Official statement
Other statements from this video 9 ▾
- □ Pourquoi l'API Search Console révèle 50 fois plus de données que l'interface standard ?
- □ L'API Search Analytics peut-elle remplacer l'interface Search Console pour piloter votre SEO ?
- □ L'API URL Inspection peut-elle vraiment remplacer les tests manuels d'indexation ?
- □ Comment exploiter l'API URL Inspection pour détecter les écarts entre canonical déclaré et canonical Google ?
- □ Peut-on vraiment déboguer les données structurées à grande échelle avec l'API URL Inspection ?
- □ Faut-il surveiller vos sitemaps via l'API dédiée de Google ?
- □ Pourquoi combiner l'API Search Console avec d'autres sources de données SEO ?
- □ L'API Sites de Search Console peut-elle vraiment simplifier la gestion de vos propriétés ?
- □ Faut-il vraiment passer par les bibliothèques clientes pour exploiter l'API Search Console ?
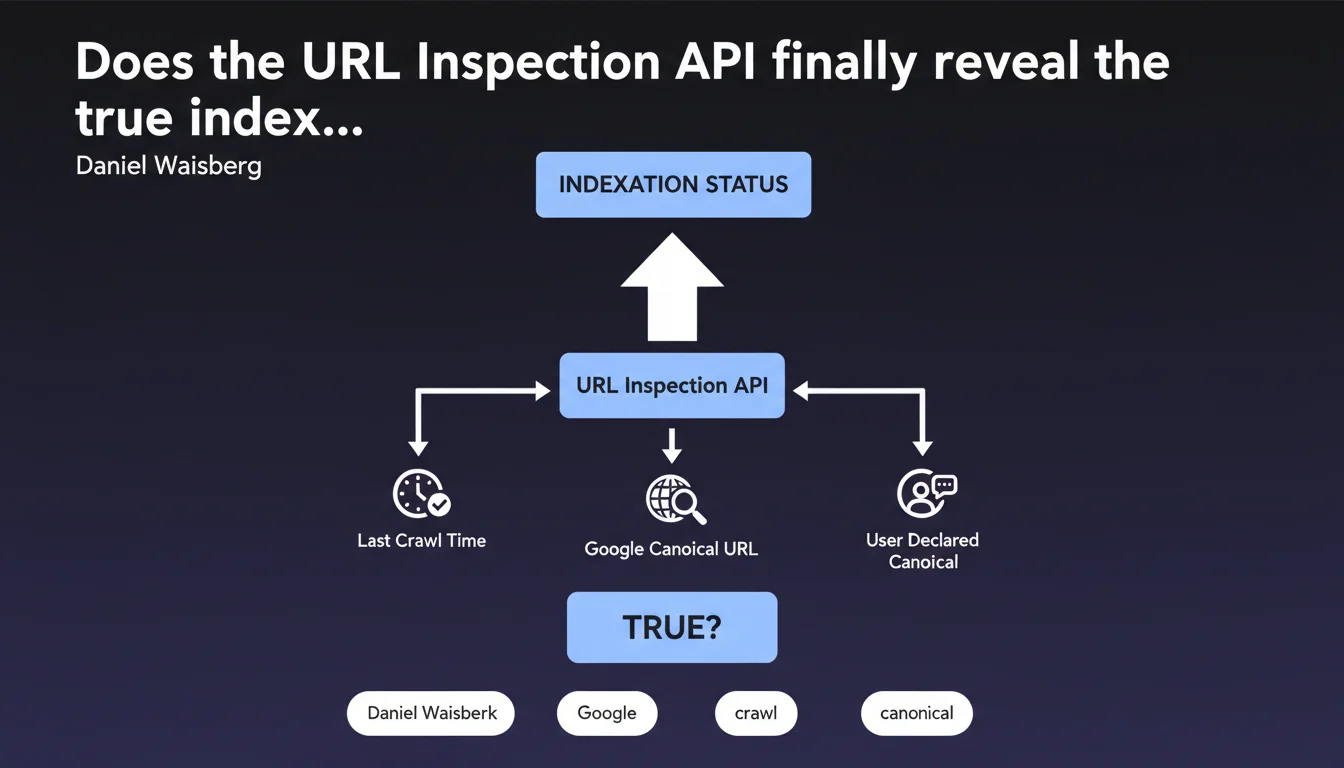
Google's URL Inspection API now allows programmatic access to critical data: real indexation status, last crawl date, canonical URL selected by Google versus the one you declared. For large-scale SEO audits, it's a game changer — but watch out for discrepancies between what Google says it's indexing and what it actually indexes.
What you need to understand
What does this API really reveal about indexation?
The URL Inspection API provides access to the same information as the manual Search Console tool, but programmatically. Concretely: indexation status (indexed or not), timestamp of the last crawl, canonical URL selected by Google, and the one you declared via rel=canonical.
The real value? The ability to automate the audit of thousands of URLs to detect gaps between intention and reality. Is Google really indexing your strategic pages? Does it respect your canonicals? The API answers factually.
Why does the last crawl date change the game?
Knowing when Google last explored a URL allows you to diagnose crawl budget or freshness issues. An important page crawled 3 months ago? Red flag.
Combined with indexation status, this data allows you to identify crawled but not indexed URLs — often a symptom of weak content, duplicates or blocked by unintended directives.
The canonical gap: can we finally detect conflicts at scale?
The API exposes two values: the canonical declared by the site and the one selected by Google. When they diverge, it means Google ignored your directive — often for good reasons (duplicate detected, inaccessible canonical, inconsistency).
Monitoring these gaps in bulk becomes possible. No need to manually check each URL anymore: a script can now map all canonical conflicts on the site in minutes.
- Programmatic access to indexation, crawl and canonicalization data
- Precise timestamp of Googlebot's last visit to each URL
- Automated detection of discrepancies between declared and retained canonical
- Ability to audit thousands of URLs without manual intervention
- Diagnosis of crawled but not indexed pages at scale
SEO Expert opinion
Does this API really tell the whole truth about indexation?
Let's be honest: the URL Inspection API reflects what Google thinks it has indexed at a given moment. It doesn't guarantee that the URL will appear in search results. [To verify]: the data may be a few hours or even days behind depending on the freshness of the Search Console cache.
Another rarely mentioned limitation — the API has strict quotas (600 requests per minute by default). For a site with hundreds of thousands of URLs, a complete audit takes time and requires intelligent request orchestration.
Do canonical gaps always reveal a problem?
Not necessarily. Google may legitimately ignore a directive if it points to a URL that is inaccessible, redirected or inconsistent with the content. The gap isn't systematically your fault.
What matters? Analyze why Google diverges. A pattern of massive gaps across a specific page type (product sheets, pagination) often signals a poorly designed architecture or contradictory directives (canonical + noindex, for example).
Is the last crawl time a good proxy for the priority Google gives a page?
Yes and no. A recently crawled page isn't necessarily judged as important — Google may simply be following internal links. Conversely, some stable and authoritative pages are crawled less often because their content changes infrequently.
The real signal? Compare the last crawl with the actual last modification date of the content. If you publish critical updates and Google doesn't return within 15 days, that's when you need to investigate (sitemap, internal linking, robots.txt).
Practical impact and recommendations
How do you integrate this API into an SEO audit workflow?
First step: automate the extraction of indexation data for all strategic URLs (categories, product sheets, editorial content). A Python or Node.js script is enough — Google provides official client libraries.
Next, cross-reference this data with your XML sitemap and server logs. URLs present in the sitemap but marked "not indexed" by the API? Quality or directive issue. URLs absent from the sitemap but indexed? Potentially unwanted duplicate.
What indicators should you prioritize?
Focus on three key metrics: the ratio of indexed URLs versus submitted, the temporal distribution of last crawls (identifying neglected site areas), and the canonical gap rate by page type.
A monthly dashboard is enough for most sites. For e-commerce platforms or content aggregators, weekly or even daily monitoring may be necessary — especially after migrations or redesigns.
What mistakes should you avoid when exploiting this data?
Don't panic if 100% of your URLs aren't indexed. Google is selective by nature — deep pagination, parametric variants or content deemed redundant are legitimately excluded.
Another trap: confusing "not indexed" and "deindexed". The API indicates the current status, not history. A URL may be temporarily excluded due to server load or saturated crawl budget, then reindexed a few days later.
- Configure OAuth authentication for the Search Console API
- Automate data extraction for strategic URLs (top landing pages, new publications)
- Create a dashboard cross-referencing API, sitemap and server logs
- Monitor canonical gaps by page type (products, categories, content)
- Compare last crawl with the actual last modification date of content
- Investigate "crawled but not indexed" URLs — often duplicates or thin content
- Respect API quotas to avoid throttling (600 req/min by default)
- Don't confuse current status with trend: analyze over several weeks
❓ Frequently Asked Questions
L'API URL Inspection remplace-t-elle l'outil manuel de la Search Console ?
Quelle est la fréquence de mise à jour des données dans l'API ?
Peut-on forcer une réindexation via l'API ?
Les écarts entre canonique déclarée et sélectionnée sont-ils toujours problématiques ?
Combien d'URLs peut-on vérifier par jour avec l'API ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 26/04/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.