Official statement
Other statements from this video 20 ▾
- □ Les liens internes dans le header ou le footer ont-ils moins de valeur SEO ?
- □ Google pénalise-t-il vraiment un site qui achète des liens en masse ?
- □ Faut-il vraiment viser la perfection technique pour bien ranker sur Google ?
- □ Pourquoi Google crawle-t-il moins votre site s'il le trouve de mauvaise qualité ?
- □ Le statut « Crawlée, actuellement non indexée » est-il vraiment un signal de qualité insuffisante ?
- □ Les données structurées invalides peuvent-elles pénaliser votre référencement ?
- □ Faut-il s'inquiéter d'une baisse du nombre de pages indexées ?
- □ Peut-on vraiment contrôler les images affichées dans les snippets Google ?
- □ Pourquoi Google pénalise-t-il le contenu dupliqué entre sites de franchises ?
- □ CCTLD, sous-domaine ou sous-répertoire : quelle structure pour le géociblage international ?
- □ Le code 503 protège-t-il vraiment vos pages de la désindexation en cas de panne ?
- □ Les liens dofollow accidentels dans vos RP vont-ils vous pénaliser ?
- □ Peut-on vraiment utiliser l'outil de changement d'adresse pour fusionner ou diviser des sites ?
- □ Pourquoi vos données structurées disparaissent-elles sur vos pages localisées ?
- □ Les données structurées améliorent-elles vraiment le référencement ou juste l'affichage ?
- □ Google va-t-il un jour afficher les Core Web Vitals directement dans les résultats de recherche ?
- □ Restructuration d'URL : pourquoi Google provoque-t-il des fluctuations pendant deux mois ?
- □ Le linking interne surpasse-t-il vraiment la structure d'URL pour le SEO ?
- □ Faut-il vraiment calculer le PageRank interne pour optimiser son site ?
- □ Google peut-il vraiment identifier la langue principale d'une page multilingue sans pénaliser votre SEO ?
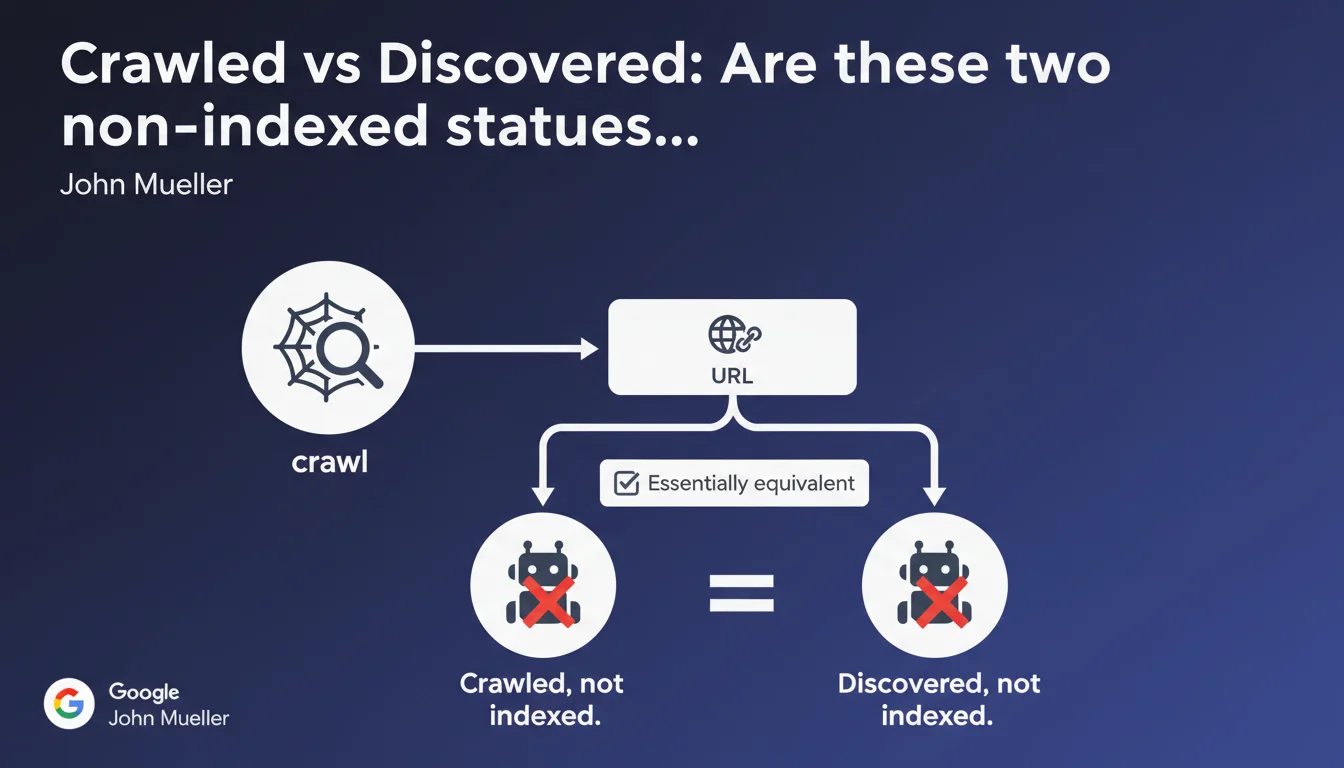
Google treats 'Crawled, not indexed' and 'Discovered, not indexed' as two equivalent statuses: in both cases, the search engine knows the URL but refuses to index it. The nuance of crawling therefore has no importance on the final indexation decision. What matters is understanding why Google judges the page non-indexable.
What you need to understand
This statement from John Mueller debunks a widespread belief: no, moving from 'Discovered' to 'Crawled' doesn't necessarily bring your URL closer to indexation. Google operates by priorities — crawling a page doesn't mean it deserves a place in the index.
Many SEOs still think a crawled URL has crossed a decisive threshold. Wrong. Crawling is mere information gathering; indexation is an editorial decision based on the perceived value of the page.
What does 'equivalence' between these two statuses really mean?
Concretely, both labels indicate the same thing: Google knows the URL, but doesn't judge it worthy of serving to users. Whether the URL was crawled or simply discovered via a link, the final outcome is identical — it stays out of the index.
The 'Crawled, not indexed' status means that Googlebot fetched the content, analyzed the HTML, extracted signals — and concluded it wasn't worth it. 'Discovered, not indexed' means Google spotted the URL (via sitemap, internal links, backlinks) but didn't even deem it necessary to allocate crawl budget to it.
Why does Google decide not to index these pages?
The reasons are multiple and Google deliberately remains vague. It could be duplicate content, low-value pages (filters, infinite pagination, empty archive pages), lack of site authority, or simply saturation: Google can't index everything.
In some cases, it's a problem of poorly allocated crawl budget. Google spends time on useless URLs while good pages stay ignored. In others, it's structural: too many similar pages without differentiated value.
- 'Crawled, not indexed': Google looked, judged the content, and said no
- 'Discovered, not indexed': Google knows the URL exists but won't even spend resources on it
- The equivalence: both lead to the same result — no organic visibility
- The real issue: understanding why Google refuses indexation, not which status the URL is stuck in
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes — and it's frustrating for many SEOs who hoped crawling means 'almost indexed'. In the field, we regularly observe sites with thousands of crawled URLs never indexed, while others see discovered URLs move straight to the index after a simple mention in a sitemap.
What really matters is the perceived quality of the page. Google doesn't lack crawl budget — it lacks valid reasons to index mediocre content. If your page brings nothing new, it can be crawled a hundred times without ever entering the index.
What nuances should be added?
Pay attention: if Google never crawls a discovered URL, that's also a signal. It could indicate a structural problem (misconfigured robots.txt, chaotic pagination, non-crawlable JavaScript) or lack of authority so severe that Google considers crawling a waste.
Conversely, a crawled then rejected URL means Google took the time to analyze and concluded negatively. That's worse than simply 'not yet crawled' — it's active rejection. [Needs verification]: Google claims both statuses are equivalent, but in practice, a crawled then rejected URL often requires more work (rewriting, consolidation) than a simply ignored URL.
In which cases doesn't this rule apply?
On sites with very high authority, some URLs move directly from 'Discovered' to 'Indexed' without ever showing 'Crawled, not indexed' status. Google trusts by default then. It's rare, but observable on established media or university sites.
Another exception: voluntarily blocked pages (noindex, canonicals pointing elsewhere). They sometimes appear as 'Discovered, not indexed' when it's a deliberate webmaster choice. Google doesn't make the distinction in Search Console — it's up to the SEO to sort it out.
Practical impact and recommendations
What should you do concretely facing these statuses?
First step: identify pages that truly deserve indexation. Not all URLs on your site are meant to be indexed. Faceted filters, empty archive pages, minor content variations — forget them.
For strategic pages stuck in these statuses, two levers: improve the content (added value, originality, depth) and strengthen relevance signals (internal links, external mentions, semantic context).
What mistakes should you avoid?
Classic mistake: multiplying manual indexation requests via Search Console. If Google refuses to index after crawl, it's not a bug — it's a choice. Forcing won't change anything.
Another trap: believing an XML sitemap guarantees indexation. The sitemap is a suggestion, not an order. Google crawls what it wants, when it wants, according to its own value criteria.
How do you diagnose and fix the problem?
Analyze patterns: which page categories are blocked? Filters? Deep pagination? Old articles with no backlinks? Once the pattern is identified, three possible strategies:
- Consolidation: merge similar pages into one richer version
- Voluntary noindex: accept that these pages don't need to be indexed and clean up Search Console
- Enhancement: enrich content, add media, create targeted internal linking, earn backlinks
- Canonicalization: point variations to the main version to concentrate signals
- Structural revision: rethink pagination, filters, hierarchy if the problem affects hundreds of URLs
❓ Frequently Asked Questions
Si une URL passe de « Découverte » à « Crawlée, non indexée », est-ce un bon signe ?
Combien de temps faut-il attendre avant qu'une page découverte soit indexée ?
Peut-on forcer Google à indexer une page bloquée dans ces statuts ?
Faut-il supprimer les pages « Crawlée, non indexée » ou « Découverte, non indexée » ?
Est-ce qu'un sitemap XML aide à faire indexer ces pages ?
🎥 From the same video 20
Other SEO insights extracted from this same Google Search Central video · published on 21/01/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.