Official statement
Other statements from this video 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
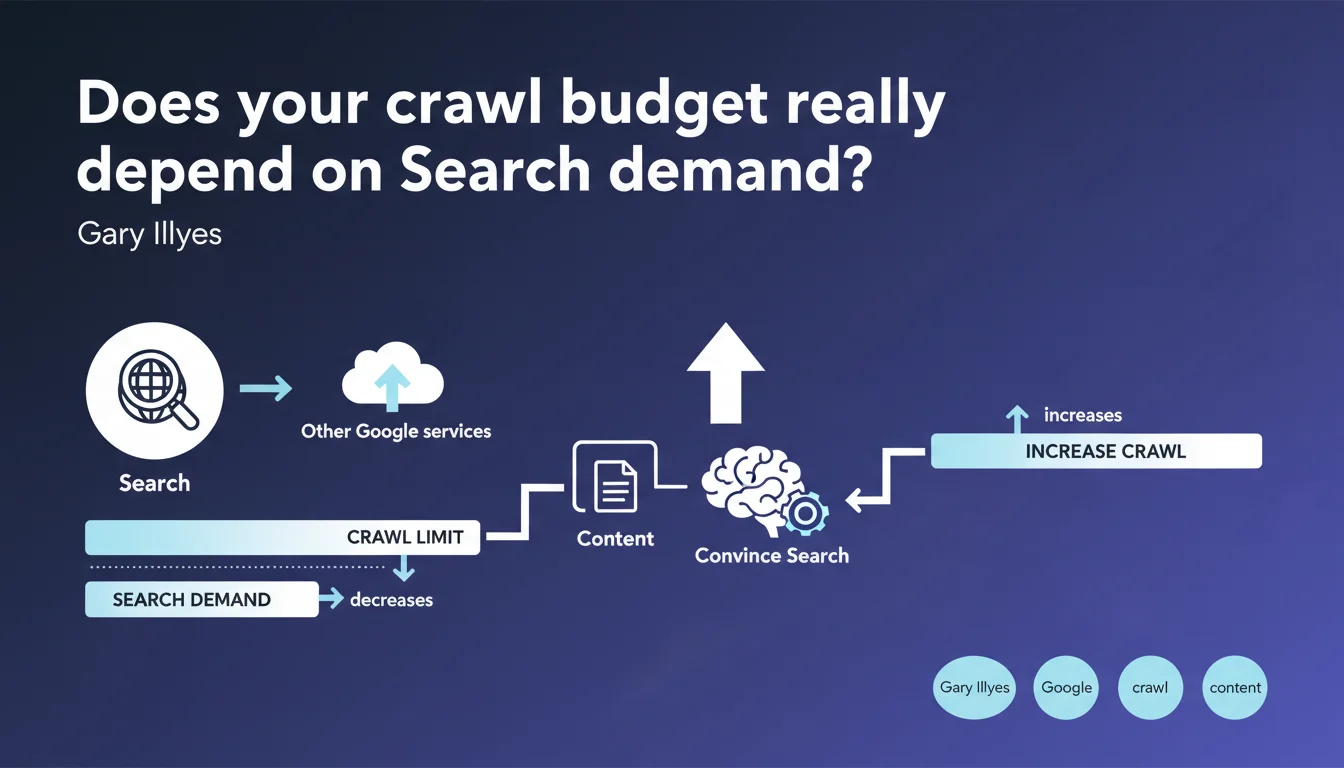
Google confirms that crawl budget is not solely determined by Search, but also by other internal services. If demand for your content drops on the Search side, your crawl limit automatically decreases. The only way to increase crawl: prove to Google that your content deserves to be fetched regularly.
What you need to understand
What does Google mean by "Search demand"?
Gary Illyes introduces here a rarely explained concept: Search demand. Concretely, this means that Google evaluates how useful your content is to its users — searches performed, clicks, expected freshness, thematic authority.
If your site generates little organic traffic, if your pages are rarely clicked in search results, or if your content stagnates without updates, Google considers demand to be low. Result: fewer reasons to crawl intensively.
Why do other Google services influence crawl budget?
Google doesn't crawl only for Search. Google News, Discover, Google Images, Google Scholar — all these services have their own freshness and coverage needs. If your site feeds multiple Google products, your crawl budget benefits from a higher allocation.
Conversely, a single-topic site with a stable audience and little content variation will have a more conservative crawl budget. It's a logic of resource profitability on Google's end.
How does this statement change our approach to crawl budget?
Until now, many SEOs viewed crawl budget as a technical constraint — server speed, robots.txt, site depth. Google reminds us that content quality and relevance are equally powerful, if not more so.
A technically perfect site with outdated or barely demanded content will be crawled less frequently than a technically average site with fresh, sought-after content.
- Search demand directly influences the crawl limit allocated to your site
- Other Google services (Discover, News, Images) also contribute to this allocation
- Content quality and freshness become crawl budget factors just as much as technical optimization
- A rarely visited or rarely clicked site in the SERPs will see its crawl budget decrease mechanically
SEO Expert opinion
Is this statement consistent with observed practices?
Yes, largely. In the field, we've observed for years that high-traffic and high-activity sites — media outlets, e-commerce with rotating inventory, news sites — benefit from intensive crawling, sometimes multiple times per hour. Conversely, a corporate blog that publishes one article per month will be crawled at a far more spaced frequency.
What's new is that Google openly admits it and explicitly links it to "Search demand". Previously, this notion remained vague, and many professionals continued to believe that only technical optimization mattered.
What nuances should we add to this claim?
Gary Illyes remains vague about what precisely constitutes "Search demand". [To be verified]: is it only the search volume targeting your pages? CTR? Expected freshness by request category? No concrete metric is provided.
Another point: he mentions "other Google services" without specifying which ones or their respective weight. If your site feeds Google News, what is the real gain in crawl budget? Impossible to quantify with this statement.
In which cases does this rule not apply?
Sites with a very limited page volume (a few hundred) are generally not affected by crawl budget issues. Google can afford to crawl everything regularly without significant impact on its resources.
Similarly, sites with critical resources (canonical URLs, priority sitemaps) can force a certain level of crawl even with low demand — but this remains marginal and does not compensate for obsolete content.
Practical impact and recommendations
What should you concretely do to increase crawl budget?
If your crawl budget is insufficient, improving Search demand becomes a priority. This involves editorial and UX actions as much as technical ones: publish fresh content regularly, target queries with search volume, optimize CTR in the SERPs, improve user engagement.
In parallel, multiply Google entry points: feed Google Discover with visually engaging content, submit your content to Google News if relevant, optimize your images for Google Images. Each additional service that crawls your site contributes to increasing the overall allocation.
What mistakes should you avoid to not waste your crawl budget?
Don't reflexively block entire sections via robots.txt thinking you're "saving" crawl budget. If these sections generate demand — category pages, useful filters — you deprive Google of signals that would justify more intensive crawling.
Also avoid neglecting your existing content. A site that publishes a lot but leaves 80% of its content aging without updates sends a contradictory signal: occasional strong demand, but low overall value.
How can you verify that your site is optimizing crawl budget well?
Analyze server logs to identify pages crawled frequently vs those ignored. Compare with your business priorities: if strategic pages are under-crawled, question their actual demand (organic traffic, CTR, freshness).
In Google Search Console, review the coverage report and crawl statistics. A crawl drop can signal a demand decrease — in which case you need to investigate: loss of rankings, CTR drop, obsolete content.
- Publish regularly fresh, targeted content on queries with search volume
- Optimize titles and meta descriptions to improve CTR in the SERPs
- Feed multiple Google services (Discover, News, Images) to multiply crawl allocations
- Periodically update existing content to maintain its relevance and demand
- Analyze server logs to detect under-crawled strategic pages
- Don't arbitrarily block sections that generate user demand
- Monitor Search Console reports to anticipate crawl drops and respond quickly
❓ Frequently Asked Questions
Quels services Google, autres que Search, influencent le crawl budget ?
Un site avec peu de trafic peut-il quand même avoir un bon crawl budget ?
Comment savoir si mon crawl budget est suffisant ou insuffisant ?
Est-ce que publier plus souvent augmente automatiquement le crawl budget ?
Les optimisations techniques sont-elles devenues inutiles pour le crawl budget ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 14/03/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.