Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
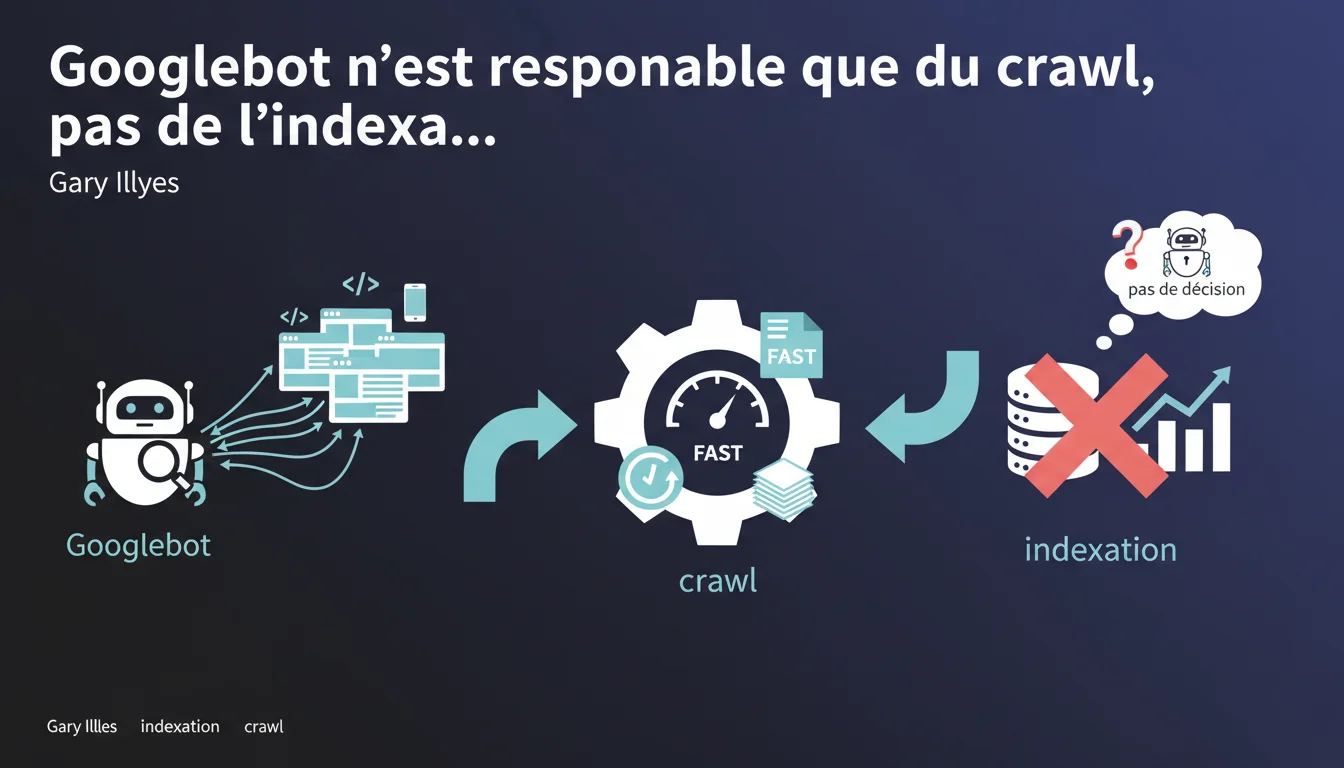
Gary Illyes affirme que Googlebot se contente de récupérer les pages sans prendre la moindre décision d'indexation. Cette séparation stricte entre crawl et indexation signifie qu'optimiser le crawl ne garantit en rien qu'une page sera indexée. Il faut comprendre que d'autres systèmes prennent le relais après Googlebot.
Ce qu'il faut comprendre
Cette déclaration de Gary Illyes sépare formellement deux étapes du pipeline Google : le crawl et l'indexation. Googlebot récupère le contenu, point final. Les décisions d'indexation relèvent d'autres composants de l'infrastructure.
Cette distinction bouleverse certaines idées reçues — notamment l'illusion qu'optimiser le crawl suffit à garantir l'indexation. Soyons honnêtes : beaucoup de sites bien crawlés ne sont pas indexés pour autant.
Quelle est la différence concrète entre crawl et indexation ?
Le crawl est la simple récupération du contenu par Googlebot. Il parcourt les URL, récupère le HTML, les ressources, exécute le JavaScript si besoin. Rien de plus.
L'indexation, c'est l'analyse du contenu récupéré, son traitement, son stockage dans l'index et la décision de le rendre accessible ou non dans les résultats. Cette étape dépend de nombreux critères : qualité, duplication, pertinence, canonicalisation, directives robots, etc.
Pourquoi Google insiste-t-il autant sur cette séparation ?
Parce que trop de SEO confondent encore crawlabilité et indexabilité. Un site peut être parfaitement crawlable — fichier robots.txt propre, sitemap impeccable, maillage interne au cordeau — et pourtant voir ses pages refusées à l'indexation.
Google veut clarifier que les problèmes d'indexation ne relèvent pas de Googlebot. Si vos pages ne sont pas indexées, cherchez du côté des critères de qualité, de la canonicalisation, des signaux E-E-A-T, de la duplication, etc.
Quels sont les systèmes qui décident de l'indexation après Googlebot ?
Google reste volontairement flou sur les détails techniques. On sait qu'interviennent des composants comme Caffeine (infrastructure d'indexation), les algorithmes de qualité, les filtres anti-spam, les systèmes de déduplication et de canonicalisation.
En pratique, une fois Googlebot passé, le contenu traverse plusieurs couches d'analyse avant d'atterrir dans l'index. Et c'est là que tout se joue.
- Googlebot récupère, il ne juge pas
- L'indexation relève d'autres systèmes après le crawl
- Optimiser le crawl ne suffit jamais à garantir l'indexation
- Les problèmes d'indexation ne viennent pas de Googlebot mais des critères de qualité et de pertinence
Avis d'un expert SEO
Cette déclaration change-t-elle vraiment quelque chose sur le terrain ?
Pas vraiment — pour ceux qui suivent déjà la logique de Google. La séparation crawl/indexation est connue depuis longtemps, mais cette confirmation officielle permet de couper court aux confusions récurrentes.
Le problème, c'est que beaucoup de sites optimisent frénétiquement leur crawl budget en pensant que cela résoudra leurs problèmes d'indexation. Spoiler : ça ne marche pas. Un site peut être crawlé 10 000 fois par jour et n'indexer que 10 % de ses pages.
Quelles nuances faut-il apporter à cette déclaration ?
Gary Illyes simplifie volontairement pour clarifier, mais la réalité est plus imbriquée. Googlebot remonte des signaux qui influencent indirectement l'indexation : temps de chargement, erreurs HTTP, redirections, disponibilité des ressources critiques.
Dire que Googlebot ne prend aucune décision est techniquement vrai, mais il collecte des données qui alimentent les systèmes décisionnels en aval. Nuance importante.
Pourquoi certains sites bien crawlés ne sont-ils jamais indexés ?
Parce que la qualité prime sur tout le reste. Un site peut être techniquement impeccable — rapide, bien structuré, accessible — et se voir refuser l'indexation si le contenu est jugé faible, dupliqué, ou peu pertinent.
Les critères E-E-A-T, les signaux de spam, la cannibalisation interne, les problèmes de canonicalisation, tout cela se joue après le passage de Googlebot. Et c'est là que ça coince souvent.
Impact pratique et recommandations
Que faut-il faire concrètement suite à cette déclaration ?
Arrêtez d'obseder uniquement sur le crawl. Oui, il faut un crawl efficace, mais ce n'est qu'une étape. Concentrez-vous sur les critères d'indexation : qualité du contenu, originalité, autorité thématique, signaux E-E-A-T, absence de duplication.
Vérifiez la Search Console, section Couverture (ou Pages dans la nouvelle interface). Les pages crawlées mais non indexées apparaissent clairement — c'est là qu'il faut investiguer.
Quelles erreurs éviter absolument ?
Ne misez pas tout sur l'optimisation du fichier robots.txt ou du sitemap XML en pensant régler vos problèmes d'indexation. Ces fichiers facilitent le crawl, pas l'indexation.
Évitez aussi de confondre pages découvertes et pages indexées. Google peut découvrir une URL sans jamais l'indexer — c'est même courant sur les gros sites avec du contenu faible ou dupliqué.
Comment vérifier que mon site est conforme à cette logique ?
Auditez séparément crawlabilité et indexabilité. Côté crawl : vérifiez les logs serveur, le fichier robots.txt, les sitemaps, le maillage interne. Côté indexation : analysez la qualité des contenus, les balises canonical, les meta robots, les signaux de pertinence et d'autorité.
Utilisez des outils comme Screaming Frog pour le crawl, et la Search Console pour l'indexation. Croisez les données pour identifier les pages crawlées mais exclues de l'index.
- Auditez les logs serveur pour comprendre le comportement réel de Googlebot
- Corrigez les erreurs de crawl (4xx, 5xx, redirections en chaîne, timeout)
- Analysez la qualité du contenu des pages non indexées
- Vérifiez les balises canonical et meta robots
- Éliminez les duplications et contenus faibles
- Renforcez les signaux E-E-A-T sur les pages stratégiques
- Surveillez régulièrement la Search Console, section Couverture/Pages
❓ Questions frequentes
Si Googlebot ne décide pas de l'indexation, qui décide alors ?
Un site bien crawlé est-il forcément bien indexé ?
Comment savoir si mes problèmes viennent du crawl ou de l'indexation ?
Optimiser le crawl budget améliore-t-il l'indexation ?
Quels signaux Googlebot transmet-il aux systèmes d'indexation ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 14/03/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.