Official statement
Other statements from this video 15 ▾
- □ Les fluctuations de classement sont-elles vraiment normales ou cachent-elles un problème technique ?
- □ Google utilise-t-il vraiment un seul index mondial pour tous les pays ?
- □ Faut-il encore se fier aux résultats de la requête site: pour diagnostiquer l'indexation ?
- □ L'engagement utilisateur influence-t-il réellement le classement Google ?
- □ Pourquoi les pages à fort trafic pèsent-elles plus dans le score Core Web Vitals ?
- □ Google segmente-t-il vraiment les sites par type de template pour évaluer la Page Experience ?
- □ Combien de liens internes faut-il placer par page pour optimiser son SEO ?
- □ Pourquoi la structure en arbre de votre maillage interne compte-t-elle vraiment pour Google ?
- □ Pourquoi la structure d'URL n'a-t-elle aucune importance pour Google ?
- □ Pourquoi les positions Search Console ne reflètent-elles pas la réalité du classement ?
- □ Google distingue-t-il vraiment 'edit video' et 'video editor' comme des intentions différentes ?
- □ Le balisage FAQ doit-il obligatoirement figurer sur la page indexée pour générer un rich snippet ?
- □ Les liens en footer ont-ils la même valeur SEO que les liens dans le contenu ?
- □ L'indexation mobile-first a-t-elle un impact sur vos classements Google ?
- □ Faut-il vraiment qu'un robots.txt inexistant retourne un 404 pour éviter de bloquer Googlebot ?
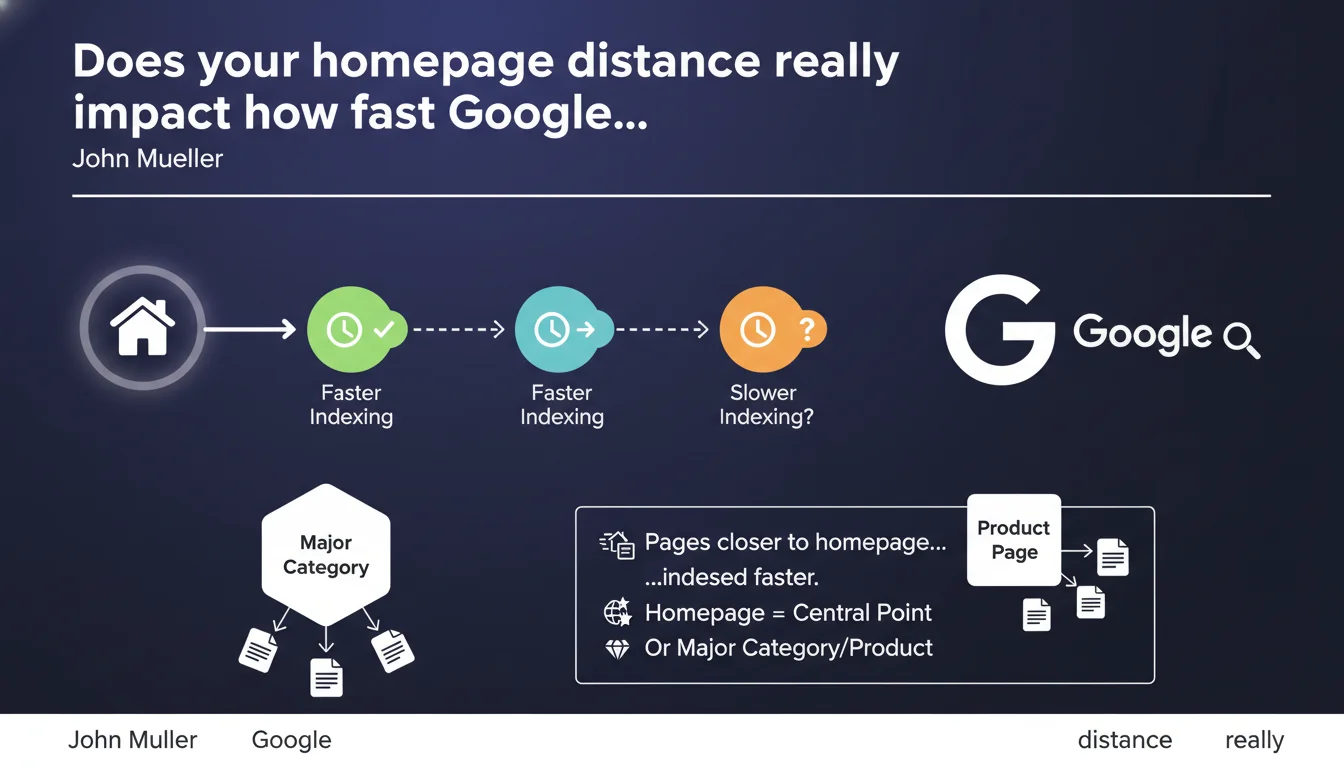
Google indexes pages closer to the homepage more quickly because it's typically the central crawl point. This logic applies to most sites, but some architectures may have a different focal point — a major category or flagship product. Click depth remains a strong signal for crawl prioritization.
What you need to understand
Why is the homepage the starting point for crawling?
For Googlebot, the homepage represents the main gateway to a website. It's often the page that accumulates the most external backlinks and benefits from the best authority. The robot therefore prioritizes exploring links located in direct proximity to this page.
This logic explains why a page accessible in 1 or 2 clicks from the root will be discovered and indexed much faster than a page buried 5 or 6 levels deep. The crawl budget naturally concentrates on the most accessible areas.
Do all sites follow this pattern?
No — and this is where Mueller introduces an important nuance. On some sites, the homepage is just a generic showcase. The real focal point may be a strategic category or a flagship product that attracts most of the traffic and links.
In this case, Googlebot adapts its behavior. It understands that the center of gravity of the site is elsewhere and adjusts its crawl priorities accordingly. The algorithm isn't rigid — it detects where activity is concentrated.
What's the technical mechanism behind this prioritization?
The indexation distance relies on several combined signals: click depth, internal links, internal PageRank, update frequency. A page linked directly from the homepage inherits some of its authority through internal linking structure.
The closer a page is to the central point, the more "SEO juice" it receives and the more frequently Googlebot visits it. Conversely, an orphaned page or one too deep may remain invisible for weeks or even never be indexed.
- The homepage is the default starting point for crawling on the majority of sites
- Click depth directly influences indexation speed
- Some sites have an alternative focal point (category, product) recognized by Google
- Internal linking structure distributes authority and guides Googlebot toward priority pages
- A page buried too deep can remain out of index for weeks
SEO Expert opinion
Does this statement match real-world observations?
Yes, and it's actually one of the rarest SEO principles that systematically verifies itself. Every audit shows a direct correlation between click depth and indexation speed. Pages 1-2 clicks from the home appear in the index within hours to days. Those 5-6 clicks deep may wait for weeks.
The nuance Mueller brings about "alternative focal points" also reflects the reality of sites like Amazon or Booking, where certain categories outperform the homepage in terms of traffic and links. Google knows how to adapt — but only if these alternative pages have measurable authority.
What's the practical limit of this rule?
The problem is that we can't directly control how Google identifies this famous "central point." Mueller remains vague: "for some sites, this can be a specific major category or product." Fine, but what signals trigger this recognition? [To verify]
In practice, if you have a strategic category generating 60% of traffic but remaining 3 clicks from the home, nothing guarantees that Googlebot will treat it as a focal point. You'll likely need to force the issue through internal linking and better structural visibility.
Should we conclude that a flat architecture is always preferable?
Not necessarily. Too flat an architecture dilutes semantic hierarchy and confuses both users and search engines. The goal isn't to put everything 1 click from the home, but to ensure that strategic pages are accessible quickly.
Let's be honest: most e-commerce or media sites have hundreds of thousands of pages. Impossible to bring everything up. The challenge is intelligent prioritization and monitoring pages that stagnate in depth despite their business importance.
Practical impact and recommendations
How to reduce the indexation distance of strategic pages?
Start by mapping your site with a crawler (Screaming Frog, Oncrawl, Botify). Identify pages with high business value that are 4 or more clicks from the home. Then, create direct internal links from pages close to the root.
Menus, footers, and navigation areas are your allies. A link from the main menu instantly reduces depth to 1 click. Also use contextual link blocks in pillar page content to distribute authority toward sub-pages.
What structural errors slow down indexation?
The classic mistake: important categories hidden behind multiple filter or pagination levels. Each additional click slows crawl. Another common trap: orphaned pages — technically in the site, but absent from internal linking.
Also verify JavaScript links not detected by Googlebot in pure HTML mode. If your architecture relies on client-side JS without fallback, some pages risk remaining invisible even if they're "close" in theory.
How to verify that Google recognizes my alternative focal point?
Monitor server logs and Search Console. If a category or product receives as much crawl as the homepage — or more — that's a good sign. Also analyze crawl frequency on these URLs and compare with other site sections.
If data shows that Googlebot ignores your strategic page despite business importance, the signal didn't get through. You need to reinforce internal linking, external backlinks to this page, and possibly raise it in the information architecture.
- Crawl the site and identify strategic pages 4+ clicks deep
- Add direct links from menus, footers, or pillar pages
- Verify absence of orphaned pages in important sections
- Test JavaScript rendering to detect invisible links in pure HTML
- Analyze server logs to spot under-crawled areas
- Monitor click depth evolution after optimization
- Strengthen internal linking toward alternative focal points
❓ Frequently Asked Questions
Une page à 5 clics de la homepage peut-elle quand même être indexée rapidement ?
Le sitemap XML permet-il de contourner le problème de profondeur ?
Comment savoir si Google a identifié un point focal alternatif sur mon site ?
Faut-il tout mettre à 1 clic de la homepage pour optimiser l'indexation ?
Les liens en JavaScript sont-ils pris en compte dans le calcul de profondeur ?
🎥 From the same video 15
Other SEO insights extracted from this same Google Search Central video · published on 14/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.