Official statement
Other statements from this video 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
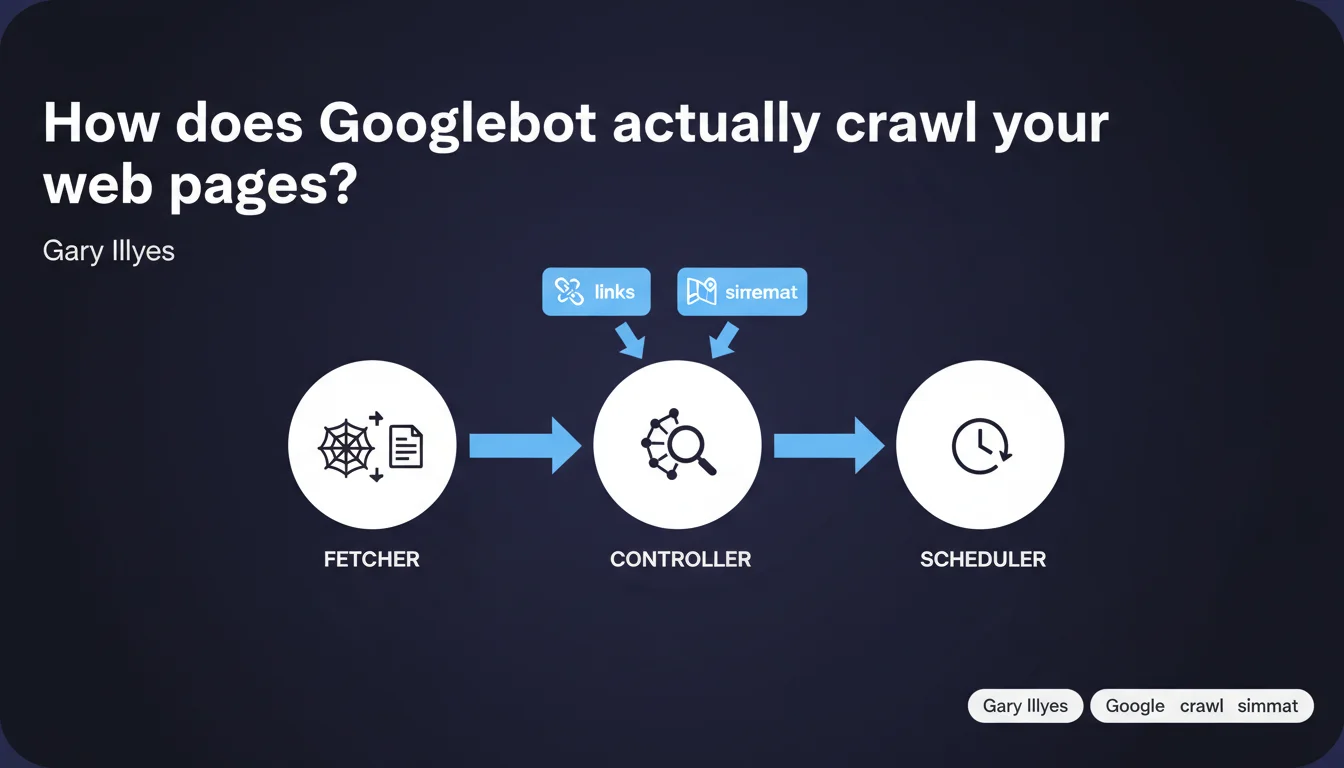
Googlebot relies on three distinct systems: a fetcher that downloads pages, a controller that centralizes all discovered links (HTML + sitemaps), and a scheduler that decides on crawl timing. This modular architecture directly impacts your crawl budget strategy and technical optimization.
What you need to understand
Why does Google detail the internal architecture of its crawler?
Gary Illyes lifts the veil on the technical structure of Googlebot to help SEO professionals better understand the mechanisms of URL discovery and prioritization. This rare transparency allows you to optimize your site's technical architecture more precisely.
Knowing that Googlebot separates fetching (fetcher), link centralization (controller), and scheduling (scheduler) changes everything. Each system has its role — and its limitations.
What exactly does each of these three components do?
The fetcher is the workhorse: it downloads HTML, executes JavaScript if necessary, retrieves resources. It's the one consuming your bandwidth and putting strain on your servers.
The controller aggregates all discovered links — whether they come from crawled HTML or XML sitemaps. It merges these sources to build a single queue. Crucial point: sitemaps don't bypass the system, they feed into the same decision pool.
The scheduler orchestrates when and how frequently to crawl each URL. It accounts for crawl budget, content freshness, page popularity. It's the brain that decides priorities.
What are the implications for crawl budget?
This modular architecture means that all signals converge toward the scheduler. Multiplying discovery sources (internal links + sitemaps + external links) doesn't guarantee faster crawling if the scheduler deems the page non-priority.
Crawl budget therefore depends less on how many times Googlebot "sees" a URL than on the quality of signals accompanying it: popularity, freshness, depth in site structure.
- The fetcher downloads pages and puts strain on your servers
- The controller centralizes all discovered links (HTML + sitemaps)
- The scheduler decides on crawl timing based on priorities
- Sitemaps feed into the same system as HTML links — no shortcuts
- Optimizing crawl = influencing scheduler decisions, not overwhelming the controller
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, broadly speaking. We've long observed that submitting a URL in a sitemap doesn't force immediate crawling — which confirms that the controller simply merges sources without automatic prioritization. The scheduler remains in control.
However, Google remains vague about the scheduler's exact criteria: what weight for popularity, freshness, depth? These variables are nebulous. [To verify]: impossible to know whether an internal link from the homepage carries more weight than a sitemap mention in the priority calculation.
What nuances should we add?
Google probably oversimplifies. In reality, Googlebot has multiple specialized fetchers (mobile, desktop, AdsBot, Googlebot Images…). Speaking of "one" fetcher is reductive — each bot has its technical specificities and priority queue.
Another point: this architecture concerns the initial crawl, but what about recrawling? Does the scheduler treat a previously known URL differently than a newly discovered one? The statement doesn't clarify. [To verify] on sites with high editorial velocity.
In what cases does this architecture show its limitations?
On very large sites (e-commerce, classified ads), the controller can receive millions of URLs. The scheduler must then arbitrate drastically — and some legitimate pages may remain off the radar for weeks.
Another case: sites with heavy client-side JavaScript. The fetcher must render the page, which slows everything down. If the scheduler detects high crawl cost, it will reduce frequency — a vicious cycle.
Practical impact and recommendations
What should you concretely do to optimize each of these three systems?
For the fetcher: Reduce server response time and facilitate rendering. Limit redirects, compress resources, avoid superfluous JavaScript. The less the fetcher struggles, the more URLs it crawls.
For the controller: Ensure your strategic URLs are discovered via multiple channels — internal links from strong pages AND XML sitemaps. Don't rely on a single vector.
For the scheduler: Send priority signals. Internal links from the homepage or popular pages, frequent content updates, external mentions. The scheduler loves "living" pages.
What mistakes should you absolutely avoid?
Don't overwhelm the controller with millions of useless URLs (facets, filters, parameters). You dilute signals and bury your strategic pages. The scheduler may lower overall domain priority.
Another mistake: believing that submitting 50,000 URLs in a sitemap will force massive crawling. The scheduler will only crawl what it deems priority — the rest will wait. Better a 5,000-URL strategic sitemap than a 100,000-URL catch-all.
How can you verify that your site is well optimized for this architecture?
Analyze server logs to spot crawl patterns: does Googlebot return regularly to your key pages? Does it ignore entire sections? Does it crawl useless URLs in loops?
Compare URLs submitted in your sitemap with those actually crawled (Search Console > Coverage). If a large gap persists, the scheduler deems your URLs non-priority — investigate why.
- Optimize server response time to ease the fetcher's work
- Centralize your strategic URLs in a clean sitemap (no catch-all)
- Strengthen internal linking from high internal PageRank pages
- Monitor server logs to identify the scheduler's actual priorities
- Eliminate useless URLs (facets, duplicates) to avoid diluting signals
- Regularly update your key content to signal freshness
❓ Frequently Asked Questions
Les sitemaps XML ont-ils une priorité supérieure aux liens internes pour Googlebot ?
Peut-on forcer Googlebot à crawler une page en la soumettant plusieurs fois ?
Comment le scheduler décide-t-il quelles pages crawler en priorité ?
Le fetcher de Googlebot exécute-t-il systématiquement le JavaScript ?
Un site lent est-il pénalisé par le scheduler de Googlebot ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 14/03/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.