Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Faut-il vraiment se préoccuper du crawl budget pour votre site ?
- □ Comment Google définit-il réellement le crawl budget et quels leviers peut-on actionner ?
- □ Google n'indexe-t-il vraiment qu'une fraction du web à cause de ses coûts de stockage ?
- □ Les requêtes POST plombent-elles vraiment votre crawl budget ?
- □ Le crawl budget d'une nouvelle section est-il hérité de la qualité du site principal ?
- □ Les codes 503 et 429 peuvent-ils vraiment réduire votre crawl budget ?
- □ Peut-on vraiment piloter son crawl budget depuis Google Search Console ?
- □ HTTP/2 améliore-t-il vraiment votre crawl budget ?
- □ Pourquoi vos URLs 'découvertes mais non crawlées' révèlent-elles un problème de fond ?
- □ Faut-il bloquer l'indexation de vos fichiers JavaScript pour optimiser le crawl budget ?
- □ Les 404 et robots.txt gaspillent-ils vraiment votre crawl budget ?
- □ Faut-il bloquer vos fichiers JavaScript décoratifs pour optimiser votre crawl budget ?
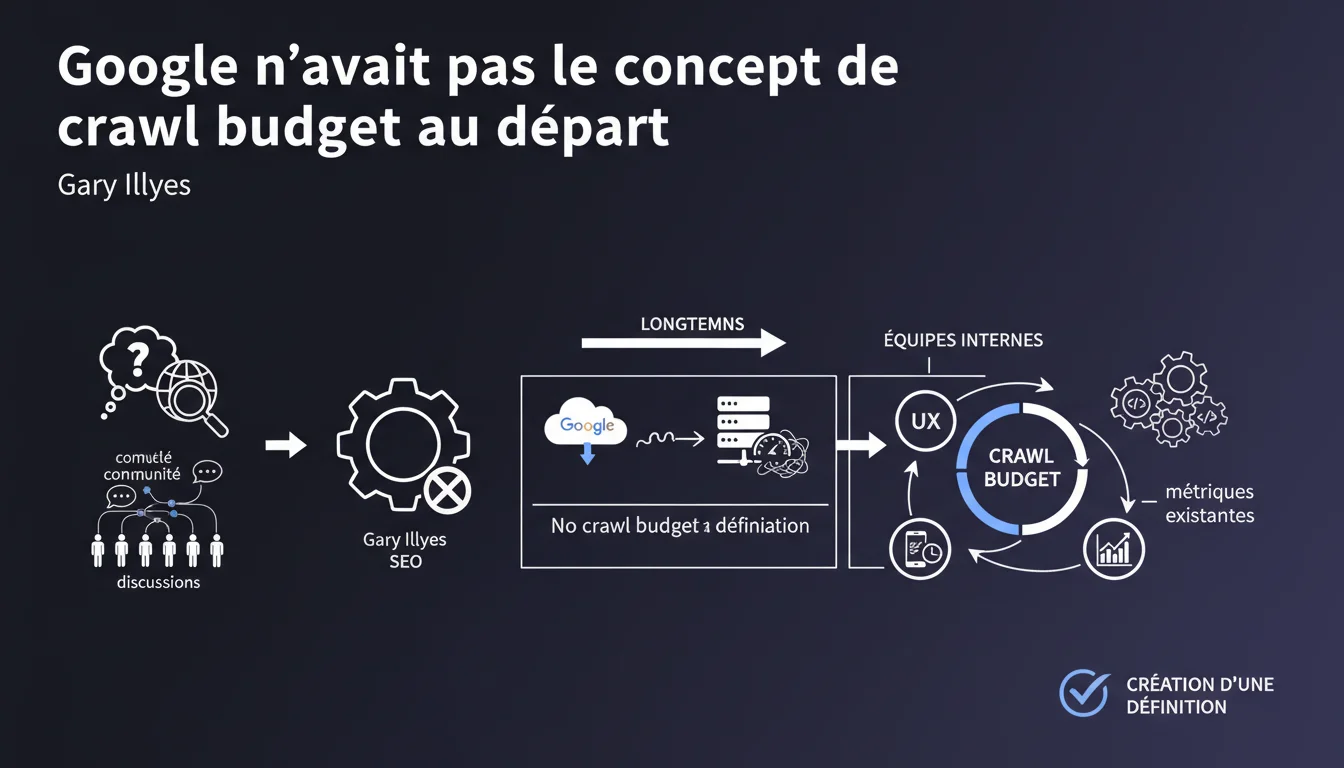
Google n'avait pas de définition officielle du crawl budget au départ. Face aux discussions insistantes de la communauté SEO, l'entreprise a finalement mappé des métriques internes existantes pour créer une définition qui colle à ce que les praticiens appelaient déjà « crawl budget ». Autrement dit : le concept existait sur le terrain avant d'être formalisé par Google.
Ce qu'il faut comprendre
Pourquoi Google a-t-il fini par définir le crawl budget ?
Pendant des années, Google répétait qu'il n'y avait pas de crawl budget — en tout cas, pas sous ce terme. Les SEO, eux, observaient pourtant des comportements clairs : certaines pages n'étaient jamais crawlées, d'autres l'étaient plusieurs fois par jour.
Face à cette dissonance, Google a décidé de formaliser une définition en interne. Plusieurs équipes ont mappé des métriques existantes pour donner un cadre officiel à ce que la communauté appelait déjà « crawl budget ». Ce n'est pas un nouveau système — c'est une reconnaissance tardive d'un phénomène observé sur le terrain.
Qu'est-ce que cela révèle sur la communication de Google ?
Cette déclaration illustre un schéma récurrent : Google nie l'existence d'un concept jusqu'à ce qu'il devienne impossible de l'ignorer. Ensuite, une définition officielle apparaît, souvent vague, qui permet de répondre aux questions sans vraiment s'engager.
Le crawl budget n'est pas né dans les labs de Mountain View. Il a été théorisé par les praticiens, validé par l'observation, puis récupéré par Google pour éviter que la communauté ne crée sa propre taxonomie parallèle.
Quelles sont les implications concrètes pour un SEO ?
D'abord, cela confirme que les observations terrain ont autant de valeur que les déclarations officielles — parfois même plus. Si tu constates qu'un site de 50 000 pages ne voit que 2 000 pages crawlées par mois, ce n'est pas une hallucination, c'est un problème réel.
Ensuite, ça rappelle que Google adapte sa communication en fonction de la pression externe. Les métriques existaient déjà en interne, mais sans une définition publique, impossible de formuler des recommandations claires. Maintenant, on peut au moins dialoguer avec un vocabulaire commun.
- Le crawl budget n'est pas un mythe — Google l'a reconnu après des années de déni.
- Les métriques internes existaient avant la définition publique.
- La formalisation a été déclenchée par la pression de la communauté SEO.
- Ce pattern se répète : Google nie, puis admet, puis définit à sa façon.
- Les observations terrain restent un outil de diagnostic plus fiable que les déclarations vagues.
Avis d'un expert SEO
Cette déclaration est-elle vraiment un aveu d'impuissance ?
Oui et non. D'un côté, Gary Illyes reconnaît que Google a dû s'adapter au vocabulaire des SEO plutôt que d'imposer le sien. C'est rare. Ça montre que la communauté a réussi à forcer une transparence minimale sur un sujet que Google aurait préféré garder flou.
De l'autre, cette « définition » reste une boîte noire. On sait que le crawl budget existe, qu'il dépend de facteurs comme la qualité du site, la vélocité de publication, la popularité des pages. Mais les seuils ? Les algorithmes précis ? Les leviers exacts pour l'optimiser ? Toujours dans le brouillard. [À vérifier] : Google parle de « métriques mappées », mais ne précise jamais lesquelles ni comment elles interagissent.
Les praticiens avaient-ils raison avant Google ?
Absolument. Dès les années 2010, des SEO comme Patrick Stox ou Christoph Cemper documentaient des patterns clairs : ralentissement du crawl sur les sites massifs mal structurés, explosion du crawl sur les sites d'actualité, impact de la vitesse serveur, du crawl trap, du duplicate content.
Google n'a rien inventé — il a labellisé un phénomène déjà documenté. La seule nouveauté, c'est qu'on peut maintenant utiliser le terme « crawl budget » dans un email à un client sans passer pour un charlatan.
Que faire face à cette opacité persistante ?
Soyons honnêtes : la déclaration de Google ne change rien à ta façon de travailler. Tu continues d'analyser les logs, de surveiller la fréquence de crawl dans la Search Console, de traquer les pages orphelines et les crawl traps. Les méthodes empiriques restent plus fiables que les communiqués officiels.
Si Google refuse de donner des seuils précis, c'est probablement parce qu'ils sont dynamiques, variables selon les sites, et ajustés en temps réel. Ou alors parce que les révéler permettrait à des acteurs malveillants d'exploiter le système. Dans les deux cas, on travaille avec ce qu'on a : des observations, des hypothèses, des tests.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl budget ?
Commence par analyser tes logs serveur — c'est la seule façon de savoir quelles pages Google crawle réellement, à quelle fréquence, et lesquelles sont ignorées. Si tu n'as pas accès aux logs, la Search Console te donnera une vision partielle via le rapport de couverture.
Ensuite, traque les crawl traps : pagination infinie, facettes mal gérées, paramètres d'URL inutiles, duplicate content massif. Chaque page crawlée pour rien bouffe du budget qui aurait pu servir à indexer une page stratégique.
- Audite tes logs serveur pour identifier les pages crawlées vs. les pages ignorées
- Bloque les pages inutiles via robots.txt ou noindex (facettes, pages de recherche interne, duplicates)
- Optimise la vitesse serveur et le temps de réponse — un serveur lent ralentit le crawl
- Priorise le maillage interne vers les pages stratégiques pour orienter Googlebot
- Nettoie les redirections en chaîne et les erreurs 404 qui saturent inutilement le crawl
- Utilise le sitemap XML pour signaler les pages importantes, sans noyer Google sous 100 000 URLs
Quelles erreurs éviter absolument ?
Ne te repose pas uniquement sur la Search Console pour diagnostiquer un problème de crawl. Elle te montre ce que Google veut te montrer, pas la réalité complète. Les logs, c'est la vérité terrain.
Autre erreur classique : croire qu'un sitemap XML suffit à forcer le crawl d'un site massif. Non. Si ta structure est pourrie, si tes pages sont lentes, si ton contenu est dupliqué à 80 %, un sitemap ne sauvera rien. Le crawl budget, c'est une conséquence de la qualité globale du site, pas un levier isolé.
Comment vérifier que ton site est bien optimisé ?
Compare la fréquence de crawl des pages stratégiques vs. des pages secondaires. Si Google crawle tes mentions légales trois fois par jour mais ignore ta fiche produit phare, il y a un souci de signal d'importance.
Vérifie aussi le ratio pages crawlées / pages indexées. Si Google crawle 10 000 pages par mois mais n'en indexe que 1 000, c'est que 9 000 pages sont jugées inutiles ou de mauvaise qualité. C'est un indicateur clair de gâchis de crawl budget.
En résumé : Le crawl budget existe, Google l'a reconnu, mais les leviers d'optimisation n'ont pas changé. Structure propre, contenu unique, vitesse serveur, maillage stratégique. L'analyse de logs reste l'outil diagnostique de référence.
Ces optimisations techniques peuvent être complexes à déployer seul, surtout sur des sites massifs ou mal documentés. Si tu te retrouves coincé entre des priorités floues et des métriques contradictoires, faire appel à une agence SEO spécialisée peut te faire gagner des mois — et éviter des erreurs coûteuses qui plomberaient ton crawl budget pour longtemps.
❓ Questions frequentes
Google a-t-il vraiment créé le concept de crawl budget ou l'a-t-il simplement reconnu ?
Le crawl budget affecte-t-il tous les sites de la même manière ?
Peut-on augmenter son crawl budget manuellement ?
La Search Console suffit-elle pour diagnostiquer un problème de crawl budget ?
Un sitemap XML peut-il compenser une mauvaise architecture de site ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.