Official statement
Other statements from this video 19 ▾
- □ Should you panic if your hreflang disappears temporarily during a migration?
- □ Should you block GoogleOther or risk disrupting your Google services?
- □ Do local domains (ccTLD) really offer an SEO advantage for local search rankings?
- □ Does Google really treat a site after massive expansion as a brand new website?
- □ Why does Google keep displaying your old site name in search results long after a rebrand?
- □ Should you really fix every single indexation error Google reports in Search Console?
- □ How can you leverage the Google Search Status Dashboard API to supercharge your SEO tools?
- □ Why aren't your product structured data appearing in Google's rich results?
- □ Why does Google refuse to grant unlimited indexation request quotas in Search Console?
- □ Is your brand really stuck being confused with a common word? How long does Google actually need to figure it out?
- □ Is Schema Recipe really restricted to food recipes only, or can you use it creatively?
- □ Can Google actually transfer your SEO rankings during a domain migration?
- □ Does the noindex tag really only affect individual pages, or can it impact your entire site?
- □ Do you really need to fill in every single field of structured data for Google to actually use it?
- □ Does Google really use RSS feeds to discover and index new content on your site?
- □ Why is your new favicon taking so long to appear in Google search results?
- □ Does the order of H1, H2, H3 tags really affect your Google rankings?
- □ Do links on crawl-blocked pages really lose all their SEO value?
- □ Does Google really require a specific sitemap structure, or can you organize them however you want?
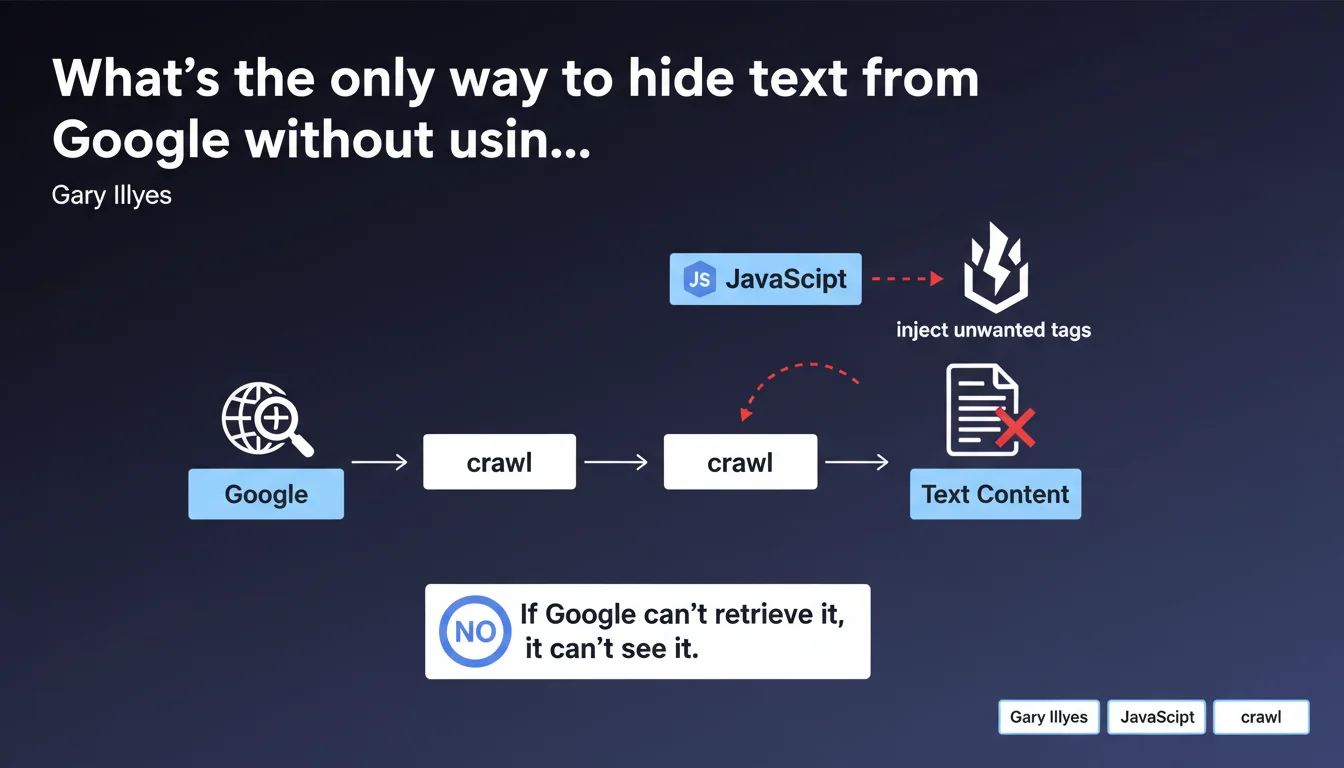
Google offers no HTML tag or annotation to ignore specific text. The only workaround is to inject content via JavaScript and block crawling of that JS file through robots.txt or another restriction method. If Googlebot can't fetch the JavaScript, it will never see the content it generates.
What you need to understand
Why would you want to hide text from Google?
There are legitimate situations where a website needs to display content to users without Google indexing it. Think of redundant contact information appearing in the footer of every page, repetitive legal notices, or dynamically generated content that could dilute a page's semantic relevance.
The problem? HTML has no built-in mechanism to say "index this part, skip that one." There's no noindex at the block level, no magic attribute signaling Googlebot to move along. The engine indexes everything it sees in the final DOM, period.
What's the workaround technique Google acknowledges?
The solution involves injecting unwanted content via JavaScript and blocking access to that JS file in robots.txt or via an HTTP 403/401 response. If Googlebot can't load the script, it will never see the text that script generates.
In practice: the base HTML contains no problematic content. An external JavaScript file (or a blocked inline script) handles it. Google crawls the page, sees it can't retrieve the JS, and settles for the raw HTML — without the injected text.
What are the implications for site architecture?
This approach requires rethinking how content is distributed between static HTML and JavaScript rendering. It creates a clear distinction between "SEO content" (pure HTML) and "user-only content" (blocked JS).
- Content critical for SEO must be in the initial HTML, never injected by JavaScript
- Repetitive or secondary elements can be moved to a blocked script
- You need to maintain two rendering logics: one for Googlebot (HTML only), one for real users (HTML + JS)
- This technique only works if Google is genuinely prevented from loading the JavaScript in question
- Watch out for unintentional cloaking: if user experience differs too much from what Google sees, that's risky
SEO Expert opinion
Is this method really advisable in practice?
Let's be honest — it's a hack. Google confirms there is no clean, native solution to hide text at the HTML level. This reveals a gap in web standards, but it doesn't make this technique elegant either.
The main risk? Creating a divergence between user experience and what Googlebot perceives. If the hidden content is purely cosmetic (a widget, a counter), no problem. But if it involves substantial text blocks, you're walking a fine line between optimization and cloaking.
In what scenarios does this approach make sense?
Legitimate scenarios are rare but exist. A typical example: an e-commerce site with thousands of product pages sharing the same verbose footer containing contact details, hours, detailed legal notices. This text pollutes each page's semantic signal.
Another case: application interfaces where certain navigation or contextual help elements have no SEO value but are essential for UX. There, injecting via blocked JS keeps HTML clean for crawlers.
[To verify] Google doesn't clarify whether this technique could be interpreted as manipulative in certain contexts. The lack of clear guidelines leaves a gray area — at your own risk.
What are less risky alternatives?
Before blocking JavaScript, first explore classic options. Use iframe to isolate content (Google doesn't always crawl iframes the same way). Or externalize repetitive content into dedicated noindex pages.
Another approach: optimize your semantic architecture so "parasite" content becomes minimal compared to unique page content. No need to hide it if the signal-to-noise ratio stays good.
Practical impact and recommendations
What exactly should you do to hide text from Google?
The method relies on precise technical implementation. First, identify content blocks to hide — ensure they're truly non-critical for SEO. Next, create a dedicated JavaScript file that will inject this content into the DOM client-side.
Then add a line to your robots.txt like Disallow: /js/blocked-content.js. Verify through Search Console that Googlebot encounters a 403 error or doesn't load the file. Test final rendering with the URL inspection tool to confirm the content doesn't appear in the crawled version.
What mistakes should you absolutely avoid?
Never block JavaScript containing critical SEO content. If your main text, your H1s, your product descriptions are generated by a blocked script, you're sabotaging your indexation. Google will see an empty or truncated page.
Another trap: creating a degraded user experience by accident. If your JS is blocked for Google but also for certain browsers or users (ad blockers, corporate restrictions), you risk breaking the display for part of your audience.
- Precisely identify non-SEO content to hide (repetitive footers, widgets, redundant legal notices)
- Create a dedicated JavaScript file to inject this content client-side
- Block this JS file via
robots.txtor a server restriction (403/401) - Test rendering in Search Console to verify Google doesn't see the injected content
- Document this approach internally to prevent a developer from "fixing" the block by mistake
- Monitor indexation metrics to detect any unexpected side effects
How can you verify the implementation is working correctly?
Use the URL inspection tool in Search Console. Compare the HTML rendered visible to Googlebot and the version displayed in your browser. The hidden content must be absent from Google's version, present on the user side.
Also check your server logs to confirm Googlebot attempts to access the JS file and receives a blocking response (403, 401, or Disallow respected). If the file loads, the technique fails.
❓ Frequently Asked Questions
Peut-on utiliser l'attribut aria-hidden pour masquer du texte à Google ?
Bloquer du JavaScript via robots.txt peut-il nuire au crawl budget ?
Cette technique fonctionne-t-elle avec du contenu injecté en Ajax ?
Google peut-il considérer cette méthode comme du cloaking ?
Faut-il bloquer tout le fichier JavaScript ou peut-on bloquer seulement une fonction ?
🎥 From the same video 19
Other SEO insights extracted from this same Google Search Central video · published on 18/07/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.