Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
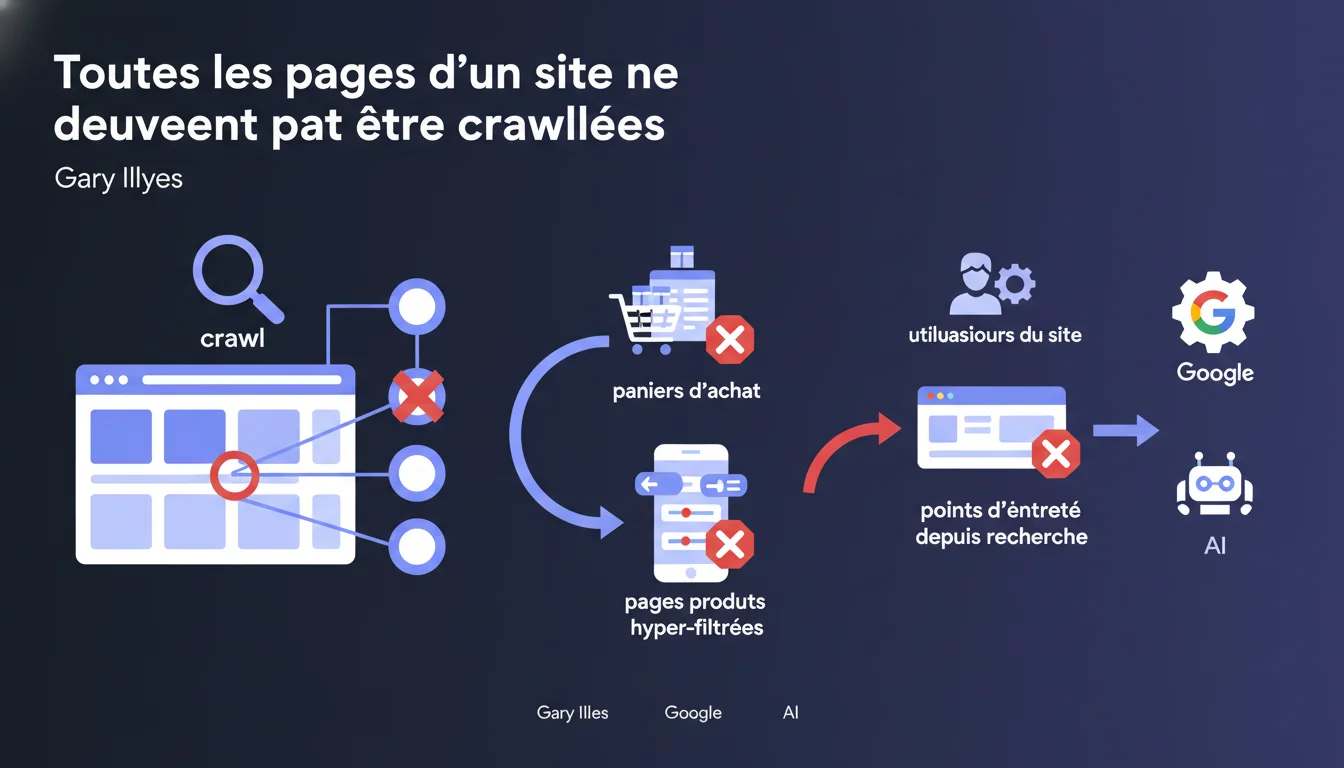
Google affirme clairement que toutes les pages d'un site ne devraient pas être crawlées. Les pages sans valeur comme points d'entrée — paniers, facettes hyper-filtrées, résultats de recherche interne — consomment du crawl budget inutilement. L'enjeu : prioriser les ressources de crawl sur les pages qui convertissent vraiment depuis la recherche.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur cette distinction entre pages utiles et pages superflues ?
Google dispose de ressources de crawl limitées pour chaque site. Plus un site est volumineux, plus ce budget se dilue. Si Googlebot passe du temps sur des pages qui n'apportent aucune valeur dans les SERP, il en consacre moins aux contenus stratégiques.
La nuance cruciale : une page peut être utile pour l'utilisateur déjà sur le site (panier, filtre ultra-spécifique) sans pour autant mériter d'apparaître dans les résultats de recherche. Ces pages existent pour fluidifier le parcours utilisateur, pas pour ranker.
Quelles pages sont typiquement concernées par cette exclusion ?
Gary Illyes cite deux exemples concrets : les paniers d'achat et les pages hyper-filtrées. Mais le principe s'étend à toute page générée dynamiquement sans intent de recherche correspondant.
Concrètement : les pages de résultats de recherche interne, les URLs de session, les variations infinies de tri ou de filtres combinés, les pages de connexion, les pages de remerciement post-achat. Toutes ces URLs consomment du crawl sans apporter de trafic qualifié.
Cette approche contredit-elle la logique d'indexation maximale ?
Oui, et c'est assumé. L'époque où « plus d'URLs indexées = mieux » est révolue. Google privilégie désormais la qualité sur la quantité. Un site avec 10 000 pages indexées dont 8 000 sans valeur SEO performe moins bien qu'un site de 2 000 pages ciblées.
Cette position s'inscrit dans la logique du crawl budget optimization et du quality rater guidelines. Google veut indexer ce qui sert l'utilisateur cherchant une réponse, pas tout ce qui existe techniquement.
- Le crawl budget n'est pas infini, même pour les gros sites
- Une page utile en navigation n'est pas forcément pertinente comme point d'entrée depuis Google
- Les URLs de facettes combinées explosent le volume crawlé sans ROI
- Bloquer stratégiquement certaines pages améliore la distribution du crawl sur les contenus rentables
- Google valorise les sites qui facilitent son travail en signalant ce qui compte vraiment
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. Les audits de crawl sur des sites e-commerce ou à forte dimension UGC montrent systématiquement que 60 à 80% des URLs crawlées n'apportent aucun trafic organique. Les logs servers le confirment : Googlebot passe un temps démesuré sur des pages de filtre redondantes ou des URLs paramétrées.
Les sites qui ont appliqué une stratégie stricte de robots.txt ou de noindex sur ces pages annexes constatent — sous réserve d'une implémentation propre — une revalorisation du crawl sur les pages stratégiques et souvent une amélioration des performances globales dans les 4 à 8 semaines.
Quelles nuances faut-il apporter à cette recommandation ?
Premier piège : confondre « ne pas crawler » et « ne pas indexer ». Ce n'est pas la même chose. Une page peut être crawlée sans être indexée (noindex), ou bloquée au crawl via robots.txt. Le choix entre les deux a des conséquences différentes sur la transmission de PageRank et la découverte de liens.
Deuxième nuance — et Google reste volontairement flou là-dessus : où placer le curseur sur les facettes ? Une page filtrée par 1 critère peut avoir un intent réel (« chaussures de running femme »). Avec 4 filtres combinés (« chaussures running femme taille 38 bleues en promo »), l'intent devient microscopique. [À vérifier] : Google ne donne aucune métrique claire pour tracer la ligne.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Sur les sites à faible volume de pages (moins de 500-1000 URLs), le crawl budget n'est généralement pas un facteur limitant. Bloquer des pages devient contre-productif si cela complexifie inutilement l'architecture.
Autre exception : les pages de résultats de recherche interne peuvent, dans certains contextes, capter un trafic long-tail intéressant. Certains sites média ou marketplaces laissent volontairement indexer ces pages — mais c'est un pari risqué qui demande une surveillance constante du ratio crawl/valeur.
Impact pratique et recommandations
Que faut-il faire concrètement pour appliquer cette recommandation ?
Première étape : auditer les logs serveur sur au minimum 30 jours pour identifier quelles URLs sont crawlées et avec quelle fréquence. Croiser ces données avec les performances GA4 ou équivalent : quelles URLs génèrent du trafic organique, quelles URLs sont crawlées mais inutiles ?
Ensuite, segmenter les URLs en trois catégories : pages stratégiques (à crawler absolument), pages secondaires (utiles mais pas prioritaires), pages sans valeur SEO (à bloquer ou noindexer). Cette segmentation doit reposer sur des données, pas sur des intuitions.
Quelles erreurs éviter dans cette démarche ?
Erreur classique : bloquer via robots.txt des pages qui reçoivent des backlinks. Robots.txt empêche la transmission de PageRank. Si une page inutile reçoit des liens externes, mieux vaut la noindexer tout en laissant le crawl passer pour que le jus remonte.
Autre piège : appliquer un noindex massif sur des facettes sans vérifier l'impact sur le maillage interne. Si ces pages servaient de hub de liens vers des produits, leur disparition de l'index peut isoler des contenus stratégiques. Toujours simuler l'impact sur le graphe de liens avant de déployer.
Comment vérifier que mon site respecte cette logique ?
Utilise la Search Console pour monitorer le taux de crawl vs taux d'indexation. Si Google crawle 10 000 URLs par jour mais n'en indexe que 2 000, c'est un signal clair que du crawl est gaspillé. Creuse dans les rapports de couverture pour identifier les patterns d'URLs superflues.
Parallèlement, observe l'évolution du crawl après chaque ajustement de robots.txt ou noindex. Un bon indicateur : le nombre de pages crawlées par jour devrait se stabiliser ou diminuer tandis que les pages stratégiques voient leur fréquence de crawl augmenter.
- Analyser 30+ jours de logs serveur pour cartographier le crawl réel
- Identifier les URLs crawlées mais sans trafic organique (rapport Search Console + GA4)
- Segmenter les pages : stratégiques / secondaires / à bloquer
- Vérifier les backlinks avant de bloquer une URL via robots.txt
- Privilégier le noindex pour les pages avec liens entrants
- Simuler l'impact sur le maillage interne avant déploiement massif
- Monitorer l'évolution du crawl dans Search Console post-implémentation
- Documenter chaque décision de blocage pour faciliter les audits futurs
❓ Questions frequentes
Dois-je bloquer les pages de panier via robots.txt ou noindex ?
Comment savoir si mon crawl budget est un problème ?
Les facettes de filtres doivent-elles toutes être bloquées ?
Peut-on récupérer du crawl budget rapidement après optimisation ?
Le crawl budget impacte-t-il vraiment le ranking ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 14/03/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.