Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Faut-il vraiment se préoccuper du crawl budget pour votre site ?
- □ Comment Google définit-il réellement le crawl budget et quels leviers peut-on actionner ?
- □ Le crawl budget est-il un concept inventé par Google ou par les SEO ?
- □ Google n'indexe-t-il vraiment qu'une fraction du web à cause de ses coûts de stockage ?
- □ Les requêtes POST plombent-elles vraiment votre crawl budget ?
- □ Le crawl budget d'une nouvelle section est-il hérité de la qualité du site principal ?
- □ Les codes 503 et 429 peuvent-ils vraiment réduire votre crawl budget ?
- □ Peut-on vraiment piloter son crawl budget depuis Google Search Console ?
- □ HTTP/2 améliore-t-il vraiment votre crawl budget ?
- □ Faut-il bloquer l'indexation de vos fichiers JavaScript pour optimiser le crawl budget ?
- □ Les 404 et robots.txt gaspillent-ils vraiment votre crawl budget ?
- □ Faut-il bloquer vos fichiers JavaScript décoratifs pour optimiser votre crawl budget ?
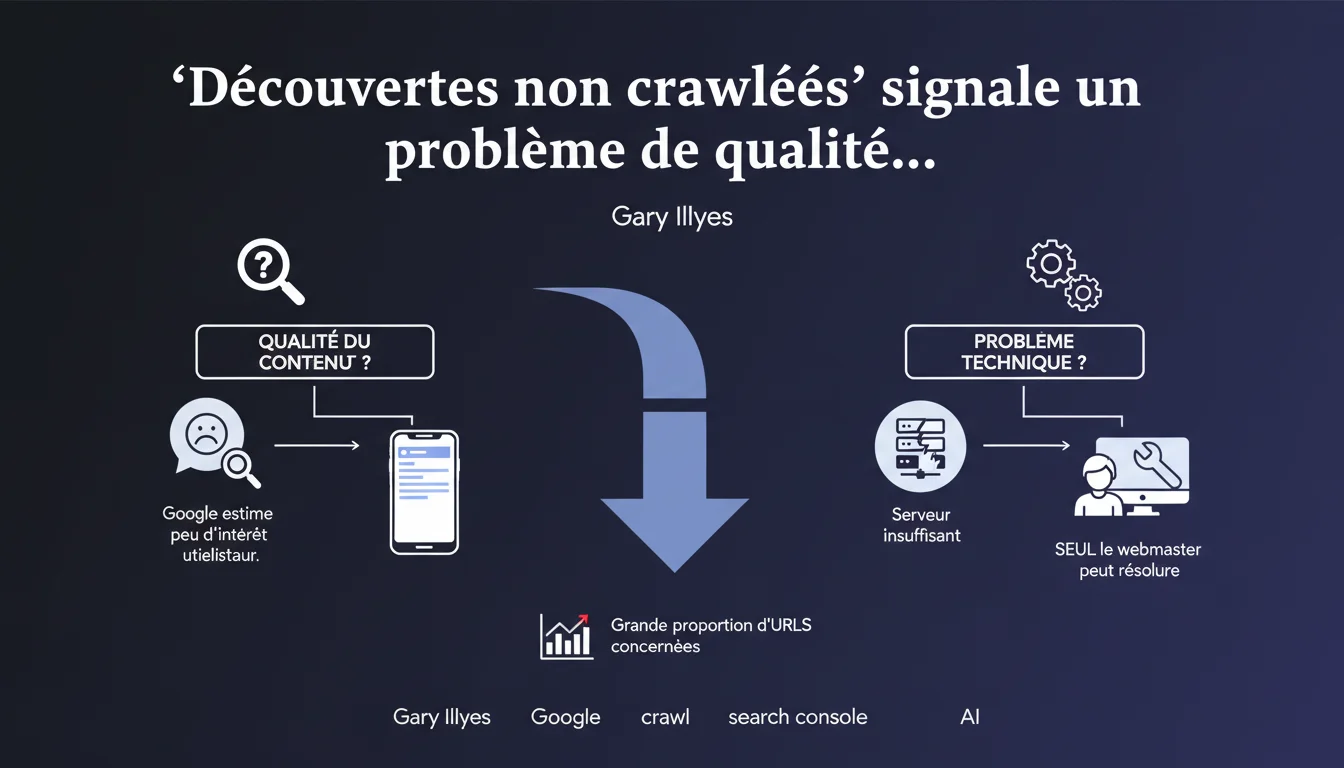
Une forte proportion d'URLs en statut 'découvertes mais non crawlées' dans Search Console signale soit un contenu jugé sans intérêt par Google, soit un serveur techniquement défaillant. Google ne crawle pas ce qu'il estime inutile pour ses utilisateurs — ou ce qu'il ne peut pas crawler correctement.
Ce qu'il faut comprendre
Que signifie exactement ce statut 'découvert non crawlé' ?
Google a identifié l'URL — via un lien interne, externe ou un sitemap — mais a décidé de ne pas la crawler. Ce n'est pas un oubli : c'est un choix délibéré de l'algorithme.
Ce statut indique que Googlebot a priorisé d'autres pages de votre site. Il estime que ces URLs ne méritent pas un crawl immédiat, voire jamais.
Pourquoi Google refuse-t-il de crawler certaines pages ?
Deux scénarios principaux selon Gary Illyes : problème de qualité ou problème technique.
Si c'est un problème de qualité, Google pense que le contenu n'intéresse personne — pages dupliquées, thin content, facettes inutiles, fiches produits hors stock. Si c'est technique, votre serveur répond trop lentement, timeout, erreurs 5xx sporadiques. Dans les deux cas, Googlebot économise son crawl budget.
Comment distinguer un problème de qualité d'un problème technique ?
Analysez les logs serveur. Si Googlebot tente de crawler mais reçoit des erreurs ou des temps de réponse catastrophiques, c'est technique. Si Googlebot ne tente même pas, c'est un signal qualité.
Vérifiez aussi le type d'URLs concernées : des milliers de pages de filtres à facettes ? Problème d'architecture. Des fiches produits récentes avec du contenu unique ? Creusez côté serveur.
- Découvert non crawlé n'est pas un bug Google — c'est un verdict sur votre contenu ou votre infrastructure
- Google priorise son crawl budget : il ne va pas crawler ce qu'il juge sans valeur
- Un audit logs serveur permet de distinguer refus technique vs refus éditorial
- Une forte proportion de ce statut doit déclencher une analyse critique de votre site
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment ce qu'on observe sur le terrain ?
Oui, et c'est brutal. On observe régulièrement des sites avec 60-70% d'URLs découvertes non crawlées — souvent des e-commerce mal maîtrisés qui génèrent des milliers de combinaisons de filtres ou des sites WordPress qui indexent n'importe quoi via le sitemap.
Ce que Gary Illyes ne dit pas : Google peut aussi placer volontairement des URLs en « découvert non crawlé » pour tester la réaction du site. Si vous corrigez un problème technique, Googlebot revient — parfois en quelques heures. Si vous nettoyez du contenu low-quality, l'effet est plus lent mais mesurable.
Faut-il systématiquement s'alarmer d'un taux élevé de découvertes non crawlées ?
Non. Ça dépend des URLs concernées. Si ce sont des pages de pagination old-school, des archives de blog de 2008 ou des paramètres de tracking, tant mieux que Google ne les crawle pas.
Le problème survient quand ce sont vos nouvelles fiches produits, vos landing pages stratégiques ou vos contenus éditoriaux frais. Là, vous avez un vrai souci — soit Google ne les trouve pas pertinentes, soit votre serveur est à genoux.
Peut-on forcer Google à crawler ces URLs ?
Non. [À vérifier] mais l'expérience terrain montre que demander un crawl via Search Console sur 500 URLs découvertes non crawlées ne change rien. Google revient quand il estime que ça vaut le coup — ou jamais.
La seule solution : corriger la cause profonde. Améliorer le contenu, optimiser le serveur, nettoyer l'architecture. Googlebot n'est pas un outil à la demande, c'est un algorithme qui priorise selon sa propre logique économique.
Impact pratique et recommandations
Que faire concrètement si vous avez un taux élevé de découvertes non crawlées ?
D'abord, segmentez les URLs concernées. Exportez le rapport Search Console, classez par typologie : produits, catégories, blog, facettes, paramètres. Identifiez les patterns.
Ensuite, croisez avec vos logs serveur sur la même période. Googlebot tente-t-il de crawler et échoue ? Ou il n'essaie même pas ? Si tentatives + erreurs 5xx ou timeouts, c'est un problème serveur. Si aucune tentative, c'est un signal qualité ou crawl budget.
Quelles erreurs éviter absolument ?
Ne surtout pas forcer l'indexation via sitemap de milliers d'URLs low-quality en espérant que Google les crawle. Vous empirez le problème : Google détecte que vous lui proposez massivement du contenu qu'il juge sans valeur, et ça dégrade la perception globale de votre site.
Autre erreur classique : déployer un serveur sous-dimensionné pour un catalogue produit de 50 000 références. Si votre temps de réponse serveur dépasse 500ms en moyenne, Googlebot va ralentir son crawl — voire abandonner certaines sections.
Comment vérifier que votre site est conforme et optimisé ?
- Analysez le ratio découvert/crawlé sur les 3 derniers mois dans Search Console
- Exportez les URLs en statut « découvert non crawlé » et segmentez par type de page
- Vérifiez vos logs serveur : Googlebot tente-t-il de crawler ces URLs ?
- Mesurez le temps de réponse serveur moyen (objectif : sous 200ms)
- Identifiez les URLs sans valeur ajoutée et bloquez-les via robots.txt ou noindex
- Améliorez le contenu des pages stratégiques non crawlées (unicité, profondeur, pertinence)
- Optimisez votre maillage interne pour pousser les pages prioritaires
❓ Questions frequentes
Combien de temps faut-il pour que Google crawle une URL découverte non crawlée après correction ?
Un taux de 30% d'URLs découvertes non crawlées est-il normal ?
Faut-il retirer du sitemap les URLs découvertes non crawlées ?
Google peut-il pénaliser un site avec beaucoup d'URLs découvertes non crawlées ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.