Official statement
Other statements from this video 9 ▾
- □ Pourquoi Googlebot signale-t-il des soft 404 sur vos pages géolocalisées vides ?
- □ Le cloaking géolocalisé est-il vraiment acceptable pour Google ?
- □ Afficher du contenu national par défaut est-il considéré comme du cloaking par Google ?
- □ Le cloaking est-il vraiment un problème si l'utilisateur n'est pas trompé ?
- □ Faut-il attendre avant de juger l'impact d'une mise à jour algorithmique Google ?
- □ Pourquoi l'analyse des fichiers logs est-elle indispensable pour les gros sites ?
- □ Pourquoi une page vide détruit-elle votre expérience utilisateur et votre SEO ?
- □ Comment garantir une expérience cohérente avec les attentes utilisateur sans risquer une pénalité pour cloaking ?
- □ Faut-il vraiment comparer l'état réel des pages avant et après une baisse de trafic ?
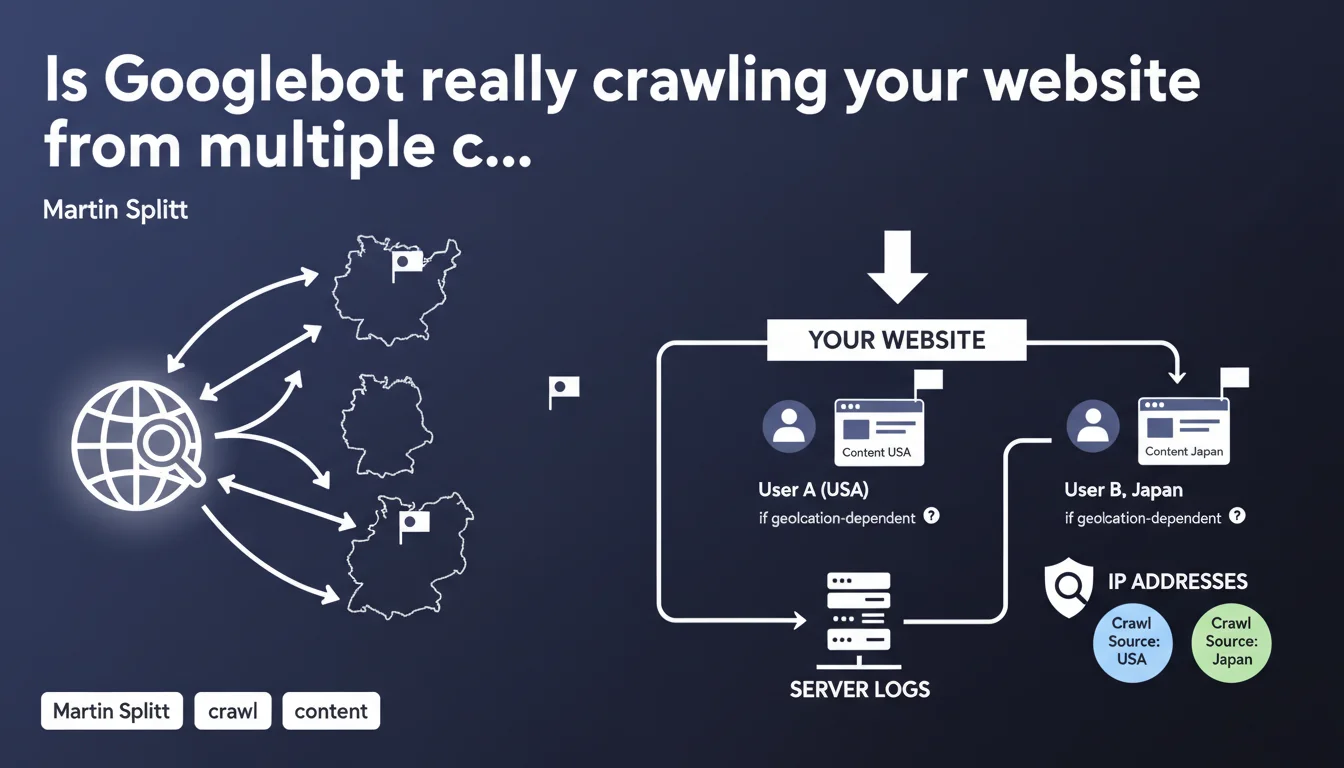
Googlebot doesn't crawl solely from the United States—it can access your pages from different geographical locations. If your site adapts its content based on user geolocation, Google risks indexing different versions depending on where the crawl originates. Checking IP addresses in your logs becomes an essential step to understand what Google actually sees.
What you need to understand
Why does Google crawl from multiple countries?
Google no longer limits its web exploration to a single centralized datacenter. Googlebot now distributes its crawling across multiple geographic zones, allowing it to better understand how sites adapt their content based on visitor location.
This approach addresses a simple reality: many websites serve different content depending on the user's country of origin. Automatic redirection to a local version, displaying prices in local currency, modifying available products—these are all common practices that Google now wants to capture accurately.
What are the concrete consequences for indexation?
The problem becomes obvious when you think about it: if your site serves different content based on geolocation, Google can index contradictory versions of your pages. A crawl from the United States will see one thing, a crawl from Germany will see another.
Martin Splitt emphasizes one specific point: analyzing IP addresses in your server logs is no longer optional. It's the only reliable way to identify where Googlebot's crawl actually originates from and therefore what content was indexed.
How do you identify the geographical origin of the crawl?
Server logs contain the IP addresses of every request made by Googlebot. By cross-referencing these IPs with their geographical location, you can determine from which country Google accessed each page.
This information becomes critical for diagnosing indexation inconsistencies. If a page doesn't appear in search results as expected, checking the crawl origin can reveal that Google indexed an unintended geolocation-based version.
- Googlebot crawls from multiple geographical locations, not just from the United States
- Sites with geolocation-dependent content can be indexed differently depending on the crawl origin
- IP address analysis in logs allows you to identify the exact source of the crawl
- Google's practice aims to better understand content variations based on location
- Without log verification, it's impossible to know which version of your content Google actually indexed
SEO Expert opinion
Does this statement match real-world observations?
Yes, and it's not a recent development. SEO professionals who regularly analyze their server logs have observed Googlebot appearing with IP addresses from different countries for several years now. What's changing is that Google is officially clarifying it.
Martin Splitt remains vague on one essential point: how does Google decide from which location to crawl a given page? [To verify] There's no information on frequency, selection logic, or whether certain pages are systematically crawled from multiple locations. This opacity complicates planning.
What real risks exist for international sites?
The main danger concerns sites that automatically redirect based on IP without offering an alternative. If Googlebot crawls from France and you systematically redirect to /fr/, the English or German version risks never being properly indexed.
Another problematic case: sites displaying radically different content based on geolocation (prices, product availability, legal notices). Google can index a version that doesn't match your primary target. Let's be honest—many e-commerce sites fall into this trap without even realizing it.
Should you treat Googlebot differently based on its origin?
No, and that's precisely the mistake to avoid. Serving different content to Googlebot based on its IP constitutes cloaking, a practice explicitly penalized by Google. The goal should be to show all crawls the same structure, using hreflang to indicate language variants instead.
The real question becomes: how do you ensure Google crawls all your international versions properly? The answer lies in clear technical architecture (dedicated subdomains or subdirectories), correct hreflang tags, and above all—the absence of automatic redirects based solely on IP.
Practical impact and recommendations
How do you verify where Googlebot is crawling your site from?
First step: enable and analyze your server logs. You need to see the exact IP addresses of requests made by Googlebot. Tools like Oncrawl, Botify, or custom scripts allow you to cross-reference these IPs with their geolocation.
Concretely? Export your logs, filter for Googlebot user-agents, retrieve the IPs, then use a geolocation database (MaxMind for example) to identify their origin. If you notice crawls from countries you don't target, investigate why.
What errors should you avoid with geolocation-dependent content?
Never automatically redirect based on IP without offering a visible alternative. Google must be able to access all your language/regional versions without being forced to a single one. Instead, use a banner suggesting a version change, or an accessible language selector.
Also avoid completely blocking certain sections of your site based on geolocation. If a product isn't available in France, it's better to display a page with a clear mention rather than a 403 or redirect to the homepage.
What should you do if Google indexes the wrong version of your pages?
First check your hreflang tags—they must point correctly to all variants of each page. Then verify in your logs what content Googlebot actually receives based on its geographical origin.
If you find inconsistencies, manually test accessing your pages from different locations (VPN, proxies). Compare what you see with what appears in Google's index through localized searches (the &gl= parameter in the URL).
- Enable detailed server log recording with user-agent and IP
- Regularly analyze the geolocation of Googlebot IP addresses
- Verify that all your regional/language versions are accessible without forced redirection
- Properly implement hreflang tags on all page variants
- Test access to your pages from different geographical locations
- Compare the content served with what appears in Google's index by country
- Avoid any blocking or content modification based solely on IP
- Document legitimate content variations (prices, availability) transparently
❓ Frequently Asked Questions
Googlebot crawle-t-il toutes mes pages depuis plusieurs pays ?
Dois-je autoriser tous les pays dans mon pare-feu pour Googlebot ?
Les redirections 302 géolocalisées posent-elles problème ?
Comment savoir quelle version de ma page Google a indexée ?
Est-ce que Search Console indique d'où provient le crawl ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 13/12/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.