Official statement
Other statements from this video 17 ▾
- □ Faut-il éviter de modifier fréquemment les balises title pour préserver son référencement ?
- □ Peut-on vraiment effacer le passé SEO d'un domaine racheté ?
- □ Faut-il désavouer les liens qui ne correspondent plus à votre thématique ?
- □ Faut-il vraiment supprimer les backlinks pointant vers l'ancien contenu de votre domaine ?
- □ Les erreurs serveur tuent-elles vraiment votre classement Google ?
- □ Faut-il inclure le nom de marque dans les titres des sites d'actualités ?
- □ Pourquoi modifier uniquement le titre d'un contenu copié ne trompe-t-il personne ?
- □ Faut-il vraiment inclure la date dans les titres de vos articles ?
- □ Les catégories dans les URL influencent-elles vraiment le référencement ?
- □ Comment faciliter l'indexation de vos contenus selon Google ?
- □ Les liens vers vos pages non indexées sont-ils vraiment perdus pour votre SEO ?
- □ Pourquoi Google réduit-il drastiquement son crawl après une migration CDN ?
- □ Le temps de réponse serveur influence-t-il vraiment le classement Google ?
- □ Faut-il vraiment mettre à jour les backlinks après une migration de domaine ?
- □ Faut-il vraiment bloquer des pages par robots.txt si elles peuvent être indexées sans contenu ?
- □ Le texte alternatif d'une image dans un lien a-t-il la même valeur SEO que le texte d'ancrage visible ?
- □ Les photos de produits retouchées nuisent-elles au classement des avis produits ?
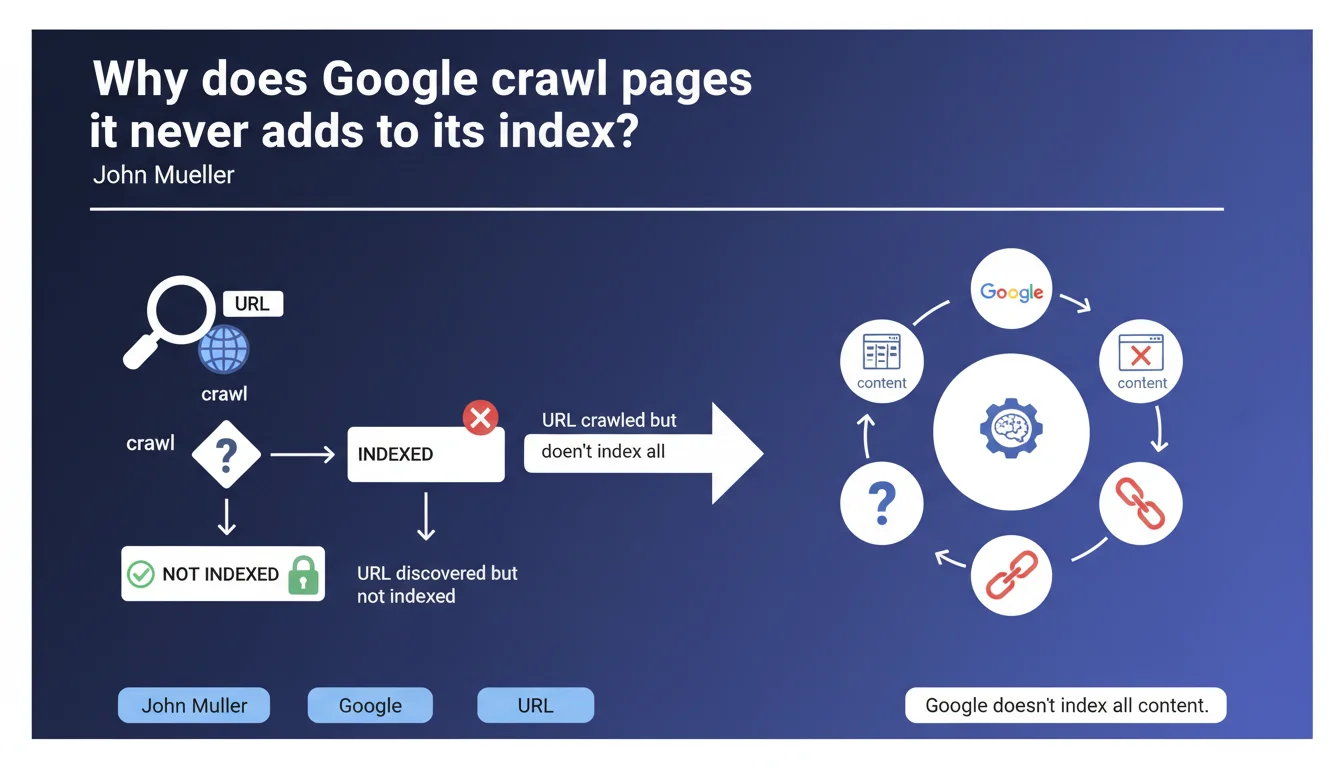
Google makes no meaningful distinction between 'URL crawled but not indexed' and 'URL discovered but not indexed'. Crawling does not guarantee indexation — Google actively chooses what it indexes, and this is non-negotiable. If your pages fall into these categories, it's because Google has determined they offer no real value.
What you need to understand
What does this 'crawled but not indexed' status actually mean?
Google explores your page, reads its content, understands what it's about… and decides not to add it to its index. Crawling is just a technical step, not a quality validation. Googlebot visits, takes notes, and leaves without making any promises.
What Mueller is saying here is that there is no hierarchy between 'crawled' and 'discovered'. In both cases, Google knows your page exists and has chosen to ignore it for indexation purposes. The distinction is purely operational — one has been visited, the other was simply spotted through links or a sitemap.
Why does Google refuse to index certain crawled pages?
Because Google doesn't index everything. That's the key sentence in this statement. The index isn't a passive repository where everything that gets crawled ends up stored. It's an active selection based on perceived quality, relevance, duplication, and resource allocation to your site.
A page can be technically accessible, with no server errors, no noindex tag… and still be excluded. Google filters according to its own criteria — some transparent (weak content, duplication), others opaque (crawl budget, algorithmic priority).
What's the difference between 'crawled' and 'discovered' from an indexation standpoint?
Technically? Almost none. A discovered URL has been spotted (external link, sitemap, internal reference) but hasn't been visited by Googlebot yet. A crawled URL has actually been explored — the content was downloaded and analyzed.
But Mueller insists: both should be treated the same way. If a page stays 'discovered' for months, it's because Google doesn't see enough value in it to allocate crawl budget. If it shifts to 'crawled' without ever being indexed, it means the content analysis didn't change that decision.
- Crawling guarantees nothing — it's a technical step, not a validation.
- Google indexes selectively based on quality criteria and resource allocation.
- 'Crawled' and 'discovered' non-indexed signal the same problem: your page doesn't bring enough value in Google's eyes.
- No magic action will force indexation — you need to understand why Google is rejecting these pages.
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Absolutely. SEO professionals monitoring Search Console regularly see pages crawled for months without ever being indexed. This isn't a bug, it's a Google choice. The myth 'if Googlebot visits your page, it will eventually be indexed' has been dead for a long time — but Mueller kills it officially once more.
What strikes home is that this statement confirms what many suspected: Google doesn't publish all its selection criteria. We know duplication, thin content, and crawl budget play a role… but there's still a gray zone around exact thresholds. [To verify]: How much mediocre content will Google tolerate before blacklisting a page from the index?
What nuances should we add to this claim?
Mueller says 'treat similarly', but the order of operations still matters. A 'discovered' page might simply lack crawl budget — increasing internal linking or update frequency could be enough to move it to 'crawled' status. A page already crawled but not indexed has already failed quality evaluation — there, you need to rework the content itself.
Another point: Google never specifies how long it leaves a page in 'crawled non-indexed' status before considering it permanently out of play. We observe fluctuations — a page might stay in limbo for 6 months, then suddenly be indexed after a content update or gain in backlinks.
In what cases can these statuses be safely ignored?
If your 'crawled non-indexed' pages are filter pages, old pagination, empty templates, or unnecessary URL variations… that's normal and actually desirable. Google is cleaning up on your behalf. The problem emerges when strategic pages — product sheets, important blog articles — fall into this category.
Let's be honest: everyone has non-indexed pages. The goal isn't reaching 100% indexation, but ensuring the pages that matter pass the threshold. If 80% of your non-indexed pages are noise (filters, old versions, technical pages), you can sleep soundly.
Practical impact and recommendations
What should you concretely do with these non-indexed pages?
First, audit. Export the list of 'crawled' and 'discovered' non-indexed URLs from Search Console. Sort them by category: strategic pages, secondary pages, technical pages. If 90% is noise, delete them or block them in robots.txt — there's no point wasting crawl budget.
For pages that should be indexed: analyze content quality. Is it thin content? Is there duplication with other pages? Does the text provide unique value? Google doesn't index mediocre pages out of charity — if content is weak, rework it or merge it with a stronger page.
What mistakes should you avoid with these Search Console statuses?
Don't request indexation manually in loops via the 'Request Indexing' tool. If Google crawled your page and chose not to index it, resubmitting 10 times won't change anything — you're just wasting time. The tool doesn't force indexation, it accelerates crawling.
Another classic trap: believing that adding external backlinks will mechanically solve the problem. Yes, backlinks help… if the content deserves it. If a page stays crawled non-indexed despite incoming links, it's because Google thinks it adds nothing, even with popularity signals.
How should you prioritize actions on these pages?
Start with pages already generating organic traffic or conversions through other channels. If a page converts well via Google Ads or social media but isn't indexed in SEO, that's an obvious lever. Rework the content, add differentiating elements, strengthen internal linking.
Next, tackle pages with potential for high-intent keywords. A non-indexed product page in a low-competition niche has more value than a generic blog article already saturated. Prioritize by business impact, not by volume of pages to handle.
- Export 'crawled' and 'discovered' non-indexed URLs from Search Console
- Categorize these pages: strategic, secondary, technical/useless
- Delete or block pages with no value to free up crawl budget
- Audit content quality for strategically important non-indexed pages
- Eliminate internal duplication and enrich unique content
- Strengthen internal linking to these pages from indexed pages with high authority
- Avoid spamming the 'Request Indexing' tool — prioritize content improvement
- Monitor status evolution over 3-6 months after optimizations
❓ Frequently Asked Questions
Combien de temps Google laisse-t-il une page en 'crawlée non indexée' avant de l'abandonner définitivement ?
Si j'améliore le contenu d'une page 'crawlée non indexée', Google la recrawlera-t-il automatiquement ?
Une page peut-elle passer de 'découverte' à 'crawlée' sans jamais être indexée ?
Faut-il supprimer toutes les pages 'crawlées non indexées' de mon site ?
Le statut 'découverte non indexée' signifie-t-il que mes pages ont un problème technique ?
🎥 From the same video 17
Other SEO insights extracted from this same Google Search Central video · published on 04/02/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.