Official statement
Other statements from this video 12 ▾
- □ Faut-il vraiment se préoccuper du crawl budget pour votre site ?
- □ Comment Google définit-il réellement le crawl budget et quels leviers peut-on actionner ?
- □ Le crawl budget est-il un concept inventé par Google ou par les SEO ?
- □ Google n'indexe-t-il vraiment qu'une fraction du web à cause de ses coûts de stockage ?
- □ Les requêtes POST plombent-elles vraiment votre crawl budget ?
- □ Le crawl budget d'une nouvelle section est-il hérité de la qualité du site principal ?
- □ Les codes 503 et 429 peuvent-ils vraiment réduire votre crawl budget ?
- □ Peut-on vraiment piloter son crawl budget depuis Google Search Console ?
- □ HTTP/2 améliore-t-il vraiment votre crawl budget ?
- □ Faut-il bloquer l'indexation de vos fichiers JavaScript pour optimiser le crawl budget ?
- □ Les 404 et robots.txt gaspillent-ils vraiment votre crawl budget ?
- □ Faut-il bloquer vos fichiers JavaScript décoratifs pour optimiser votre crawl budget ?
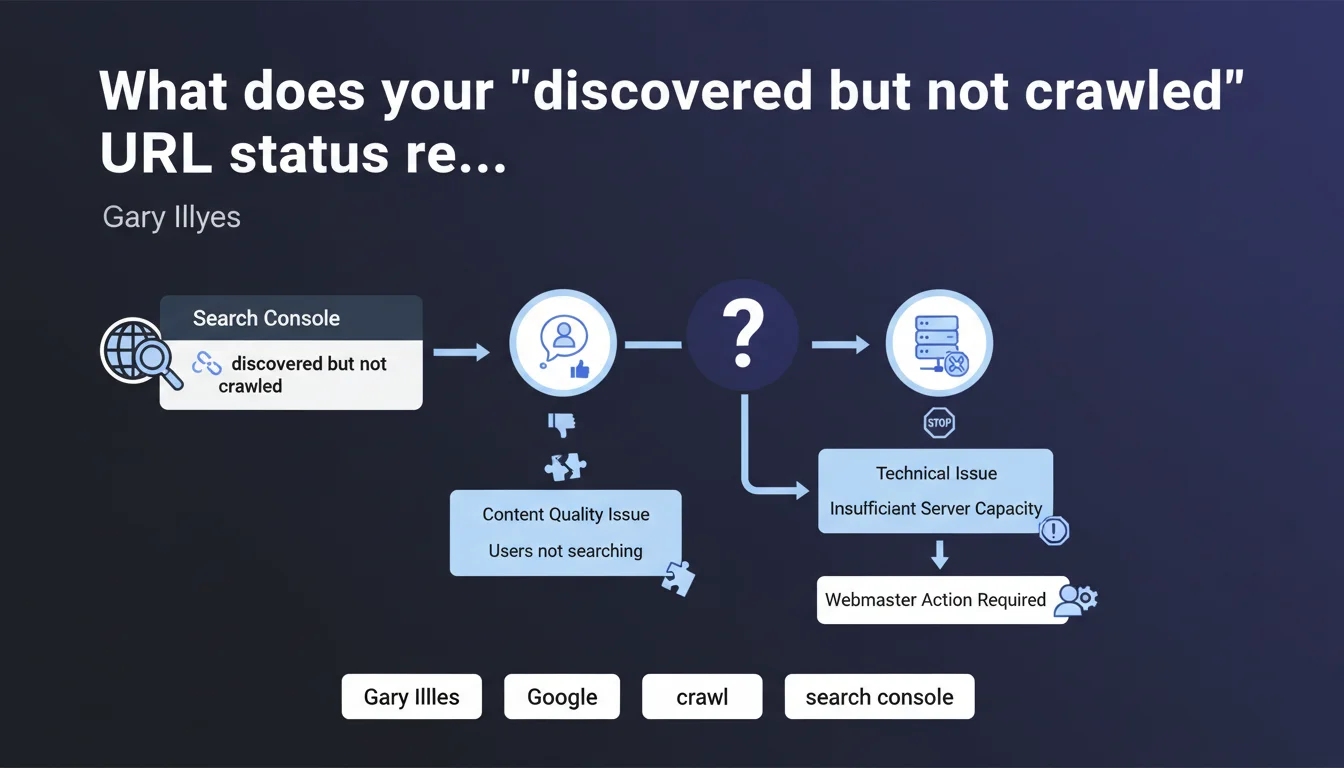
A high proportion of URLs with "discovered but not crawled" status in Search Console indicates either content Google considers uninteresting, or a technically deficient server. Google doesn't crawl what it deems pointless for its users — or what it cannot crawl properly.
What you need to understand
What exactly does this "discovered not crawled" status mean?
Google has identified the URL — via an internal link, external link, or sitemap — but decided not to crawl it. It's not an oversight: it's a deliberate choice by the algorithm.
This status indicates that Googlebot has prioritized other pages on your site. It estimates that these URLs don't deserve immediate crawling, or perhaps never will.
Why does Google refuse to crawl certain pages?
Two main scenarios according to Gary Illyes: quality problem or technical problem.
If it's a quality issue, Google thinks the content interests no one — duplicate pages, thin content, unnecessary facets, out-of-stock product sheets. If it's technical, your server responds too slowly, timeouts, sporadic 5xx errors. In both cases, Googlebot conserves its crawl budget.
How do you distinguish a quality problem from a technical problem?
Analyze your server logs. If Googlebot attempts to crawl but receives errors or catastrophic response times, it's technical. If Googlebot doesn't even try, it's a quality signal.
Also check the type of URLs involved: thousands of facet filter pages? Architecture problem. Recent product sheets with unique content? Dig into server-side issues.
- Discovered not crawled is not a Google bug — it's a verdict on your content or infrastructure
- Google prioritizes its crawl budget: it won't crawl what it judges as valueless
- A server logs audit allows you to distinguish technical refusal from editorial refusal
- A high proportion of this status should trigger a critical analysis of your site
SEO Expert opinion
Does this statement truly reflect what we observe in the field?
Yes, and it's brutal. We regularly observe sites with 60-70% of URLs discovered but not crawled — often poorly managed e-commerce sites that generate thousands of filter combinations, or WordPress sites that index anything via the sitemap.
What Gary Illyes doesn't say: Google can also deliberately place URLs in "discovered not crawled" to test the site's reaction. If you fix a technical problem, Googlebot returns — sometimes within hours. If you clean up low-quality content, the effect is slower but measurable.
Should you always be alarmed by a high discovered-not-crawled rate?
No. It depends on which URLs are affected. If they're old-school pagination pages, blog archives from 2008, or tracking parameters, it's better that Google doesn't crawl them.
The problem arises when these are your new product sheets, your strategic landing pages, or your fresh editorial content. Then you have a real issue — either Google doesn't find them relevant, or your server is struggling.
Can you force Google to crawl these URLs?
No. [To be verified] but field experience shows that requesting a crawl via Search Console on 500 discovered-not-crawled URLs changes nothing. Google returns when it deems it worthwhile — or never.
The only solution: fix the root cause. Improve content, optimize the server, clean up the architecture. Googlebot is not an on-demand tool, it's an algorithm that prioritizes according to its own economic logic.
Practical impact and recommendations
What should you do concretely if you have a high discovered-not-crawled rate?
First, segment the URLs involved. Export the Search Console report, classify by type: products, categories, blog, facets, parameters. Identify patterns.
Next, cross-reference with your server logs for the same period. Is Googlebot attempting to crawl and failing? Or is it not even trying? If attempts + 5xx errors or timeouts, it's a server problem. If no attempts, it's a quality signal or crawl budget issue.
What mistakes should you absolutely avoid?
Never force indexation via sitemap of thousands of low-quality URLs hoping Google will crawl them. You make the problem worse: Google detects that you're massively offering it content it judges valueless, and this degrades the overall perception of your site.
Another classic mistake: deploying an undersized server for a product catalog of 50,000 references. If your average server response time exceeds 500ms, Googlebot will slow down its crawl — or even abandon certain sections.
How do you verify that your site is compliant and optimized?
- Analyze the discovered/crawled ratio over the last 3 months in Search Console
- Export URLs with "discovered not crawled" status and segment by page type
- Check your server logs: is Googlebot attempting to crawl these URLs?
- Measure average server response time (target: under 200ms)
- Identify URLs with no added value and block them via robots.txt or noindex
- Improve content on strategic non-crawled pages (uniqueness, depth, relevance)
- Optimize your internal linking to push priority pages
❓ Frequently Asked Questions
Combien de temps faut-il pour que Google crawle une URL découverte non crawlée après correction ?
Un taux de 30% d'URLs découvertes non crawlées est-il normal ?
Faut-il retirer du sitemap les URLs découvertes non crawlées ?
Google peut-il pénaliser un site avec beaucoup d'URLs découvertes non crawlées ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 25/08/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.