Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi l'API Search Console révèle 50 fois plus de données que l'interface standard ?
- □ L'API Search Analytics peut-elle remplacer l'interface Search Console pour piloter votre SEO ?
- □ L'API URL Inspection peut-elle vraiment remplacer les tests manuels d'indexation ?
- □ Comment exploiter l'API URL Inspection pour détecter les écarts entre canonical déclaré et canonical Google ?
- □ Peut-on vraiment déboguer les données structurées à grande échelle avec l'API URL Inspection ?
- □ Faut-il surveiller vos sitemaps via l'API dédiée de Google ?
- □ Pourquoi combiner l'API Search Console avec d'autres sources de données SEO ?
- □ L'API Sites de Search Console peut-elle vraiment simplifier la gestion de vos propriétés ?
- □ Faut-il vraiment passer par les bibliothèques clientes pour exploiter l'API Search Console ?
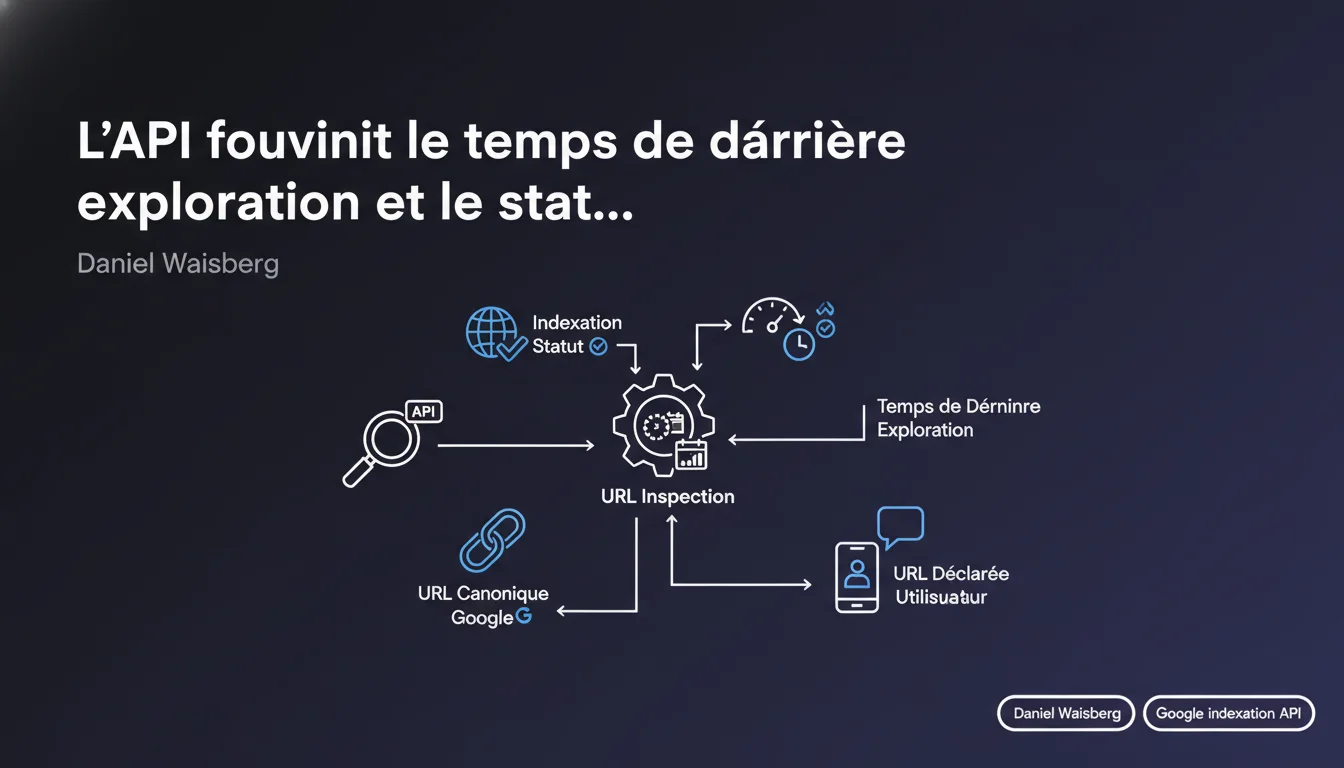
L'API URL Inspection de Google permet désormais d'accéder programmatiquement à des données critiques : statut d'indexation réel, date de dernier crawl, URL canonique choisie par Google versus celle déclarée. Pour les audits SEO à grande échelle, c'est un game changer — mais attention aux écarts entre ce que Google dit indexer et ce qu'il indexe vraiment.
Ce qu'il faut comprendre
Que révèle réellement cette API sur l'indexation ?
L'API URL Inspection donne accès aux mêmes informations que l'outil manuel de la Search Console, mais de manière programmatique. Concrètement : statut d'indexation (indexée ou non), horodatage du dernier crawl, URL canonique sélectionnée par Google, et celle que vous avez déclarée via le rel=canonical.
La vraie valeur ? La possibilité d'automatiser l'audit de milliers d'URLs pour détecter des écarts entre intention et réalité. Google indexe-t-il vraiment vos pages stratégiques ? Respecte-t-il vos canoniques ? L'API répond factuellement.
Pourquoi la date de dernier crawl change la donne ?
Savoir quand Google a exploré une URL pour la dernière fois permet de diagnostiquer des problèmes de crawl budget ou de fraîcheur. Une page importante crawlée il y a 3 mois ? Signal d'alerte.
Couplée au statut d'indexation, cette donnée permet de repérer les URLs crawlées mais non indexées — souvent symptôme de contenu faible, duplicate ou bloqué par des directives involontaires.
L'écart canonique : détecte-t-on enfin les conflits à grande échelle ?
L'API expose deux valeurs : la canonique déclarée par le site et celle sélectionnée par Google. Quand elles divergent, c'est que Google a ignoré votre directive — souvent pour de bonnes raisons (duplicate détecté, canonique inaccessible, incohérence).
Surveiller ces écarts en masse devient possible. Plus besoin de checker manuellement chaque URL : un script peut désormais cartographier tous les conflits canoniques du site en quelques minutes.
- Accès programmatique aux données d'indexation, crawl et canonicalisation
- Horodatage précis du dernier passage de Googlebot sur chaque URL
- Détection automatisée des écarts entre canonique déclarée et canonique retenue
- Possibilité d'auditer des milliers d'URLs sans intervention manuelle
- Diagnostic des pages crawlées mais non indexées à grande échelle
Avis d'un expert SEO
Cette API dit-elle vraiment toute la vérité sur l'indexation ?
Soyons honnêtes : l'API URL Inspection reflète ce que Google pense avoir indexé à un instant T. Elle ne garantit pas que l'URL apparaîtra dans les résultats de recherche pour autant. [À vérifier] : les données peuvent avoir quelques heures voire jours de retard selon la fraîcheur du cache de la Search Console.
Autre limite rarement évoquée — l'API a des quotas stricts (600 requêtes par minute par défaut). Pour un site de plusieurs centaines de milliers d'URLs, l'audit complet prend du temps et nécessite une orchestration intelligente des requêtes.
Les écarts canoniques révèlent-ils toujours un problème ?
Pas nécessairement. Google peut légitimement ignorer une directive canonique si elle pointe vers une URL inaccessible, redirigée ou incohérente avec le contenu. L'écart n'est pas systématiquement une erreur de votre part.
Ce qui compte ? Analyser pourquoi Google diverge. Un pattern d'écarts massifs sur une typologie de pages précise (fiches produits, paginations) signale souvent une architecture mal pensée ou des directives contradictoires (canonical + noindex, par exemple).
Le temps de dernier crawl est-il un bon proxy de la priorité accordée par Google ?
Oui et non. Une page crawlée récemment n'est pas forcément jugée importante — Google peut simplement suivre des liens internes. Inversement, certaines pages stables et autoritaires sont crawlées moins souvent parce que leur contenu évolue peu.
Le vrai signal ? Comparer le dernier crawl avec la date de dernière modification réelle du contenu. Si vous publiez une mise à jour critique et que Google ne repasse pas sous 15 jours, c'est là qu'il faut investiguer (sitemap, internal linking, robots.txt).
Impact pratique et recommandations
Comment intégrer cette API dans un workflow d'audit SEO ?
Première étape : automatiser l'extraction des données d'indexation pour toutes les URLs stratégiques (catégories, fiches produits, contenus éditoriaux). Un script Python ou Node.js suffit — Google fournit des bibliothèques clientes officielles.
Ensuite, croiser ces données avec votre sitemap XML et vos logs serveur. Les URLs présentes dans le sitemap mais marquées "non indexées" par l'API ? Problème de qualité ou de directives. Les URLs absentes du sitemap mais indexées ? Potentiellement du duplicate non voulu.
Quels indicateurs surveiller en priorité ?
Focus sur trois métriques clés : le taux d'URLs indexées versus soumises, la distribution temporelle des derniers crawls (repérer les zones du site délaissées), et le taux d'écart canonique par typologie de page.
Un tableau de bord mensuel suffit pour la plupart des sites. Pour les plateformes e-commerce ou les agrégateurs de contenu, un monitoring hebdomadaire voire quotidien peut s'avérer nécessaire — surtout après des migrations ou refontes.
Quelles erreurs éviter lors de l'exploitation de ces données ?
Ne paniquez pas si 100% de vos URLs ne sont pas indexées. Google est sélectif par nature — les paginations profondes, variantes paramétriques ou contenus jugés redondants sont légitimement exclus.
Autre piège : confondre "non indexé" et "désindexé". L'API indique le statut actuel, pas l'historique. Une URL peut être temporairement exclue pour cause de charge serveur ou de budget de crawl saturé, puis réindexée quelques jours plus tard.
- Configurer l'authentification OAuth pour l'API Search Console
- Automatiser l'extraction des données pour les URLs stratégiques (top landing pages, nouvelles publications)
- Créer un tableau de bord croisant API, sitemap et logs serveur
- Surveiller les écarts canoniques par typologie de page (produits, catégories, contenus)
- Comparer le dernier crawl avec la date de dernière modification réelle du contenu
- Investiguer les URLs "crawlées mais non indexées" — souvent du duplicate ou du thin content
- Respecter les quotas API pour éviter les blocages (600 req/min par défaut)
- Ne pas confondre statut ponctuel et tendance : analyser sur plusieurs semaines
❓ Questions frequentes
L'API URL Inspection remplace-t-elle l'outil manuel de la Search Console ?
Quelle est la fréquence de mise à jour des données dans l'API ?
Peut-on forcer une réindexation via l'API ?
Les écarts entre canonique déclarée et sélectionnée sont-ils toujours problématiques ?
Combien d'URLs peut-on vérifier par jour avec l'API ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 26/04/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.