Official statement
Other statements from this video 20 ▾
- □ Les liens internes dans le header ou le footer ont-ils moins de valeur SEO ?
- □ Google pénalise-t-il vraiment un site qui achète des liens en masse ?
- □ Faut-il vraiment viser la perfection technique pour bien ranker sur Google ?
- □ Le statut « Crawlée, actuellement non indexée » est-il vraiment un signal de qualité insuffisante ?
- □ Les données structurées invalides peuvent-elles pénaliser votre référencement ?
- □ Faut-il s'inquiéter d'une baisse du nombre de pages indexées ?
- □ Crawlée non indexée vs Découverte non indexée : vraiment équivalent ?
- □ Peut-on vraiment contrôler les images affichées dans les snippets Google ?
- □ Pourquoi Google pénalise-t-il le contenu dupliqué entre sites de franchises ?
- □ CCTLD, sous-domaine ou sous-répertoire : quelle structure pour le géociblage international ?
- □ Le code 503 protège-t-il vraiment vos pages de la désindexation en cas de panne ?
- □ Les liens dofollow accidentels dans vos RP vont-ils vous pénaliser ?
- □ Peut-on vraiment utiliser l'outil de changement d'adresse pour fusionner ou diviser des sites ?
- □ Pourquoi vos données structurées disparaissent-elles sur vos pages localisées ?
- □ Les données structurées améliorent-elles vraiment le référencement ou juste l'affichage ?
- □ Google va-t-il un jour afficher les Core Web Vitals directement dans les résultats de recherche ?
- □ Restructuration d'URL : pourquoi Google provoque-t-il des fluctuations pendant deux mois ?
- □ Le linking interne surpasse-t-il vraiment la structure d'URL pour le SEO ?
- □ Faut-il vraiment calculer le PageRank interne pour optimiser son site ?
- □ Google peut-il vraiment identifier la langue principale d'une page multilingue sans pénaliser votre SEO ?
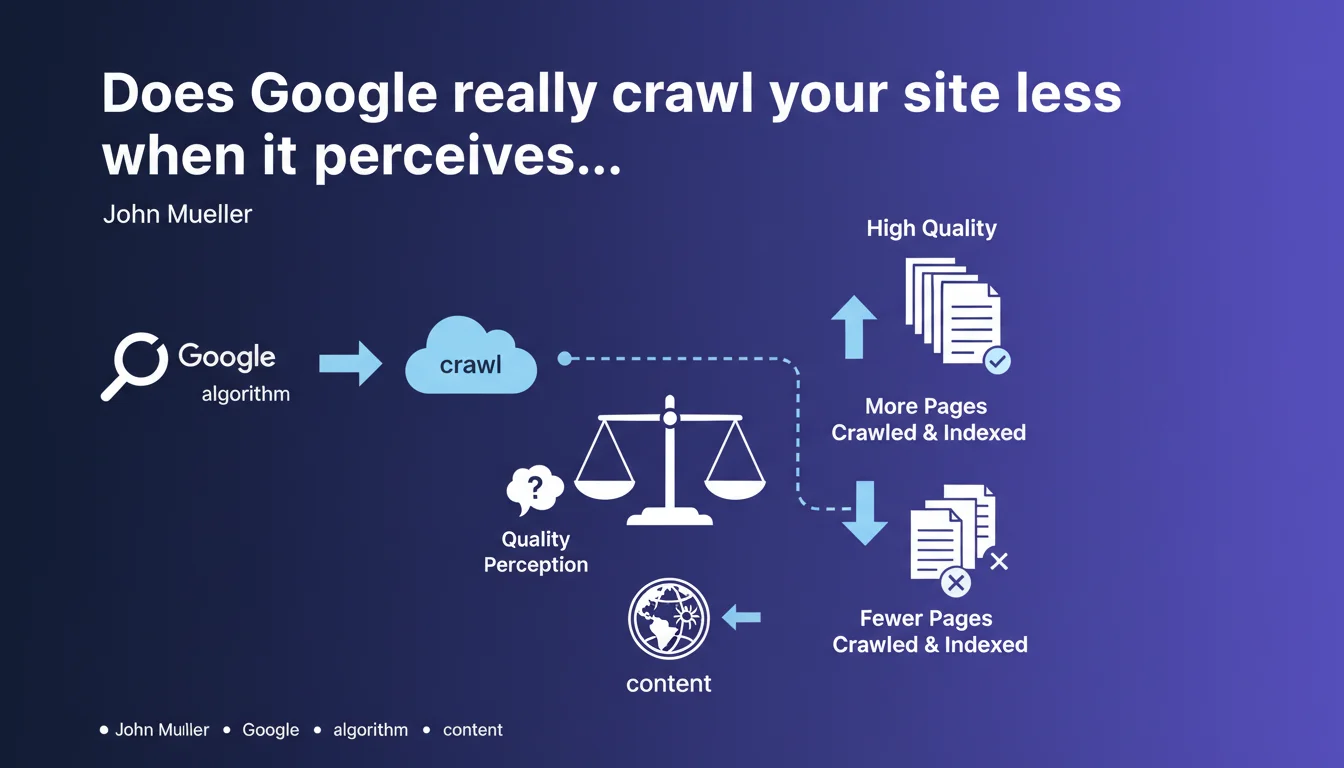
Google prioritizes its crawl budget based on the perceived quality of websites. If algorithms judge your content mediocre, fewer pages will be explored and indexed, even if they're technically accessible. Your site's overall quality directly determines the attention Google gives it.
What you need to understand
What does this really mean for your site?
Google has limited resources — servers, bandwidth, computing power. Crawling the entire web daily is physically impossible. Bots must therefore prioritize.
This prioritization isn't random. It's based on algorithmic evaluation of a site's overall quality: content freshness, bounce rate, engagement signals, perceived expertise, thematic authority. If Google thinks a site produces mostly weak or duplicate content, it reduces crawl frequency and depth.
How does Google evaluate this perceived quality?
The exact criteria remain opaque — it's a black box. We know that behavioral signals intervene (time spent, organic click-through rate), thematic consistency, publication frequency, number of indexed pages versus crawled pages.
A site multiplying auto-generated content, orphan pages, or near-identical variations sends a negative signal. Google then adjusts its crawl budget downward, creating a vicious circle: less crawl → fewer pages discovered → less visibility → degraded quality signal.
Does this limitation affect all types of sites?
No. News sites, dynamic e-commerce platforms with high traffic volumes, established authority sites enjoy near-constant crawling. Google knows they publish fresh, relevant content.
Conversely, small new sites, inactive blogs, sites with a history of thin content or algorithmic penalties suffer severe limitations. Even after correction, restoring normal crawl can take months.
- Crawl budget isn't fixed — it evolves based on the site's algorithmic perception
- Overall quality > isolated page quality — a handful of good pages doesn't compensate for a mass of mediocre content
- Crawl frequency reflects Google's trust — rarely crawled site is an undervalued site
- Reducing indexed page volume can paradoxically improve crawling — less noise = better signal
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, absolutely. For years, we've observed that sites with low added-value content see their crawl frequency drop. Server logs show it unambiguously: some sites receive Googlebot only a few times per week, while others are crawled several times per hour.
What's interesting is that Mueller explicitly formulates this link between perceived quality and crawling. Previously, Google often denied a "crawl budget" existed for smaller sites. Here, we acknowledge that even indexation itself is conditioned by this perception.
What nuances should we add?
Caution — "perceived quality" doesn't mean "objective quality". A site can be technically flawless, with expert and unique content, but if its engagement metrics are poor (low visit duration, high bounce rate), Google might judge it as low quality.
Conversely, a site with average design but engaged audience and natural backlinks will be crawled intensively. Behavioral signals weigh very heavily in this equation — perhaps more than content itself.
[To verify] Google provides no precise metric to evaluate this "perceived quality". We navigate blind with correlations (organic CTR, dwell time, backlinks...), but no official data confirms their exact weight.
In what cases doesn't this rule apply?
Major news sites, platforms like YouTube, government sites — in short, established authority sources — largely escape this logic. Google crawls them in near real-time, regardless of individual page "quality".
For an average site, this rule is ruthless. But for a site with tens of millions of pages and a trust history, Google accepts a certain level of noise in the index. It's a fundamental asymmetry of the web.
Practical impact and recommendations
What should you do concretely to improve crawling?
First priority: ruthlessly prune low-value content. Orphan pages, internal duplications, auto-generated content without added value, empty categories — everything diluting the signal must go (noindex, deletion, 301 redirect).
Next, focus on the editorial quality of new publications. Better to publish 2 articles per month with 3,000 words each, sourced, structured, useful, than 20 articles of 400 words with no depth. Google prioritizes sites producing value, not volume.
Finally, optimize site architecture to facilitate crawling: coherent internal linking, up-to-date XML sitemap, fast server response time, avoid redirect chains. A technically performant site encourages Google to explore more.
What errors should you absolutely avoid?
Don't mass-index content "just to be indexed". Many sites inflate their indexed page count thinking it's a positive KPI. It's the opposite: a polluted index sends a negative signal.
Also avoid massively modifying your site to "please algorithms" without improving user engagement. If your content is technically perfect but nobody reads it, Google will eventually reduce crawling.
- Audit server logs to identify crawled versus ignored pages
- Remove or de-index low-value content (thin content, duplications)
- Focus editorial production on quality, not quantity
- Optimize internal linking to guide Googlebot toward priority pages
- Monitor crawl budget evolution in Google Search Console (crawl statistics)
- Improve engagement metrics (CTR, visit duration) to strengthen quality perception
How can you verify your site complies?
Consult the crawl statistics in Google Search Console. If the number of pages crawled daily drops without apparent technical reason, that's a warning signal. Compare with the number of indexed pages: a large gap may indicate Google judges part of your site non-priority.
Analyze your server logs with a tool like Screaming Frog Log File Analyser or OnCrawl. Identify site sections ignored by Googlebot, pages crawled but not indexed, resources consuming crawl without value (URL parameters, unnecessary facets).
❓ Frequently Asked Questions
Combien de pages par jour Google doit-il crawler pour considérer un site comme « bien traité » ?
Si je supprime 80% de mes pages pour améliorer la qualité, vais-je perdre du trafic ?
Le crawl budget affecte-t-il directement le ranking ?
Peut-on forcer Google à crawler davantage en soumettant manuellement les URLs ?
Un site pénalisé peut-il récupérer un crawl normal après correction ?
🎥 From the same video 20
Other SEO insights extracted from this same Google Search Central video · published on 21/01/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.