Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Les liens internes dans le header ou le footer ont-ils moins de valeur SEO ?
- □ Google pénalise-t-il vraiment un site qui achète des liens en masse ?
- □ Faut-il vraiment viser la perfection technique pour bien ranker sur Google ?
- □ Pourquoi Google crawle-t-il moins votre site s'il le trouve de mauvaise qualité ?
- □ Le statut « Crawlée, actuellement non indexée » est-il vraiment un signal de qualité insuffisante ?
- □ Les données structurées invalides peuvent-elles pénaliser votre référencement ?
- □ Faut-il s'inquiéter d'une baisse du nombre de pages indexées ?
- □ Crawlée non indexée vs Découverte non indexée : vraiment équivalent ?
- □ Peut-on vraiment contrôler les images affichées dans les snippets Google ?
- □ Pourquoi Google pénalise-t-il le contenu dupliqué entre sites de franchises ?
- □ CCTLD, sous-domaine ou sous-répertoire : quelle structure pour le géociblage international ?
- □ Le code 503 protège-t-il vraiment vos pages de la désindexation en cas de panne ?
- □ Les liens dofollow accidentels dans vos RP vont-ils vous pénaliser ?
- □ Peut-on vraiment utiliser l'outil de changement d'adresse pour fusionner ou diviser des sites ?
- □ Les données structurées améliorent-elles vraiment le référencement ou juste l'affichage ?
- □ Google va-t-il un jour afficher les Core Web Vitals directement dans les résultats de recherche ?
- □ Restructuration d'URL : pourquoi Google provoque-t-il des fluctuations pendant deux mois ?
- □ Le linking interne surpasse-t-il vraiment la structure d'URL pour le SEO ?
- □ Faut-il vraiment calculer le PageRank interne pour optimiser son site ?
- □ Google peut-il vraiment identifier la langue principale d'une page multilingue sans pénaliser votre SEO ?
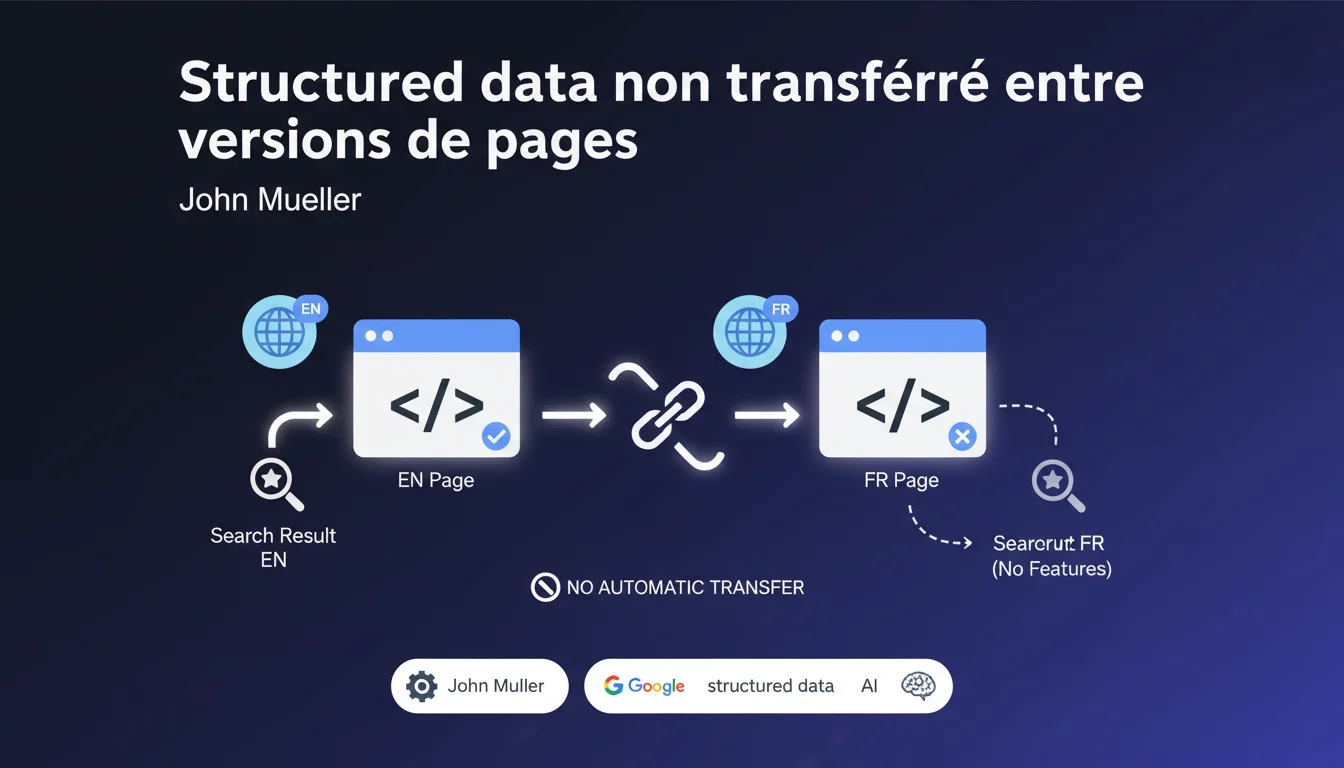
Google ne transfère pas automatiquement les données structurées entre versions de pages (notamment localisées). Chaque URL doit intégrer son propre balisage Schema.org si vous visez des résultats enrichis. Oublier ce principe, c'est risquer de perdre rich snippets, FAQ ou produits structurés sur vos variantes linguistiques ou régionales.
Ce qu'il faut comprendre
Que signifie concrètement "non transférée" ?
Google traite chaque URL comme une entité autonome. Si votre page française /fr/produit-x contient un balisage Schema Product, votre version anglaise /en/product-x n'en hérite pas — même si les deux partagent le même contenu traduit.
Le moteur parse le HTML de chaque variante indépendamment. Pas de Schema détecté dans le DOM ? Pas de résultat enrichi possible, quelle que soit la présence d'un hreflang ou d'une balise canonical pointant vers une autre version.
Pourquoi Google ne peut-il pas dupliquer les données structurées lui-même ?
Techniquement, Google pourrait croiser hreflang et Schema pour propager les métadonnées. Mais cela introduirait des risques : prix en euros affichés sur une page US, horaires d'ouverture parisiens sur une boutique londonienne, etc.
La déclaration de Mueller est donc autant un choix de conception qu'une limitation technique. Google préfère que chaque webmaster déclare explicitement ses métadonnées par URL — c'est plus fiable que des heuristiques de propagation.
Quels types de pages sont concernés ?
Toutes les variantes qui partagent un même contenu sous des URLs distinctes : versions linguistiques (hreflang), versions AMP/non-AMP, versions mobile/desktop séparées (de plus en plus rares), ou encore pages imprimables.
- Pages localisées avec hreflang : chaque langue nécessite son propre Schema Product, FAQPage, etc.
- Anciennes architectures mobile séparées (m.site.com) : le Schema de www.site.com ne s'applique pas à m.site.com
- Versions AMP : bien que souvent associées via
<link rel="amphtml">, elles doivent porter leur propre balisage structuré - Pages avec paramètres UTM ou identifiants de session : si Google les indexe, elles sont traitées comme des URLs distinctes
Avis d'un expert SEO
Cette règle est-elle vraiment appliquée dans tous les cas ?
Sur le terrain, on observe quelques comportements ambigus. Les pages AMP liées via amphtml semblent parfois "hériter" du Schema de la page canonique dans les SERPs mobiles — mais ce n'est pas documenté officiellement.
De même, certains sites ont constaté des rich snippets actifs sur des variantes hreflang sans Schema explicite, probablement parce que Google a fusionné les signaux lors du clustering de résultats. Mais compter là-dessus relève du pari risqué. [A vérifier] dans vos propres tests : la règle énoncée par Mueller reste la seule garantie.
Quelles erreurs découlent souvent de cette méconnaissance ?
Premier réflexe classique : baliser la page principale en anglais et supposer que les traductions bénéficieront du même traitement. Résultat ? Aucun résultat enrichi en allemand, espagnol ou japonais, alors que le contenu est identique.
Deuxième piège : copier-coller le JSON-LD d'une langue à l'autre sans adapter les valeurs. Un "price": "99 USD" affiché sur une page .fr génère des incohérences — Google peut ignorer le balisage ou afficher un prix erroné.
Dans quels cas peut-on se permettre de ne pas dupliquer le Schema ?
Si vous utilisez une stratégie de canonical stricte où toutes les variantes pointent vers une seule URL de référence (par exemple, toutes les versions redirigent en 301 vers /en/), alors une seule implémentation suffit. Mais dans ce cas, vous renoncez au multilingue indexé.
Autre scénario : les pages sans ambition de résultat enrichi — pages de mentions légales, CGV, etc. — peuvent se passer de Schema dupliqué. Mais dès qu'un élément éligible (FAQ, breadcrumb, article) apparaît, la règle s'applique.
Impact pratique et recommandations
Que faut-il faire concrètement pour chaque variante de page ?
Commencez par un audit de vos URLs localisées ou alternatives. Listez toutes les versions AMP, hreflang, sous-domaines régionaux. Pour chacune, vérifiez la présence et la validité du Schema via Rich Results Test.
Ensuite, créez un système de génération dynamique de JSON-LD : votre CMS doit injecter le balisage en fonction de la langue, de la devise, des horaires locaux, etc. Pas de copier-coller manuel — c'est ingérable à l'échelle.
- Identifier toutes les URLs distinctes qui partagent du contenu (hreflang, AMP, mobile séparé)
- Tester chaque variante dans Rich Results Test — ne jamais supposer qu'une page hérite du Schema d'une autre
- Adapter les valeurs sensibles : prix, devise, disponibilité, adresse, langue de l'attribut
inLanguage - Automatiser la génération via templates CMS ou scripts serveur (PHP, Node, Python) pour éviter les erreurs manuelles
- Vérifier dans Search Console la couverture des résultats enrichis par langue/région
Quelles erreurs éviter absolument ?
Ne laissez jamais de valeurs en dur dans un JSON-LD copié entre langues. Un "address": "123 Main St, New York" sur une page .de est ridicule — et Google peut sanctionner le balisage comme trompeur.
Évitez aussi de baliser uniquement la version desktop si vous avez une architecture mobile séparée (m.site.com). Les utilisateurs mobiles ne verront pas les rich snippets, ce qui dégrade le CTR.
Comment vérifier que mon site est conforme ?
Passez en revue vos rapports Search Console section "Améliorations". Filtrez par pays ou langue si possible. Une absence de résultats enrichis sur certaines zones géographiques signale souvent un Schema manquant.
Utilisez aussi des crawlers (Screaming Frog, OnCrawl) pour extraire le JSON-LD de chaque URL et comparer les variantes. Un diff rapide révèle les incohérences de prix, d'adresse ou de langue.
❓ Questions frequentes
Les données structurées d'une page desktop sont-elles transférées vers la version mobile ?
Le hreflang permet-il de partager les données structurées entre langues ?
Dois-je dupliquer le Schema sur toutes mes pages AMP ?
Un Schema Product en anglais sur /en/ peut-il s'afficher sur /fr/ via canonical ?
Comment automatiser la génération de Schema multilingue ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/01/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.