Official statement
Other statements from this video 11 ▾
- □ 301 vs 302 : les redirections temporaires font-elles vraiment perdre du PageRank ?
- □ Pourquoi les redirections 307 et 308 sont-elles inutiles pour le SEO classique ?
- □ Faut-il vraiment abandonner les meta refresh pour vos redirections ?
- □ Les redirections JavaScript sont-elles réellement suivies par Google ?
- □ Faut-il vraiment rediriger chaque URL individuellement lors d'une migration de domaine ?
- □ Pourquoi les fusions et divisions de domaines provoquent-elles des fluctuations SEO prolongées ?
- □ Faut-il abandonner les redirections géographiques pour préserver votre crawl budget ?
- □ Les interstitiels avec redirections bloquent-ils vraiment Googlebot ?
- □ Faut-il vraiment des redirections bidirectionnelles entre versions mobile et desktop pour éviter les problèmes d'indexation ?
- □ Pourquoi l'URL Inspection Tool affiche-t-il un code 200 même après redirection ?
- □ Faut-il vraiment utiliser des redirections 302 entre les versions mobile et desktop ?
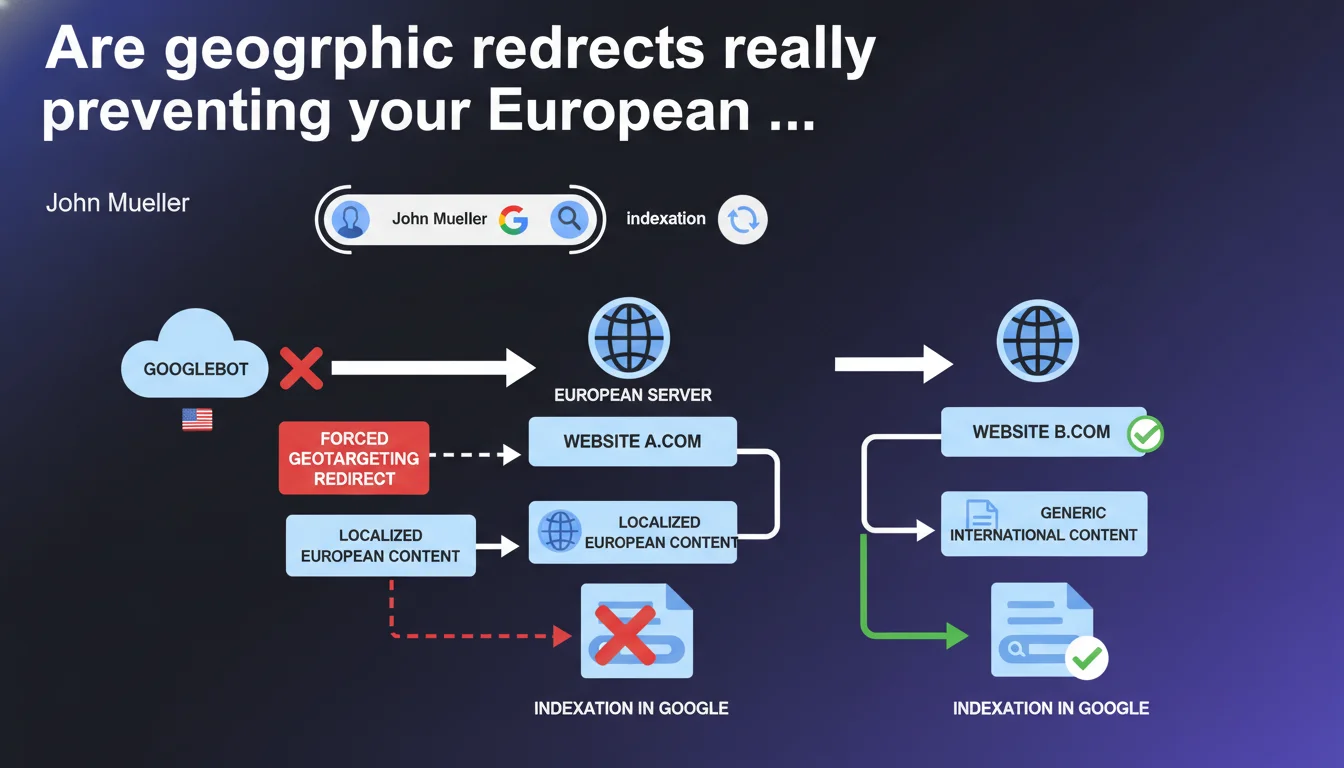
Googlebot crawls predominantly from the United States, even to index European websites. If your geographic redirects block US access to your European content, Google won't be able to index it. Server-based geolocation can therefore create a critical blind spot in your indexation strategy.
What you need to understand
Why does Googlebot crawl from the United States for European websites?
Google centralizes a significant portion of its crawl infrastructure in the United States to optimize its resources and maintain consistency in global indexation. Even though Google has datacenters distributed worldwide, the primary crawl — the one that determines initial indexation — is often performed from American IP addresses.
This technical configuration creates a paradox: your website can be perfectly accessible to your European users while remaining invisible to the bot that needs to index it. This is particularly problematic for multi-country e-commerce sites that implement automatic redirects based on IP geolocation.
How do geographic redirects concretely block indexation?
A typical geographic redirect detects the origin of the request (via IP) and sends the user to the appropriate local version. If a US visitor tries to access yoursite.fr/european-product, they'll be redirected to yoursite.com/us-version.
The problem? Googlebot arrives with an American IP address. It follows the redirect and never accesses the original European content. Result: the European page never enters the index, or worse, it's replaced by the US version in French search results.
What are the at-risk configurations?
- Automatic 301/302 redirects based solely on connection IP with no bypass option
- Strict server-side geolocation that outright blocks access from certain regions
- Multi-country sites without hreflang combined with forced redirects — double trouble for indexation
- Server-side IP detection (Apache/Nginx) without fallback for specific user-agents
- CDN with strict geo-routing configured without exceptions for Googlebot
SEO Expert opinion
Is this statement consistent with field observations?
Absolutely. I've observed this phenomenon many times on international websites. The classic case: a .fr site that systematically redirects US IPs to a .com, and whose French pages gradually disappear from the index despite quality content.
What often surprises technical teams is that Search Console doesn't explicitly flag this type of blocking. Pages simply appear as "discovered but not indexed" without clear explanation. You have to cross-reference server logs with indexation reports to identify the pattern.
What nuances should be added to this claim?
Google doesn't crawl exclusively from the US, but the proportion is high enough that it should be the default behavior to anticipate. [To verify] the exact distribution varies by region and website type — Google has never communicated precise figures.
Another often-overlooked point: even if Googlebot manages to access your content through a workaround path (sitemap, internal link from a non-redirected page), the degraded crawl experience can affect your crawl budget and slow down indexation. A page that's accessible but difficult to reach will be updated less frequently.
In what cases doesn't this rule apply completely?
If you use client-side JavaScript redirects rather than server-side ones, Googlebot can technically access the initial content before the redirect executes. But this solution introduces other problems: rendering latency, inconsistency between mobile and desktop crawls, impact on Core Web Vitals.
Sites that correctly implement hreflang annotations combined with user-agent detection can allow Googlebot to access all versions while redirecting actual users. It's technically cleaner, but requires careful server configuration.
Practical impact and recommendations
How can you verify if your redirects are blocking Googlebot?
First step: test access to your European URLs from an American IP address. Use a VPN or geolocation testing service, and observe the redirect behavior. If you're systematically sent to a US/international version, that's what Googlebot experiences.
Second diagnosis: analyze your server logs by filtering Googlebot requests. Check which URLs are actually crawled and compare with your strategic European pages. A significant gap indicates an accessibility problem.
Third verification: in Search Console, examine the "Coverage" report for pages marked "Discovered - currently not indexed". Cross-reference this list with your geo-redirected pages. If they're overrepresented, you have your answer.
What technical solution should you prioritize?
The optimal configuration combines several elements. First, implement server-side user-agent detection that explicitly allows Googlebot (and Bingbot, etc.) to access all versions without forced redirect.
Next, deploy correctly configured hreflang tags on all your international pages. Googlebot can then understand the multi-country structure and display the right version based on search language/region, even when crawling from the US.
Finally, rather than 301/302 server redirects, prefer a JavaScript suggestion banner: "You appear to be in France, would you prefer the French version?". Users retain control, and Googlebot accesses the original content without obstruction.
- Audit geographic redirect rules in server configuration (Apache .htaccess, Nginx conf, CDN rules)
- Whitelist search engine user-agents to avoid forced redirects
- Verify the presence and validity of hreflang tags on all international versions
- Test access to critical URLs via IPs from different countries (US, UK, DE, etc.)
- Analyze logs to confirm that Googlebot actually crawls the European versions
- Implement a suggestion solution rather than automatic redirect for UX
- Monitor indexation of geo-specific pages in Search Console after modifications
❓ Frequently Asked Questions
Peut-on simplement whitelister les IPs de Googlebot pour résoudre le problème ?
Les balises hreflang suffisent-elles sans modifier les redirections ?
Une redirection JavaScript côté client évite-t-elle le problème ?
Comment savoir si mes pages européennes sont effectivement bloquées ?
Cette problématique concerne-t-elle aussi les sites mono-pays avec versions linguistiques ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 17/11/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.