Official statement
Other statements from this video 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Google manque-t-il vraiment d'espace de stockage pour indexer votre contenu ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
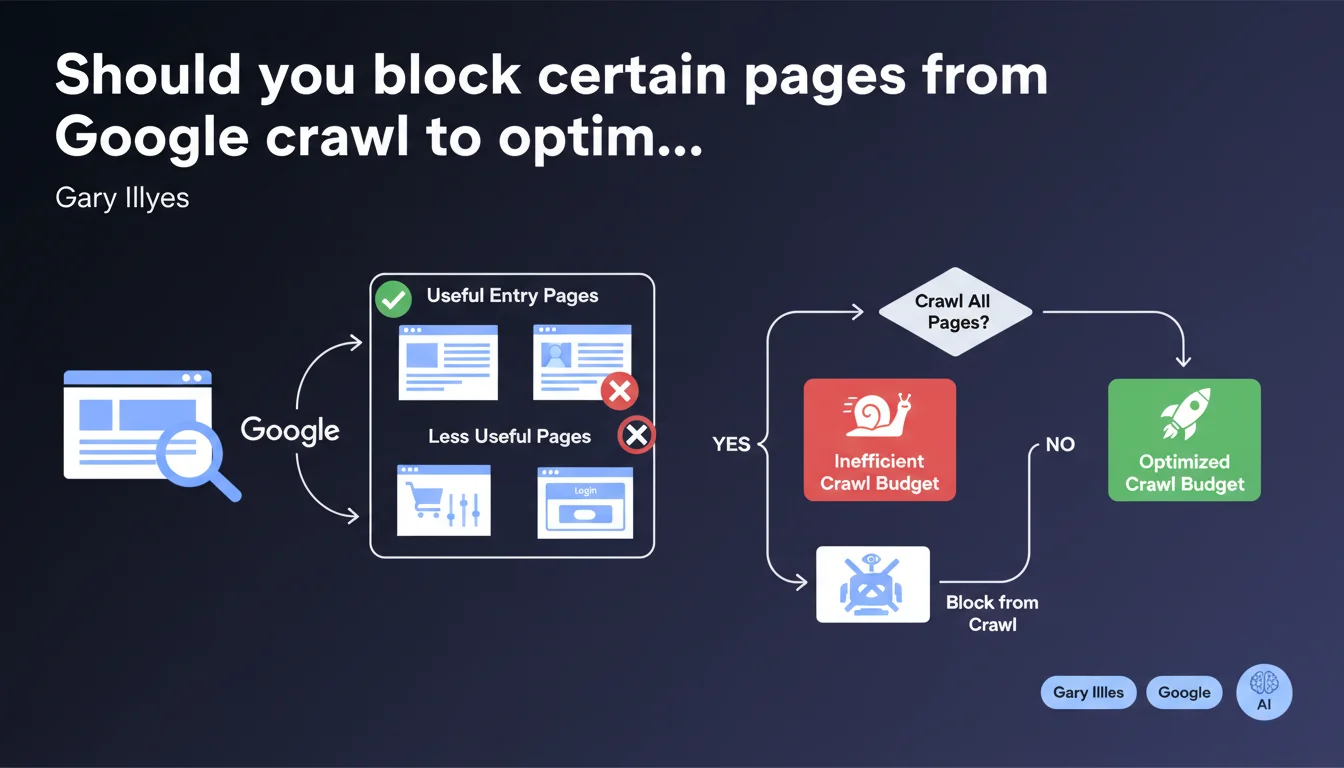
Google clearly states that not all pages of a website should be crawled. Pages without value as entry points — shopping carts, hyper-filtered facets, internal search results — consume crawl budget unnecessarily. The challenge: prioritize crawl resources on pages that actually convert from search.
What you need to understand
Why does Google insist on this distinction between useful pages and superfluous pages?
Google has limited crawl resources for each website. The larger a site is, the more this budget gets diluted. If Googlebot spends time on pages that add no value in the SERPs, it has less to dedicate to strategic content.
The crucial nuance: a page can be useful for the user already on the site (shopping cart, ultra-specific filter) without deserving to appear in search results. These pages exist to streamline the user journey, not to rank.
Which pages are typically affected by this exclusion?
Gary Illyes cites two concrete examples: shopping carts and hyper-filtered pages. But the principle extends to any page generated dynamically without corresponding search intent.
In practice: internal search result pages, session URLs, infinite variations of sorting or combined filters, login pages, post-purchase thank you pages. All these URLs consume crawl without delivering qualified traffic.
Does this approach contradict the logic of maximum indexation?
Yes, and it's intentional. The era when "more indexed URLs = better" is over. Google now prioritizes quality over quantity. A site with 10,000 indexed pages of which 8,000 have no SEO value performs worse than a site with 2,000 targeted pages.
This position is part of the logic of crawl budget optimization and quality rater guidelines. Google wants to index what serves the user searching for an answer, not everything that technically exists.
- Crawl budget is not infinite, even for large sites
- A page useful for navigation is not necessarily relevant as an entry point from Google
- Combined facet URLs explode crawled volume without ROI
- Strategically blocking certain pages improves crawl distribution on profitable content
- Google values sites that facilitate its work by signaling what really matters
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. Crawl audits on e-commerce sites or those with strong UGC dimensions systematically show that 60 to 80% of crawled URLs bring no organic traffic. Server logs confirm it: Googlebot spends disproportionate time on redundant filter pages or parameterized URLs.
Sites that implemented a strict robots.txt or noindex strategy on these ancillary pages observe — provided clean implementation — a revaluation of crawl on strategic pages and often improved overall performance within 4 to 8 weeks.
What nuances should be applied to this recommendation?
First trap: confusing "not crawling" with "not indexing." They're not the same thing. A page can be crawled without being indexed (noindex), or blocked from crawl via robots.txt. Choosing between the two has different consequences for PageRank transmission and link discovery.
Second nuance — and Google deliberately remains vague here: where to draw the line on facets? A page filtered by 1 criterion can have real intent ("women's running shoes"). With 4 combined filters ("women's running shoes size 8 blue on sale"), intent becomes microscopic. [To verify]: Google provides no clear metrics to draw the line.
In what cases does this rule not apply?
On sites with low page volume (fewer than 500-1000 URLs), crawl budget is generally not a limiting factor. Blocking pages becomes counterproductive if it unnecessarily complicates the architecture.
Another exception: internal search result pages can, in some contexts, capture interesting long-tail traffic. Some media sites or marketplaces intentionally leave these pages indexed — but it's a risky bet that requires constant monitoring of the crawl/value ratio.
Practical impact and recommendations
What concretely should you do to apply this recommendation?
First step: audit server logs for at least 30 days to identify which URLs are crawled and how frequently. Cross-reference this data with GA4 or equivalent performance: which URLs generate organic traffic, which URLs are crawled but useless?
Next, segment URLs into three categories: strategic pages (must crawl), secondary pages (useful but not priority), pages with no SEO value (block or noindex). This segmentation must be based on data, not intuition.
What mistakes should you avoid in this approach?
Classic mistake: blocking via robots.txt pages that receive backlinks. Robots.txt prevents PageRank transmission. If a useless page receives external links, it's better to noindex it while allowing crawl to pass so the juice flows upstream.
Another trap: applying mass noindex on facets without checking the impact on internal linking. If these pages served as hubs linking to products, their disappearance from the index can isolate strategic content. Always simulate the impact on the link graph before deploying.
How do you verify your site respects this logic?
Use Search Console to monitor the crawl rate vs indexation rate. If Google crawls 10,000 URLs per day but only indexes 2,000, it's a clear signal that crawl is being wasted. Dig into coverage reports to identify patterns of superfluous URLs.
In parallel, observe crawl evolution after each robots.txt or noindex adjustment. A good indicator: the number of crawled pages per day should stabilize or decrease while strategic pages see their crawl frequency increase.
- Analyze 30+ days of server logs to map actual crawl
- Identify URLs crawled but without organic traffic (Search Console report + GA4)
- Segment pages: strategic / secondary / to block
- Check backlinks before blocking a URL via robots.txt
- Favor noindex for pages with inbound links
- Simulate impact on internal linking before large-scale deployment
- Monitor crawl evolution in Search Console post-implementation
- Document each blocking decision to facilitate future audits
❓ Frequently Asked Questions
Dois-je bloquer les pages de panier via robots.txt ou noindex ?
Comment savoir si mon crawl budget est un problème ?
Les facettes de filtres doivent-elles toutes être bloquées ?
Peut-on récupérer du crawl budget rapidement après optimisation ?
Le crawl budget impacte-t-il vraiment le ranking ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 14/03/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.