Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
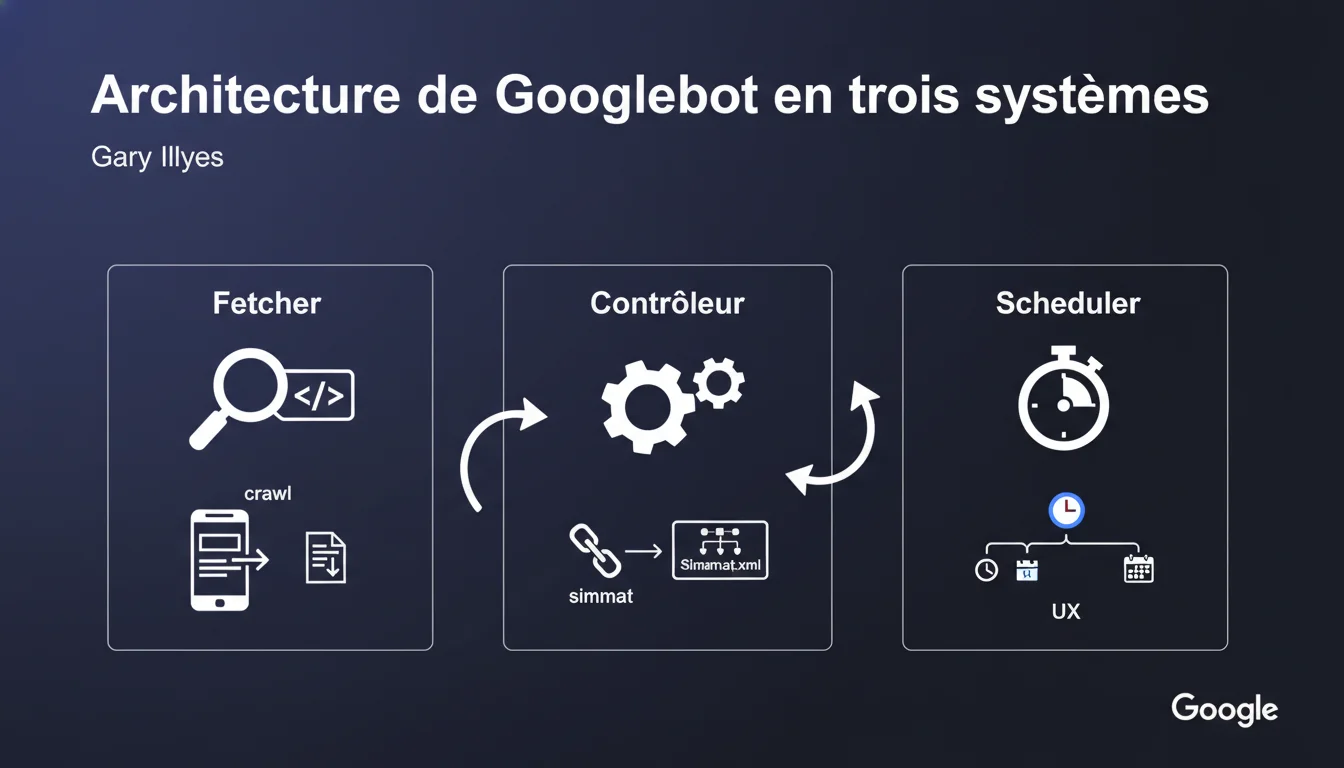
Googlebot repose sur trois systèmes distincts : un fetcher qui télécharge les pages, un contrôleur qui centralise tous les liens découverts (HTML + sitemaps), et un scheduler qui décide du timing de crawl. Cette architecture modulaire impacte directement votre stratégie de crawl budget et d'optimisation technique.
Ce qu'il faut comprendre
Pourquoi Google détaille-t-il l'architecture interne de son crawler ?
Gary Illyes lève le voile sur la structure technique de Googlebot pour aider les professionnels SEO à mieux comprendre les mécanismes de découverte et priorisation des URLs. Cette transparence rare permet d'optimiser plus finement l'architecture technique de vos sites.
Savoir que Googlebot sépare la récupération (fetcher), la centralisation des liens (contrôleur) et la planification (scheduler) change la donne. Chaque système a son rôle — et ses limites.
Que fait exactement chacun de ces trois composants ?
Le fetcher est le bras armé : il télécharge le HTML, exécute le JavaScript si nécessaire, récupère les ressources. C'est lui qui consomme votre bande passante et sollicite vos serveurs.
Le contrôleur agrège tous les liens découverts — qu'ils viennent du HTML crawlé ou des sitemaps XML. Il fusionne ces sources pour construire une file d'attente unique. Point crucial : les sitemaps ne contournent pas le système, ils alimentent le même pool de décision.
Le scheduler orchestre quand et à quelle fréquence crawler chaque URL. Il tient compte du crawl budget, de la fraîcheur des contenus, de la popularité des pages. C'est le cerveau qui décide des priorités.
Quelles sont les implications pour le crawl budget ?
Cette architecture modulaire signifie que tous les signaux convergent vers le scheduler. Multiplier les sources de découverte (liens internes + sitemaps + liens externes) ne garantit pas un crawl plus rapide si le scheduler estime la page non prioritaire.
Le crawl budget dépend donc moins du nombre de fois où Googlebot « voit » une URL que de la qualité des signaux qui l'accompagnent : popularité, fraîcheur, profondeur dans l'arborescence.
- Le fetcher télécharge les pages et sollicite vos serveurs
- Le contrôleur centralise tous les liens découverts (HTML + sitemaps)
- Le scheduler décide du timing de crawl selon les priorités
- Les sitemaps alimentent le même système que les liens HTML — pas de passe-droit
- Optimiser le crawl = influencer les décisions du scheduler, pas saturer le contrôleur
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, globalement. On observe depuis longtemps que soumettre une URL en sitemap ne force pas un crawl immédiat — ce qui confirme que le contrôleur fusionne simplement les sources sans priorité automatique. Le scheduler reste maître du jeu.
Par contre, Google reste évasif sur les critères exacts du scheduler : quels poids pour la popularité, la fraîcheur, la profondeur ? Ces variables sont nébuleuses. [À vérifier] : impossible de savoir si un lien interne depuis la home pèse plus qu'une mention en sitemap dans le calcul de priorité.
Quelles nuances faut-il apporter ?
Google simplifie probablement. En réalité, Googlebot a plusieurs fetchers spécialisés (mobile, desktop, AdsBot, Googlebot Images…). Parler d'« un » fetcher est réducteur — chaque bot a ses spécificités techniques et sa file de priorité.
Autre point : cette architecture concerne le crawl initial, mais qu'en est-il du re-crawl ? Le scheduler traite-t-il différemment une URL déjà connue vs. une nouvelle découverte ? La déclaration ne le précise pas. [À vérifier] sur des sites à forte vélocité éditoriale.
Dans quels cas cette architecture montre-t-elle ses limites ?
Sur les très gros sites (e-commerce, petites annonces), le contrôleur peut recevoir des millions d'URLs. Le scheduler doit alors arbitrer drastiquement — et certaines pages légitimes peuvent rester hors radar pendant des semaines.
Autre cas : les sites avec JavaScript client-side lourd. Le fetcher doit rendre la page, ce qui ralentit tout. Si le scheduler détecte un coût de crawl élevé, il réduira la fréquence — cercle vicieux.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser chacun de ces trois systèmes ?
Pour le fetcher : Réduisez le temps de réponse serveur et facilitez le rendu. Limitez les redirections, compressez les ressources, évitez le JavaScript superflu. Moins le fetcher peine, plus il crawle d'URLs.
Pour le contrôleur : Assurez-vous que vos URLs stratégiques sont découvertes via plusieurs canaux — liens internes depuis des pages fortes ET sitemaps XML. Ne comptez pas sur un seul vecteur.
Pour le scheduler : Envoyez des signaux de priorité. Liens internes depuis la home ou des pages populaires, mises à jour fréquentes du contenu, mentions externes. Le scheduler adore les pages « vivantes ».
Quelles erreurs éviter absolument ?
Ne saturez pas le contrôleur avec des millions d'URLs inutiles (facettes, filtres, paramètres). Vous diluez les signaux et noyez vos pages stratégiques. Le scheduler risque de baisser la priorité globale de votre domaine.
Autre erreur : croire que soumettre 50 000 URLs en sitemap forcera un crawl massif. Le scheduler ne crawlera que ce qu'il juge prioritaire — le reste attendra. Mieux vaut un sitemap de 5 000 URLs stratégiques qu'un fourre-tout de 100 000.
Comment vérifier que votre site est bien optimisé pour cette architecture ?
Analysez les logs serveur pour repérer les patterns de crawl : Googlebot revient-t-il régulièrement sur vos pages clés ? Ignore-t-il des sections entières ? Crawle-t-il des URLs inutiles en boucle ?
Comparez les URLs soumises en sitemap avec celles effectivement crawlées (Search Console > Couverture). Si un écart énorme persiste, le scheduler juge vos URLs non prioritaires — creusez pourquoi.
- Optimisez le temps de réponse serveur pour faciliter le travail du fetcher
- Centralisez vos URLs stratégiques dans un sitemap propre (pas de fourre-tout)
- Renforcez le maillage interne depuis les pages à fort PageRank interne
- Surveillez les logs serveur pour identifier les priorités réelles du scheduler
- Éliminez les URLs inutiles (facettes, doublons) pour ne pas diluer les signaux
- Mettez à jour régulièrement vos contenus clés pour signaler la fraîcheur
❓ Questions frequentes
Les sitemaps XML ont-ils une priorité supérieure aux liens internes pour Googlebot ?
Peut-on forcer Googlebot à crawler une page en la soumettant plusieurs fois ?
Comment le scheduler décide-t-il quelles pages crawler en priorité ?
Le fetcher de Googlebot exécute-t-il systématiquement le JavaScript ?
Un site lent est-il pénalisé par le scheduler de Googlebot ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 14/03/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.