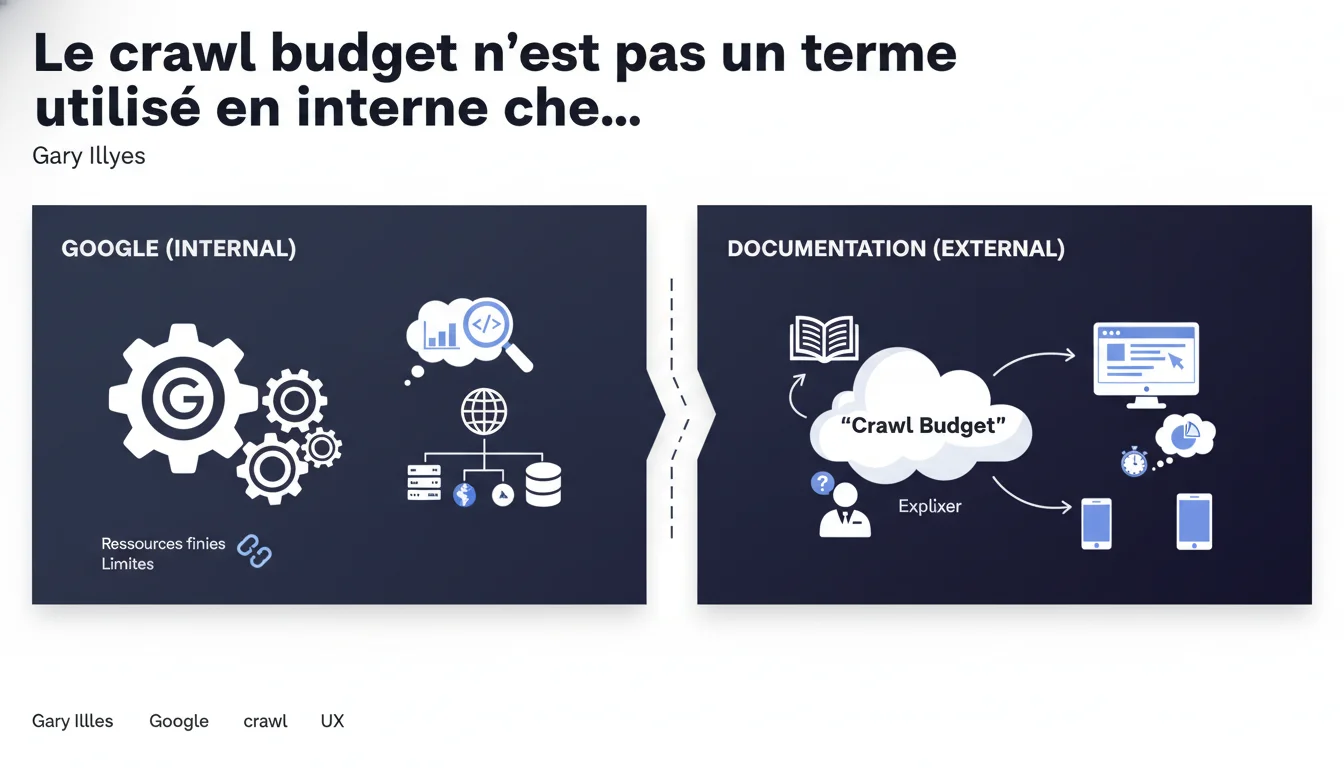
Gary Illyes affirme que Google n'utilise pas le terme "crawl budget" en interne. Ce concept a été inventé pour la documentation publique afin d'expliquer aux webmasters que les ressources de crawl sont limitées. En réalité, les équipes techniques de Google raisonnent différemment.
Ce qu'il faut comprendre
Pourquoi Google a-t-il créé un terme qu'il n'utilise pas en interne ?
Google a conçu le concept de crawl budget pour vulgariser un mécanisme complexe auprès des webmasters. L'objectif était de faire comprendre qu'il existe des limites physiques au nombre de pages qu'un robot peut explorer sur un site donné.
En interne, les équipes de Google ne parlent pas de "budget" — elles utilisent des termes techniques différents pour décrire les algorithmes de priorisation du crawl, les contraintes serveur et la capacité de traitement. La formulation "crawl budget" était donc une simplification pédagogique, pas une traduction fidèle de leur jargon technique.
Qu'est-ce que cela signifie concrètement pour un site web ?
Même si Google ne pense pas en termes de "budget alloué", les limites de crawl existent bel et bien. Un site avec des millions d'URLs inutiles, des erreurs serveur à répétition ou une architecture chaotique verra une partie de ses pages ignorées — non pas parce qu'il a "consommé son budget", mais parce que l'algorithme de crawl priorise ce qui semble important.
Les signaux de priorisation incluent : la popularité des pages (backlinks, trafic), la fraîcheur du contenu, la performance serveur, et la qualité perçue du site. Google alloue donc plus de ressources aux sites qu'il juge importants, mais cette allocation n'est pas un quota fixe — elle fluctue constamment.
Cette déclaration remet-elle en question nos pratiques SEO ?
Non. L'essentiel reste valable : faciliter le travail de Googlebot améliore l'indexation. Que Google appelle ça "crawl budget", "allocation de ressources" ou "priorisation algorithmique" ne change rien à l'approche pratique.
Ce qui compte, c'est de comprendre que Google ne distribue pas un nombre fixe de "crédits crawl" par site. Il ajuste en temps réel selon les signaux de qualité et les contraintes techniques. Une page peut être crawlée une fois par jour ou une fois par mois selon son importance perçue.
- Le terme "crawl budget" est une simplification pédagogique, pas un concept technique interne chez Google
- Les limites de crawl existent, mais elles ne fonctionnent pas comme un quota fixe
- Google priorise dynamiquement les pages selon des signaux de qualité et de pertinence
- Les bonnes pratiques SEO restent identiques : architecture propre, contenu frais, performance serveur
- Inutile de paniquer sur un "budget" — il faut optimiser pour l'efficacité du crawl
Avis d'un expert SEO
Cette formulation traduit-elle une volonté de minimiser le problème ?
Possible. Gary Illyes précise que le concept a été "créé pour la documentation", ce qui suggère que Google a peut-être regretté d'introduire ce terme. Depuis, trop de consultants SEO en ont fait une obsession, multipliant les outils et dashboards pour "optimiser le crawl budget" — alors que pour 99% des sites, ce n'est pas un facteur limitant.
Cette déclaration ressemble à un rappel : concentrez-vous sur la qualité du contenu et l'architecture logique, pas sur des métriques qui n'ont de sens que pour les sites à plusieurs millions de pages. Google veut peut-être décourager une industrie du conseil qui survend ce concept.
Les observations terrain contredisent-elles cette vision ?
Oui et non. Sur des sites e-commerce massifs ou des agrégateurs de contenu, on constate bien que certaines sections sont sous-crawlées pendant des semaines. Les logs serveur montrent clairement que Googlebot ne visite pas toutes les URLs avec la même fréquence.
Mais qualifier ça de "budget" est trompeur. C'est davantage une question de priorisation intelligente : Google détecte les pages dupliquées, les facettes inutiles, les paginations infinies, et les ignore volontairement. Ce n'est pas un quota épuisé, c'est un filtre actif. [A vérifier] : Google n'a jamais publié d'étude détaillée sur ses algorithmes de priorisation du crawl.
Faut-il abandonner le terme "crawl budget" dans nos audits ?
Non, mais il faut le redéfinir. Plutôt que de parler de "budget consommé", on devrait parler d'efficacité du crawl. L'objectif n'est pas de "ne pas gaspiller des crédits", mais de faire en sorte que les URLs importantes soient découvertes rapidement et crawlées fréquemment.
Concrètement, ça ne change presque rien à nos recommandations : éliminer les pages orphelines, bloquer les facettes inutiles, optimiser le temps de réponse serveur, structurer le maillage interne. La sémantique change, la méthode reste.
Impact pratique et recommandations
Quelles actions concrètes faut-il prioriser maintenant ?
Oubliez les dashboards qui affichent un pseudo "crawl budget restant" — ils ne mesurent rien de réel. Concentrez-vous plutôt sur les signaux que Google utilise pour prioriser : fraîcheur du contenu, popularité des pages, qualité du code, performance serveur.
Analysez vos logs serveur pour identifier les sections sur-crawlées (souvent inutiles) et sous-crawlées (parfois stratégiques). Si Googlebot visite 10 000 pages de facettes par jour et 50 pages de contenu éditorial, vous avez un problème de hiérarchisation, pas de "budget".
- Auditez les logs serveur pour identifier les patterns de crawl inefficaces
- Bloquez via robots.txt ou noindex les URLs à faible valeur : facettes, filtres, paginations excessives
- Optimisez le temps de réponse serveur — un site lent ralentit Googlebot
- Renforcez le maillage interne vers les pages stratégiques pour augmenter leur fréquence de crawl
- Publiez régulièrement du contenu frais sur les sections importantes pour maintenir l'intérêt de Googlebot
- Surveillez les erreurs 5xx dans la Search Console — elles font fuir le robot
- Évitez les chaînes de redirections qui ralentissent l'exploration
Comment mesurer si ces optimisations fonctionnent ?
Suivez l'évolution de la fréquence de crawl dans la Search Console (section "Statistiques sur l'exploration"). Une hausse progressive signale que Google juge votre site plus important ou mieux structuré.
Comparez également le taux d'indexation : nombre de pages indexées vs nombre de pages soumises. Si l'écart se réduit, c'est que Google explore plus efficacement votre contenu.
Quand faut-il s'inquiéter réellement du crawl ?
Si votre site compte moins de 10 000 pages, le crawl n'est probablement pas votre problème. Google crawle facilement cette volumétrie, même pour des sites modestes.
En revanche, pour les sites e-commerce massifs, les marketplaces ou les agrégateurs de contenu, l'optimisation du crawl devient stratégique. Là, chaque décision d'architecture (facettes, filtres, paginations) a un impact direct sur l'indexation.
L'optimisation du crawl reste essentielle, surtout pour les sites à forte volumétrie. Toutefois, ces interventions requièrent une expertise technique pointue : analyse des logs serveur, gestion du robots.txt, ajustements fins du maillage interne, monitoring continu.
Si vous gérez un site complexe et constatez des problèmes d'indexation, il peut être judicieux de vous faire accompagner par une agence SEO spécialisée qui maîtrise ces aspects techniques. Une approche personnalisée, basée sur vos données réelles, sera toujours plus efficace qu'une recette générique.
❓ Questions frequentes
Google utilise-t-il un quota fixe de pages crawlées par site ?
Le terme crawl budget est-il obsolète ?
Dois-je encore optimiser le crawl de mon site ?
Quels sites doivent vraiment se préoccuper du crawl ?
Comment savoir si Google crawle efficacement mon site ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 14/03/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.