Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Les liens internes dans le header ou le footer ont-ils moins de valeur SEO ?
- □ Google pénalise-t-il vraiment un site qui achète des liens en masse ?
- □ Faut-il vraiment viser la perfection technique pour bien ranker sur Google ?
- □ Pourquoi Google crawle-t-il moins votre site s'il le trouve de mauvaise qualité ?
- □ Le statut « Crawlée, actuellement non indexée » est-il vraiment un signal de qualité insuffisante ?
- □ Les données structurées invalides peuvent-elles pénaliser votre référencement ?
- □ Faut-il s'inquiéter d'une baisse du nombre de pages indexées ?
- □ Peut-on vraiment contrôler les images affichées dans les snippets Google ?
- □ Pourquoi Google pénalise-t-il le contenu dupliqué entre sites de franchises ?
- □ CCTLD, sous-domaine ou sous-répertoire : quelle structure pour le géociblage international ?
- □ Le code 503 protège-t-il vraiment vos pages de la désindexation en cas de panne ?
- □ Les liens dofollow accidentels dans vos RP vont-ils vous pénaliser ?
- □ Peut-on vraiment utiliser l'outil de changement d'adresse pour fusionner ou diviser des sites ?
- □ Pourquoi vos données structurées disparaissent-elles sur vos pages localisées ?
- □ Les données structurées améliorent-elles vraiment le référencement ou juste l'affichage ?
- □ Google va-t-il un jour afficher les Core Web Vitals directement dans les résultats de recherche ?
- □ Restructuration d'URL : pourquoi Google provoque-t-il des fluctuations pendant deux mois ?
- □ Le linking interne surpasse-t-il vraiment la structure d'URL pour le SEO ?
- □ Faut-il vraiment calculer le PageRank interne pour optimiser son site ?
- □ Google peut-il vraiment identifier la langue principale d'une page multilingue sans pénaliser votre SEO ?
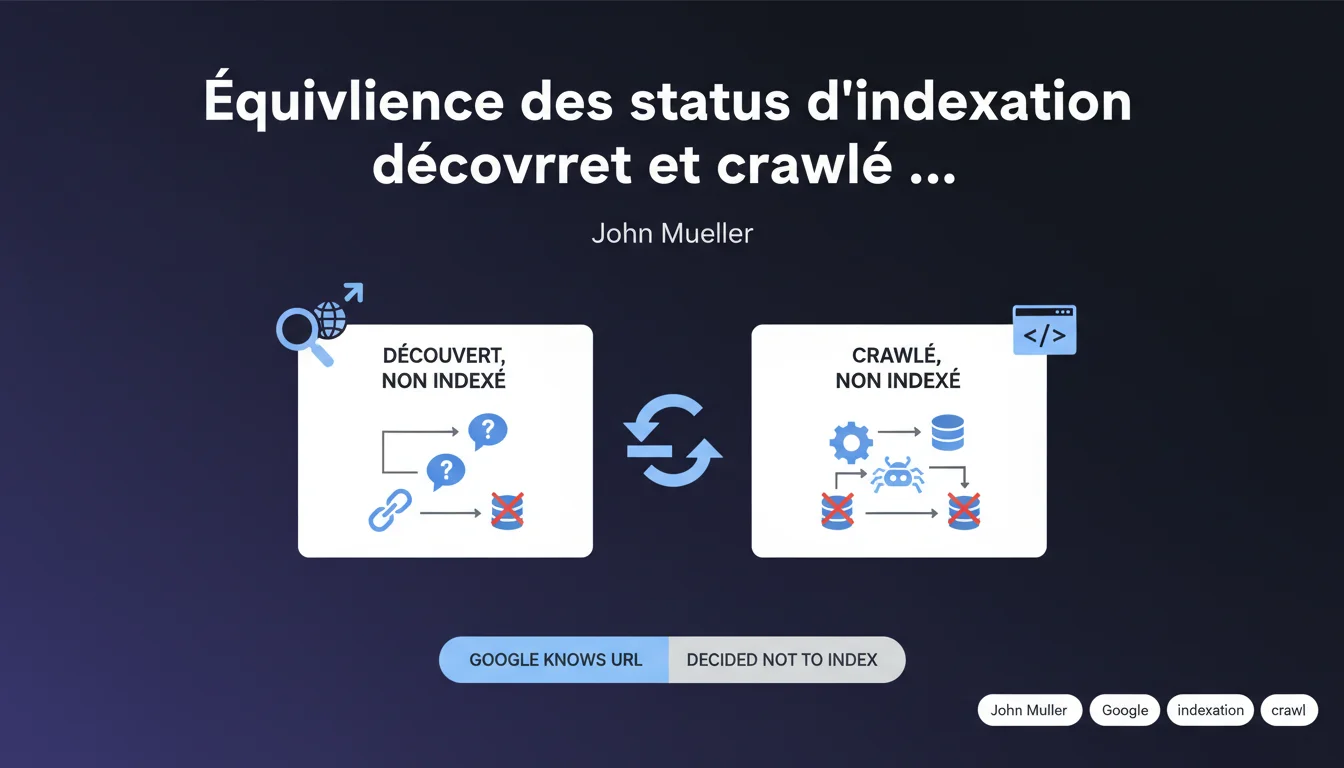
Google considère « Crawlée, non indexée » et « Découverte, non indexée » comme deux statuts équivalents : dans les deux cas, le moteur connaît l'URL mais refuse de l'indexer. La nuance de crawl n'a donc aucune importance sur la décision finale d'indexation. Ce qui compte, c'est de comprendre pourquoi Google juge la page non indexable.
Ce qu'il faut comprendre
Cette déclaration de John Mueller balaie une croyance répandue : non, passer de « Découverte » à « Crawlée » ne rapproche pas forcément votre URL de l'indexation. Google fonctionne par priorités — crawler une page ne signifie pas qu'elle mérite une place dans l'index.
Beaucoup de SEO pensent encore qu'une URL crawlée a franchi une étape décisive. Faux. Le crawl est une simple collecte d'informations, l'indexation une décision éditoriale basée sur la valeur perçue de la page.
Que signifie « équivalence » entre ces deux statuts ?
Concrètement, les deux étiquettes indiquent la même chose : Google connaît l'URL, mais ne la juge pas digne d'être servie aux utilisateurs. Que l'URL ait été crawlée ou simplement découverte via un lien, le résultat final est identique — elle reste hors index.
Le statut « Crawlée, non indexée » signifie que Googlebot a récupéré le contenu, analysé le HTML, extrait les signaux — et conclu que ça ne valait pas le coup. « Découverte, non indexée » signifie que Google a repéré l'URL (via sitemap, liens internes, backlinks) mais n'a même pas jugé utile d'y consacrer du crawl budget.
Pourquoi Google décide-t-il de ne pas indexer ces pages ?
Les raisons sont multiples et Google reste délibérément vague. Ça peut être du contenu dupliqué, des pages à faible valeur ajoutée (filtres, paginations infinies, pages archives vides), un manque d'autorité globale du site, ou simplement une saturation : Google ne peut pas tout indexer.
Dans certains cas, c'est un problème de crawl budget mal alloué. Google passe son temps sur des URLs inutiles pendant que les bonnes pages restent ignorées. Dans d'autres, c'est structurel : trop de pages similaires sans valeur différenciante.
- « Crawlée, non indexée » : Google a regardé, jugé le contenu, et dit non
- « Découverte, non indexée » : Google sait que l'URL existe mais ne veut même pas dépenser de ressources dessus
- L'équivalence : les deux mènent au même résultat — aucune visibilité organique
- Le vrai enjeu : comprendre pourquoi Google refuse l'indexation, pas dans quel statut l'URL est coincée
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui — et c'est agaçant pour beaucoup de SEO qui espéraient qu'un crawl signifie « presque indexé ». Sur le terrain, on observe régulièrement des sites avec des milliers d'URLs crawlées mais jamais indexées, tandis que d'autres voient des URLs découvertes passer directement en index après une simple mention dans un sitemap.
Ce qui compte vraiment, c'est la qualité perçue de la page. Google ne manque pas de crawl budget — il manque de raisons valables d'indexer du contenu médiocre. Si votre page n'apporte rien de neuf, elle peut être crawlée cent fois sans jamais entrer dans l'index.
Quelles nuances faut-il apporter ?
Attention : si Google ne crawle jamais une URL découverte, c'est aussi un signal. Ça peut indiquer un problème structurel (robots.txt mal configuré, pagination chaotique, JS non crawlable) ou un manque d'autorité tel que Google considère le crawl comme un gaspillage.
À l'inverse, une URL crawlée puis refusée signifie que Google a pris le temps d'analyser et a conclu négativement. C'est plus grave qu'un simple « pas encore crawlé » — c'est un rejet actif. [À vérifier] : Google affirme que les deux statuts sont équivalents, mais dans la pratique, une URL crawlée puis rejetée nécessite souvent plus de travail (réécriture, consolidation) qu'une URL simplement ignorée.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Sur des sites à très forte autorité, certaines URLs passent directement de « Découverte » à « Indexée » sans jamais afficher le statut « Crawlée, non indexée ». Google fait alors confiance par défaut. C'est rare, mais observable sur des médias établis ou des sites universitaires.
Autre exception : les pages bloquées volontairement (noindex, canonicales pointant ailleurs). Elles apparaissent parfois comme « Découverte, non indexée » alors que c'est un choix délibéré du webmaster. Google ne fait pas la distinction dans Search Console — c'est au SEO de démêler.
Impact pratique et recommandations
Que faut-il faire concrètement face à ces statuts ?
Première étape : identifier les pages qui méritent vraiment l'indexation. Toutes les URLs de votre site n'ont pas vocation à être indexées. Filtres à facettes, pages d'archives vides, variations mineures de contenu — laissez tomber.
Pour les pages stratégiques coincées dans ces statuts, deux leviers : améliorer le contenu (valeur ajoutée, originalité, profondeur) et renforcer les signaux de pertinence (liens internes, mentions externes, contexte sémantique).
Quelles erreurs éviter ?
Erreur classique : multiplier les demandes d'indexation manuelle via Search Console. Si Google refuse d'indexer après crawl, ce n'est pas un bug — c'est un choix. Forcer ne changera rien.
Autre piège : croire qu'un sitemap XML garantit l'indexation. Le sitemap est une suggestion, pas un ordre. Google crawle ce qu'il veut, quand il veut, selon ses propres critères de valeur.
Comment diagnostiquer et corriger le problème ?
Analysez les patterns : quelles catégories de pages sont bloquées ? Les filtres ? Les paginations profondes ? Les articles anciens sans backlinks ? Une fois le pattern identifié, trois stratégies possibles :
- Consolidation : fusionner les pages similaires en une seule version plus riche
- Noindex volontaire : assumer que ces pages n'ont pas besoin d'être indexées et nettoyer Search Console
- Renforcement : enrichir le contenu, ajouter des médias, créer du maillage interne ciblé, obtenir des backlinks
- Canonicalisation : pointer les variations vers la version principale pour concentrer les signaux
- Révision structurelle : revoir la pagination, les filtres, la hiérarchie si le problème touche des centaines d'URLs
❓ Questions frequentes
Si une URL passe de « Découverte » à « Crawlée, non indexée », est-ce un bon signe ?
Combien de temps faut-il attendre avant qu'une page découverte soit indexée ?
Peut-on forcer Google à indexer une page bloquée dans ces statuts ?
Faut-il supprimer les pages « Crawlée, non indexée » ou « Découverte, non indexée » ?
Est-ce qu'un sitemap XML aide à faire indexer ces pages ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/01/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.