Official statement
Other statements from this video 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
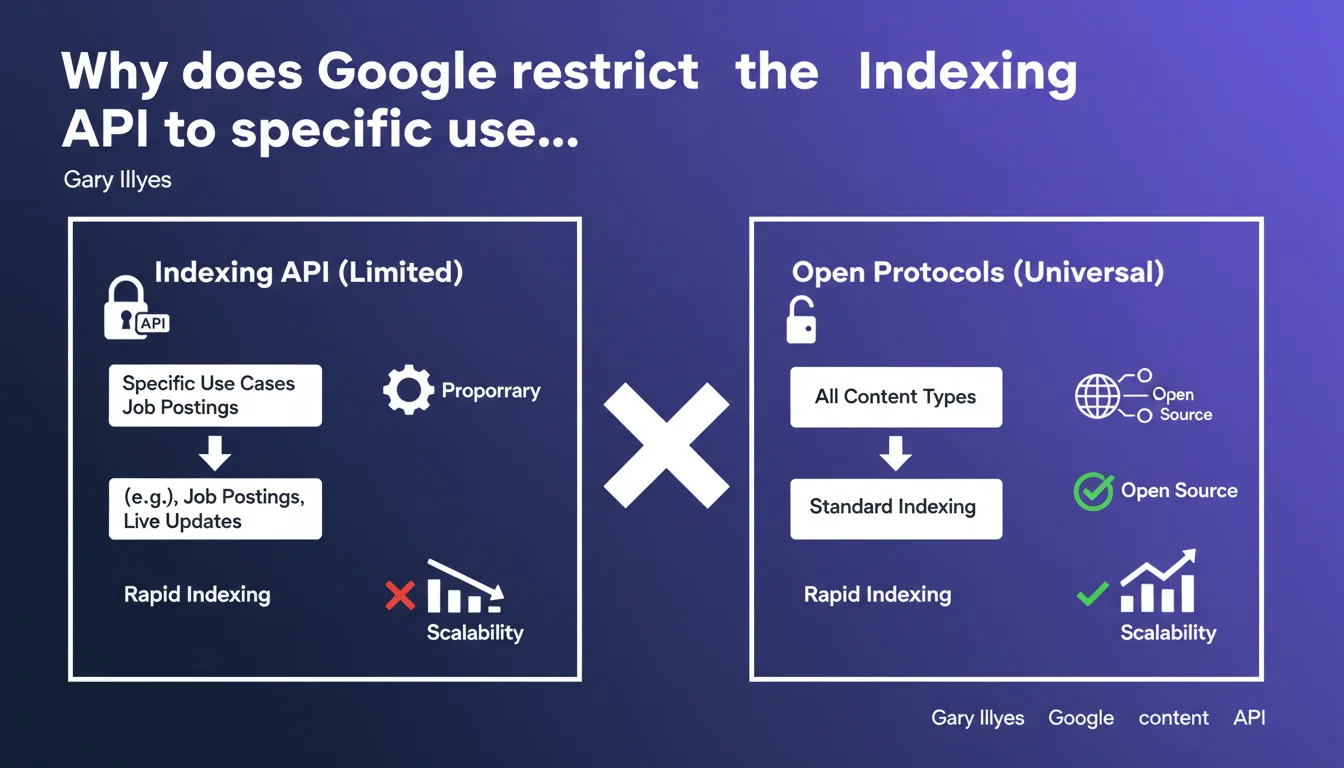
The Indexing API is not designed to index all your content at scale. Google reserves it for specific use cases because it's neither scalable nor open like standard protocols. In other words: forget about using it to force-index all your pages.
What you need to understand
What is the Indexing API and why does it exist?
The Indexing API is a tool developed by Google that allows you to notify the search engine in real-time of new or updated specific content. It was originally created for precise use cases: job postings and livestream videos.
The goal? To accelerate the indexing of content with high time sensitivity, where every minute counts. A job listing that disappears in 48 hours or a livestream starting within an hour requires the responsiveness that traditional crawling cannot guarantee.
Why does Google emphasize that it's not scalable?
Gary Illyes uses the term "scalable" for a simple reason: the API generates significant technical load on Google's side. Unlike organic crawling that Googlebot manages at its own pace, the Indexing API forces immediate processing.
If thousands of sites used it to submit every page in their catalog, it would create unmanageable pressure on the infrastructure. Google maintains control by limiting authorized use cases.
What does "proprietary" mean compared to open protocols?
By mentioning the proprietary nature of the API, Illyes contrasts this closed solution with universal web standards like XML sitemaps or RSS feeds. These are documented, open, and work with any search engine.
The Indexing API, however, only works with Google. You create technical dependency on a closed ecosystem with no guarantee of longevity or compatibility with other platforms.
- The Indexing API is reserved for job postings and livestreams — not product pages, blog articles, or landing pages
- It generates technical load that Google doesn't want to see explode, hence the strict restrictions
- Unlike XML sitemaps, it doesn't rely on an open standard and remains under Google's exclusive control
- Using it outside authorized cases risks penalties or revocation of API access
SEO Expert opinion
Is this limitation really technical or strategic?
Let's be honest: the scalability argument holds water, but it also masks a strategic dimension. Google doesn't want to give SEOs a "index my page now" button for just anything.
If this API became a generalist indexing channel, it would bypass the entire crawl and prioritization system Google spent years refining. The search engine would lose control over what it indexes, when, and how — unthinkable for Googlebot.
[To verify]: some practitioners report using the API for unauthorized content without immediate consequence. But the absence of visible penalty doesn't mean there's no algorithmic deprioritization or watchlisting happening.
Are open protocols really sufficient?
In 95% of cases, yes. A well-structured XML sitemap, combined with solid internal linking and optimized crawl budget, is more than enough for effective indexing. Adding RSS feeds for fresh content remains a good complementary practice.
The problem only arises when you have ultra-time-sensitive content where a few hours' delay changes everything. In that specific case — and only that one — the Indexing API makes sense.
What field observations contradict this statement?
No direct contradiction, but an important nuance: sites with limited crawl budget sometimes experience indexing delays of several days or even weeks, even with a perfectly configured sitemap.
In these situations, the frustration of being unable to force indexing is real. Google responds "optimize your architecture," but when you've already done everything on the technical side, the message rings hollow. The API could have been a lever, but Google refuses to make it accessible to everyone.
Practical impact and recommendations
What should you concretely do if you have time-sensitive content?
First, verify that your content falls within authorized use cases: structured job listings with JobPosting schema, or livestream videos with BroadcastEvent schema. If so, configure the API via Google Search Console and strictly follow official documentation.
If your content doesn't match — ephemeral events, flash promotions, breaking news — forget the Indexing API. Instead, focus on a dynamic sitemap updated in real-time, with precise <lastmod> tags and an optimized crawl budget.
What mistakes should you absolutely avoid?
Don't try to bypass restrictions by disguising your content. Declaring product pages as job listings to trigger the API? Bad idea. Google detects these manipulations through schema markup and the actual page content.
Another frequent mistake: installing a plugin that automatically sends every post via the Indexing API. It might work for a few weeks, then you lose access without warning or explanation. And recovering revoked access is nearly impossible.
How do you ensure fast indexing remains without the API?
Focus on fundamentals that actually accelerate crawling: server response time under 200ms, pages accessible in maximum 3 clicks from the homepage, segmented sitemap by content type with clear priorities.
Add an active push strategy: manually submit critical URLs via Search Console, use RSS feeds for aggregators, trigger social signals that generate quick visits — Googlebot often follows traces of user activity.
- Verify that your content strictly matches authorized use cases (JobPosting or BroadcastEvent schema)
- Never use the Indexing API for standard pages, even if tools propose it
- Optimize crawl budget: flat architecture, segmented XML sitemap, precise lastmod
- Monitor indexing delays via Search Console and identify bottlenecks
- For urgent content outside API: manual submission + social push + RSS feeds
- Document all API calls if you use it legitimately, to trace any anomalies
❓ Frequently Asked Questions
Puis-je utiliser l'Indexing API pour mes articles de blog ou pages produit ?
Quels sont les risques si j'utilise l'API hors cas autorisés ?
Un sitemap XML suffit-il vraiment pour une indexation rapide ?
Comment savoir si mon site a un problème de crawl budget ?
Les plugins WordPress qui utilisent l'Indexing API sont-ils légaux ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 14/03/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.