Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
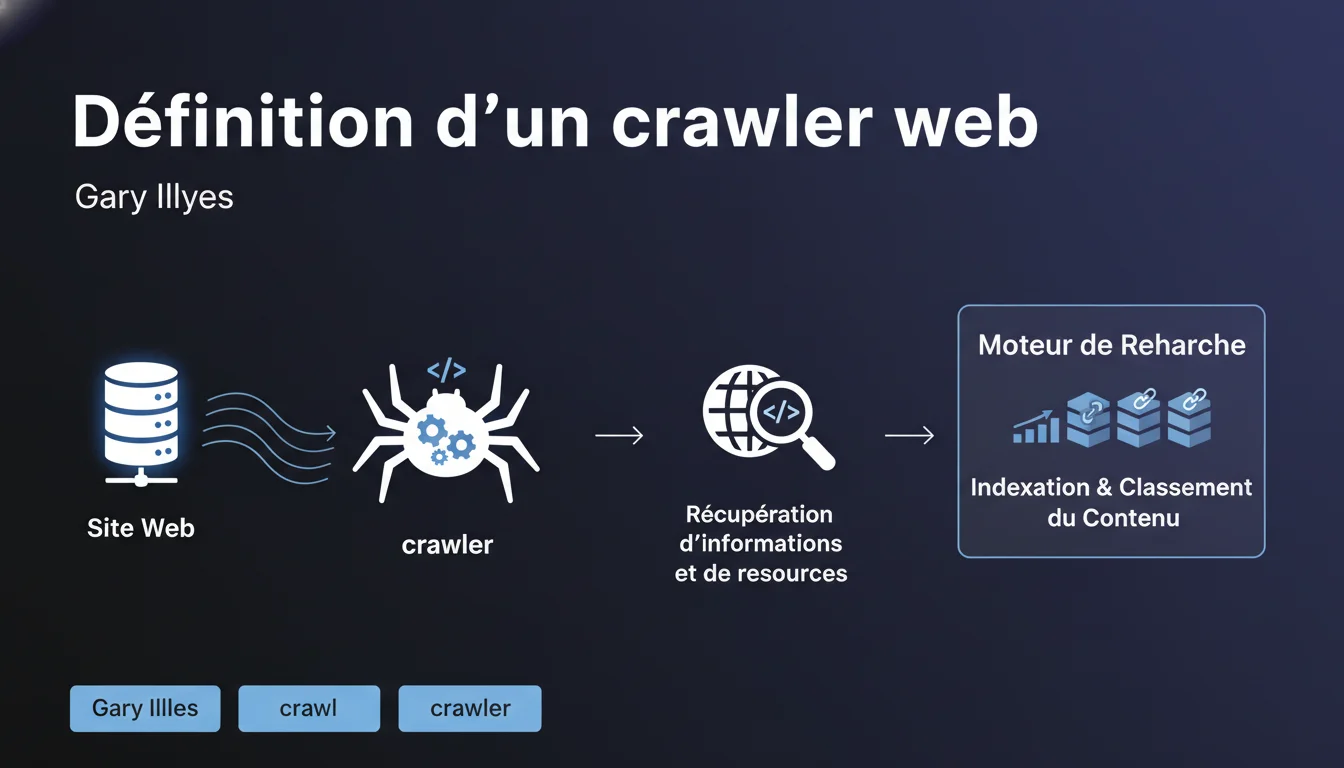
Gary Illyes rappelle qu'un crawler est un logiciel récupérant informations et ressources depuis les sites web. Sans crawler, pas d'indexation ni de classement possible — c'est la porte d'entrée obligatoire de tout moteur de recherche. Cette définition pose les bases d'une évidence souvent négligée : si Googlebot ne peut pas crawler, votre contenu n'existe pas.
Ce qu'il faut comprendre
Pourquoi Google publie-t-il une définition aussi basique ?
Cette déclaration peut sembler triviale pour un professionnel aguerri. Pourtant, elle ancre un principe fondamental : le crawl précède tout. Pas de récupération, pas d'indexation, pas de ranking.
Google réaffirme ici que le crawler est l'étape zéro de la visibilité organique. Beaucoup de sites optimisent leur contenu, leurs balises, leur vitesse — mais oublient que si Googlebot ne peut pas accéder aux ressources, rien ne se passe. C'est un rappel à l'ordre : le crawl n'est pas un détail technique, c'est la condition sine qua non.
Que signifie concrètement « récupérer des informations et des ressources » ?
Un crawler ne se contente pas de lire du texte HTML. Il récupère aussi les images, les fichiers JavaScript, les feuilles de style CSS, les vidéos, les PDFs — bref, tout ce qui compose une page moderne.
Cette récupération est conditionnée par plusieurs facteurs : accessibilité technique (serveur disponible, réponse HTTP correcte), autorisations (robots.txt, balises meta), et budget de crawl. Si une ressource est bloquée ou inaccessible, elle ne sera ni analysée ni indexée.
Quelle différence entre crawler et indexer ?
Le crawl est la phase de collecte. L'indexation est la phase d'analyse et de stockage. Un crawler peut visiter une page sans que celle-ci soit indexée — c'est même fréquent.
Google peut crawler une URL mais décider de ne pas l'indexer si elle est jugée de faible qualité, dupliquée, ou bloquée par une directive noindex. Le crawl est donc nécessaire mais pas suffisant.
- Le crawler récupère les données brutes depuis le serveur
- L'indexation traite, analyse et stocke ces données dans l'index de Google
- Le classement intervient ensuite, basé sur des centaines de signaux de ranking
- Bloquer le crawl bloque tout le processus en amont
- Autoriser le crawl ne garantit pas l'indexation
Avis d'un expert SEO
Cette définition est-elle complète ou volontairement simplifiée ?
Soyons honnêtes : cette déclaration est pédagogique, pas technique. Elle cible un public large, probablement des débutants ou des décideurs non techniques. Pour un praticien SEO, elle n'apporte rien de nouveau.
Ce qui manque, c'est la nuance. Un crawler moderne ne « va » pas simplement récupérer du contenu — il priorise, filtre, respecte des règles, et adapte sa fréquence selon des centaines de paramètres. Cette définition édulcorée omet toute la complexité du crawl budget, des directives conditionnelles, ou du rendu JavaScript différé.
Observe-t-on des incohérences entre cette déclaration et la réalité terrain ?
Non, mais elle cache certaines réalités. Par exemple, Google ne crawle pas tout, tout le temps. Il existe des pages orphelines que Googlebot découvre par accident, des ressources jamais visitées faute de liens entrants, et des sites entiers ignorés si le crawl budget est épuisé ailleurs.
De plus, certains contenus sont crawlés mais jamais rendus correctement — notamment ceux nécessitant une exécution JavaScript complexe ou des authentifications. La définition de Gary Illyes suggère un processus linéaire et exhaustif. La réalité est bien plus aléatoire.
Quelles sont les limites non dites de cette affirmation ?
Google ne précise pas que tous les crawlers ne se valent pas. Googlebot Desktop, Googlebot Mobile, Googlebot Image, AdsBot — chacun a ses spécificités, ses priorités, et ses contraintes. Dire « un crawler récupère du contenu » masque cette diversité.
Autre point : le crawl n'est pas instantané. Entre la publication d'un contenu et son crawl effectif, il peut s'écouler des heures, jours, voire semaines selon l'autorité du site, sa fraîcheur perçue, et la profondeur de l'URL. [À vérifier] : Google n'a jamais communiqué publiquement de délai moyen de crawl par typologie de site.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl ?
Commencez par auditer l'accessibilité technique de vos pages stratégiques. Vérifiez que votre fichier robots.txt n'exclut pas involontairement des sections importantes, et que vos balises meta robots sont cohérentes avec vos objectifs d'indexation.
Ensuite, analysez votre maillage interne. Les pages orphelines — celles sans liens entrants internes — sont rarement crawlées. Assurez-vous que chaque contenu important est lié depuis au moins une page déjà indexée, idéalement depuis la page d'accueil ou une catégorie de premier niveau.
Enfin, surveillez votre budget de crawl. Si Google crawle massivement des pages inutiles (archives paginées, filtres à facettes, sessions URL), il gaspille du budget au détriment de vos contenus stratégiques. Utilisez la Search Console pour identifier les URLs crawlées et corrigez les anomalies.
Quelles erreurs éviter absolument ?
Ne bloquez jamais les ressources critiques (CSS, JavaScript) dans robots.txt si elles sont nécessaires au rendu de la page. Google a besoin de ces fichiers pour comprendre le contenu et l'ergonomie mobile.
Évitez les redirections en chaîne et les boucles infinies, qui épuisent le budget de crawl et ralentissent la découverte de nouveaux contenus. Chaque redirection consomme une requête, et au-delà de 3-4 sauts, Googlebot peut abandonner.
Ne négligez pas les temps de réponse serveur. Si votre site est lent, Googlebot ralentit automatiquement son rythme de crawl pour ne pas surcharger votre infrastructure. Un serveur performant favorise un crawl plus fréquent et plus profond.
- Auditez votre fichier robots.txt et vos balises meta robots
- Identifiez et corrigez les pages orphelines via un crawl interne
- Supprimez les redirections inutiles et les chaînes de redirections
- Optimisez la vitesse serveur (TTFB, réponse HTTP rapide)
- Surveillez les logs serveur pour repérer les anomalies de crawl
- Utilisez un sitemap XML à jour pour guider Googlebot vers vos priorités
- Limitez le crawl des pages à faible valeur (filtres, archives, sessions)
Comment vérifier que Google crawle efficacement votre site ?
Consultez régulièrement la Search Console, section « Statistiques d'exploration ». Vous y trouverez le nombre de pages crawlées par jour, les erreurs de crawl, et les temps de réponse moyens. Une baisse brutale du crawl peut signaler un problème technique.
Analysez vos logs serveur pour croiser les données Search Console avec la réalité terrain. Vous identifierez ainsi les URLs crawlées mais non indexées, les ressources bloquées, et les bots suspects. C'est le meilleur moyen d'objectiver votre stratégie de crawl.
❓ Questions frequentes
Un crawler peut-il indexer une page qu'il n'a pas crawlée ?
Pourquoi certaines pages sont-elles crawlées mais jamais indexées ?
Le crawl budget affecte-t-il tous les sites de la même manière ?
Faut-il bloquer les crawlers autres que Googlebot ?
Un sitemap XML accélère-t-il le crawl de nouvelles pages ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 14/03/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.