Official statement
Other statements from this video 17 ▾
- □ Faut-il éviter de modifier fréquemment les balises title pour préserver son référencement ?
- □ Peut-on vraiment effacer le passé SEO d'un domaine racheté ?
- □ Faut-il désavouer les liens qui ne correspondent plus à votre thématique ?
- □ Faut-il vraiment supprimer les backlinks pointant vers l'ancien contenu de votre domaine ?
- □ Faut-il inclure le nom de marque dans les titres des sites d'actualités ?
- □ Pourquoi modifier uniquement le titre d'un contenu copié ne trompe-t-il personne ?
- □ Faut-il vraiment inclure la date dans les titres de vos articles ?
- □ Les catégories dans les URL influencent-elles vraiment le référencement ?
- □ Pourquoi Google crawle-t-il des pages sans jamais les indexer ?
- □ Comment faciliter l'indexation de vos contenus selon Google ?
- □ Les liens vers vos pages non indexées sont-ils vraiment perdus pour votre SEO ?
- □ Pourquoi Google réduit-il drastiquement son crawl après une migration CDN ?
- □ Le temps de réponse serveur influence-t-il vraiment le classement Google ?
- □ Faut-il vraiment mettre à jour les backlinks après une migration de domaine ?
- □ Faut-il vraiment bloquer des pages par robots.txt si elles peuvent être indexées sans contenu ?
- □ Le texte alternatif d'une image dans un lien a-t-il la même valeur SEO que le texte d'ancrage visible ?
- □ Les photos de produits retouchées nuisent-elles au classement des avis produits ?
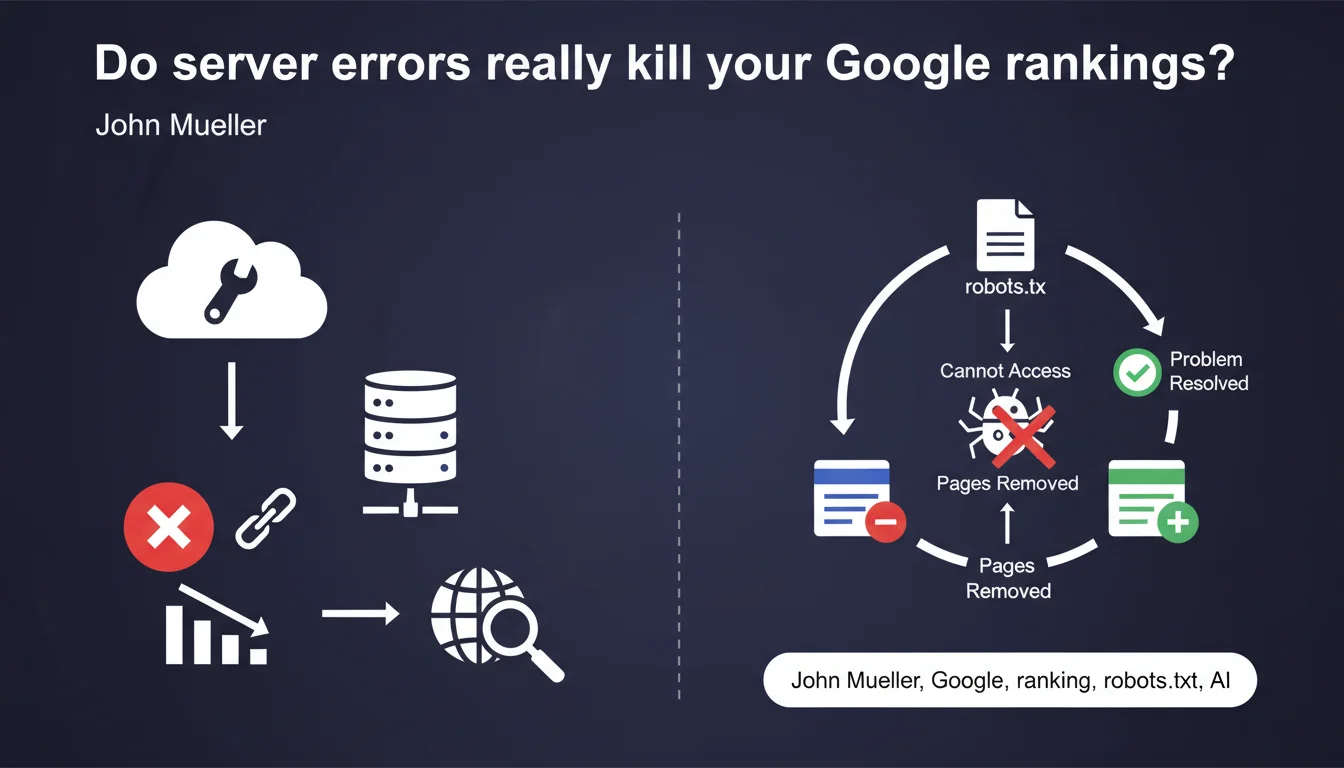
Server connectivity issues do not directly impact your ranking, but can cause your pages to disappear from the index if Google cannot access your robots.txt for an extended period. Reindexation typically takes a few days after the issue is resolved — which still means temporary loss of visibility.
What you need to understand
What's the difference between indexation and ranking in this context?
Google clearly distinguishes two mechanisms: indexation (the presence of your pages in the database) and ranking (the position of these pages in search results). A server problem does not degrade the perceived quality of your content — your pages don't lose quality points.
On the other hand, if Googlebot cannot fetch your robots.txt for a certain period, it applies a precautionary principle and removes certain pages from the index. This is a defensive mechanism, not a penalty.
How long does Google tolerate robots.txt unavailability?
Mueller remains vague about the exact duration — he talks about "for a certain amount of time" without giving a specific threshold. Field observations suggest that several consecutive days of unavailability are needed to trigger deindexation, but [To be verified] because Google does not communicate an official timeframe.
This ambiguity makes it difficult to properly size your monitoring. A few hours of downtime? Probably no consequence. Several days? Real risk of losing indexation.
Why is robots.txt so critical in this scenario?
The robots.txt file serves as an entry point for Googlebot. Without access to it, the crawler doesn't know which rules to apply — it could index sections you want to block, or conversely avoid exploring certain areas out of caution.
Faced with this uncertainty, Google chooses the conservative approach: it removes pages from the index rather than risk violating your directives. This is a compliance logic, not a penalty.
- Server errors do not degrade the quality of your pages in Google's eyes
- The inability to access robots.txt for an extended period can result in deindexation
- Reindexation typically takes a few days after the problem is resolved
- Google does not communicate a precise time threshold that triggers deindexation
- The mechanism is defensive, not punitive — Google protects your crawling directives
SEO Expert opinion
Is this statement consistent with field observations?
Overall, yes. We do observe that sites with occasional server problems do not see their rankings collapse — positions remain stable. However, progressive deindexation during extended robots.txt unavailability is documented in several cases.
The real problem is the reindexation delay. Mueller talks about "a few days," but in practice we see significant variations — some sites recover in 48 hours, others in 10-15 days. This probably depends on the crawl budget allocated to the site and its authority.
What nuances should be added to this statement?
Saying there is "no impact on ranking" is technically true, but practically misleading. If your pages disappear from the index for several days, they don't rank at all — that's worse than a ranking drop.
Additionally, Mueller does not specify whether prolonged deindexation can affect the perceived freshness of the site. A regularly inaccessible site could theoretically see its crawl frequency reduced over time — but [To be verified] because Google has never explicitly confirmed this.
In which cases can this mechanism become problematic?
Sites with high seasonality or those dependent on occasional traffic spikes (news, events) are most vulnerable. A 5-day deindexation during a planned peak can cancel months of SEO preparation.
Sites with limited crawl budget are also worth monitoring closely. If Google already takes several weeks to crawl your new pages under normal circumstances, deindexation followed by slow reindexation can create a cumulative lag that's difficult to catch up with.
Practical impact and recommendations
How to quickly detect a robots.txt accessibility problem?
Set up active monitoring that checks your robots.txt availability every 5-10 minutes. Don't just monitor general site accessibility — this specific file must have its own alerting system.
In Search Console, monitor the Settings > robots.txt file section. Google reports access issues there, but with a delay — your internal monitoring must be more reactive.
What to do if robots.txt becomes inaccessible?
Top priority: restore access in less than 24 hours. Even if Google probably tolerates a few days, every hour counts to minimize risk. Identify whether it's a server problem, CDN issue, DNS configuration, or firewall rules.
Once the issue is fixed, use the URL Inspection tool in Search Console to request manual reindexing of strategic pages. Don't overwhelm the tool — focus on 20-30 critical URLs to accelerate recovery.
What preventive measures should you put in place?
- Set up dedicated HTTP monitoring for /robots.txt with SMS/email alerts
- Document the quick robots.txt restoration procedure in your technical runbook
- Verify that your redundant infrastructure (CDN, load balancer) properly serves robots.txt even during partial failures
- Regularly test robots.txt accessibility from different geographic locations
- Never block robots.txt through firewall or overly restrictive security rules
- If you use a CDN, ensure the robots.txt TTL is reasonable (max 1 hour) to allow for quick fixes
- Keep a version history of robots.txt for quick rollback if needed
❓ Frequently Asked Questions
Combien de temps exactement Google tolère-t-il une indisponibilité du robots.txt avant de désindexer ?
Si mon serveur renvoie des erreurs 503 pendant quelques heures, est-ce que je perds mes positions ?
La réindexation après résolution du problème est-elle automatique ?
Est-ce que tous les types d'erreurs serveur ont le même impact ?
Dois-je surveiller autre chose que le robots.txt pour éviter la désindexation ?
🎥 From the same video 17
Other SEO insights extracted from this same Google Search Central video · published on 04/02/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.