Official statement
Other statements from this video 14 ▾
- □ Qu'est-ce qu'un crawler web et pourquoi Google insiste-t-il sur cette définition ?
- □ Googlebot ne fait-il vraiment que crawler sans décider de l'indexation ?
- □ Comment Googlebot crawle-t-il réellement vos pages web ?
- □ Le crawl budget dépend-il vraiment de la demande de Search ?
- □ Le crawl budget existe-t-il vraiment chez Google ?
- □ Faut-il bloquer certaines pages du crawl Google pour optimiser son budget ?
- □ Les liens naturels sont-ils vraiment plus importants que les sitemaps pour la découverte ?
- □ Faut-il vraiment lier depuis la page d'accueil pour accélérer le crawl de vos nouvelles pages ?
- □ Faut-il vraiment limiter l'usage de l'Indexing API aux seuls cas d'usage recommandés par Google ?
- □ Pourquoi Google limite-t-il l'usage de l'Indexing API à certains contenus ?
- □ L'Indexing API peut-elle faire retirer votre contenu aussi vite qu'elle l'indexe ?
- □ Comment l'amélioration de la qualité du contenu accélère-t-elle le crawl de Google ?
- □ Faut-il supprimer vos pages de faible qualité pour améliorer votre crawl budget ?
- □ L'outil d'inspection d'URL peut-il vraiment accélérer l'indexation de vos améliorations ?
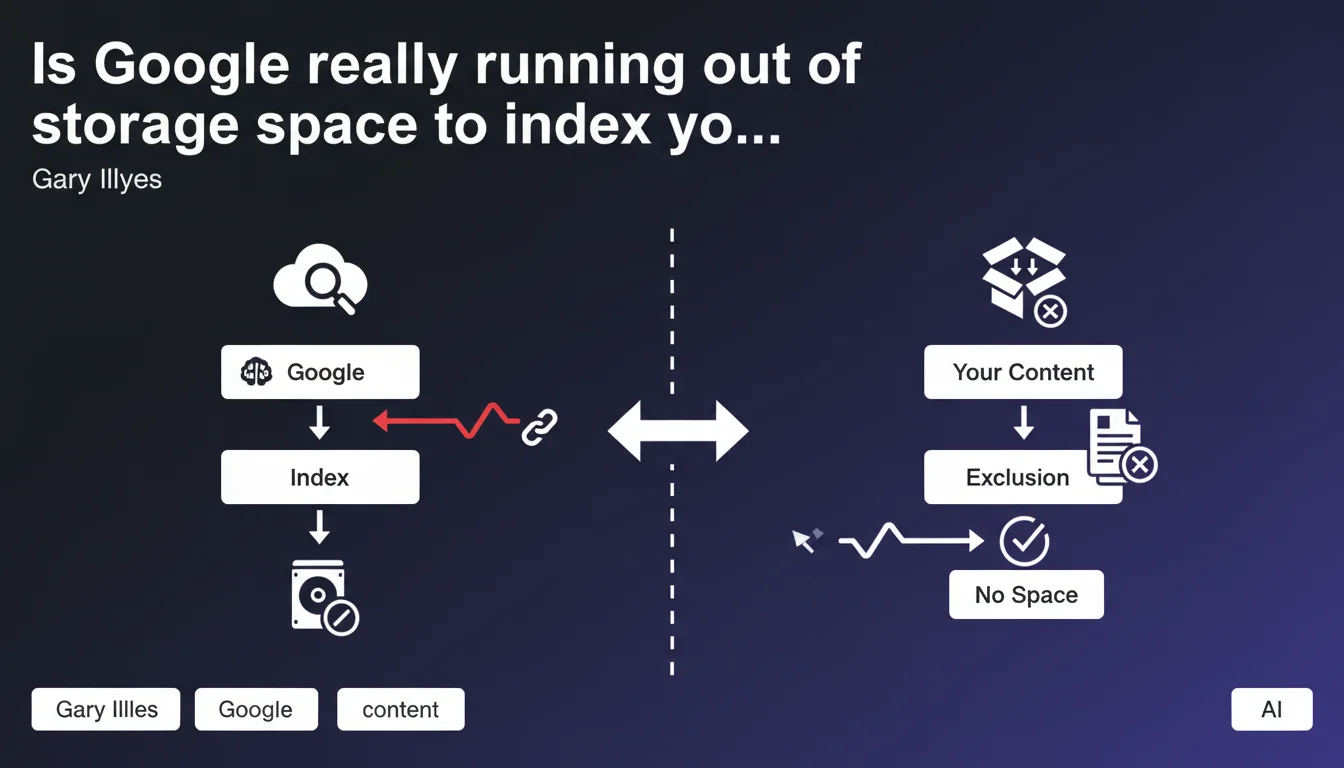
Google excludes certain pages from its index not because of their quality, but due to insufficient storage space. This technical constraint forces the search engine to make drastic choices about what deserves to be kept on its servers. Sites must now optimize their architecture to maximize their chances of complete indexation.
What you need to understand
Does Google really have storage limitations in 2025?
Gary Illyes' statement challenges the idea that a giant like Google has unlimited resources. Even with datacenters spread globally, the cost of storage, maintenance, and indexing remains colossal.
Concretely, this means Google prioritizes what it indexes. A technically accessible and crawlable page might never appear in the index if Google determines it doesn't deserve the space it would occupy. It's not always a matter of quality — it's also a matter of economic tradeoff.
What determines whether a page deserves its space in the index?
Google evaluates several dimensions: content freshness, perceived usefulness, crawl frequency, level of duplication, and the likelihood that a user is searching for this information.
An orphaned page, rarely updated, with content very similar to other URLs, will have little chance of staying indexed. Conversely, a page regularly crawled, with identified organic traffic or an incoming link profile, will be prioritized.
Does this limitation impact all sites the same way?
No. Small sites with a few hundred pages will probably never encounter this ceiling. However, e-commerce sites, content aggregators, media outlets, or UGC platforms with millions of URLs are directly affected.
Google won't index 500,000 product pages if 80% are nearly identical variants. It will make choices — sometimes brutal ones — to keep only what makes sense for its users and servers.
- Google actively manages what enters and exits its index based on material constraints
- Excluding a page doesn't necessarily mean it's poor quality
- Crawling a page doesn't guarantee its sustained indexation
- Massive sites must anticipate this limit by optimizing their architecture
- The economic cost of storage is a real factor in Google's decisions
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Absolutely. For several years, we've seen massive sites lose tens of thousands of indexed pages without clear explanation. Search Console displays "Crawled, currently not indexed" or "Discovered, currently not indexed" for growing volumes of URLs.
Often, these pages have no major technical flaws. They're crawlable, have unique content, and comply with guidelines. But Google simply decides they're not worth their place in the index. Gary Illyes' statement confirms what we suspected: it's not always a matter of quality, but of capacity.
Why is Google communicating about this now?
Probably to calm webmasters' concerns as they panic seeing their indexation rate drop. By saying "it's not always your fault," Google shifts responsibility to its own technical constraints.
It's also a way to push sites to better structure their content. If Google has to choose, better to make its job easier by submitting only strategic pages. This statement also legitimizes the massive use of crawl budget and prioritization via sitemap, robots.txt, and canonical tags.
Can we really trust this explanation?
With a caveat. Google has an interest in downplaying concerns related to algorithmic disqualification. Saying "we don't have enough space" sounds less harsh than "we're not interested in your content".
[To verify]: To what extent is this storage limit real versus a pretext to justify exclusion choices based on algorithms? It's likely both factors combine. A page judged as low relevance AND costly in storage will be sacrificed first.
Practical impact and recommendations
What should you do concretely to maximize your indexation chances?
Reduce the number of URLs submitted to Google. Block via robots.txt or noindex everything with no SEO value: redundant filter pages, useless archives, parameter URLs, purely technical content.
Consolidate your content. If you have 10 similar articles on a topic, merge them into one comprehensive resource rather than diluting authority across ten mediocre pages. Google prefers indexing one strong page over ten average ones.
Use XML sitemap strategically. Submit only priority URLs — those you absolutely want indexed. A 10,000-URL sitemap of well-chosen pages beats a 500,000-URL sitemap where 80% are worthless.
What signals should you send Google to prioritize your pages?
Increase crawl frequency on your strategic pages by integrating them into your main internal linking structure. The more easily a page is accessible from your homepage or key sections, the more important Google considers it.
Regularly update your flagship content. A fresh page has better chances of staying indexed than one frozen for three years. Add sections, update data, integrate new media.
Strengthen external signals: inbound links, shares, mentions. A page generating direct or referral traffic faces less risk of being excluded for storage reasons.
What mistakes must you absolutely avoid?
Don't let Google discover thousands of valueless pages. Infinite facets, user session pages, tracking URLs — all of this must be blocked or canonicalized.
Don't rely on crawling to guarantee indexation. A crawled page can remain "Discovered, not indexed" indefinitely if Google judges it unworthy of its space. Ensure each crawled URL has a reason to exist.
- Audit your current index via Search Console and identify "Crawled, not indexed" pages
- Block or deindex all content with no strategic SEO value
- Consolidate redundant or weak content into comprehensive resources
- Optimize XML sitemap to submit only priority URLs
- Strengthen internal linking to key pages
- Regularly update strategic content to maintain its freshness
- Monitor indexation rate evolution and react quickly to declines
- Prioritize quality and uniqueness over raw URL volume
❓ Frequently Asked Questions
Est-ce que toutes les pages crawlées par Google sont indexées ?
Comment savoir si mes pages sont exclues pour des raisons de stockage ou de qualité ?
Peut-on forcer Google à indexer une page importante ?
Les petits sites sont-ils aussi concernés par cette limite de stockage ?
Faut-il supprimer les pages non indexées pour améliorer le taux global ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 14/03/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.