Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Faut-il vraiment se préoccuper du crawl budget pour votre site ?
- □ Comment Google définit-il réellement le crawl budget et quels leviers peut-on actionner ?
- □ Le crawl budget est-il un concept inventé par Google ou par les SEO ?
- □ Google n'indexe-t-il vraiment qu'une fraction du web à cause de ses coûts de stockage ?
- □ Les requêtes POST plombent-elles vraiment votre crawl budget ?
- □ Le crawl budget d'une nouvelle section est-il hérité de la qualité du site principal ?
- □ Les codes 503 et 429 peuvent-ils vraiment réduire votre crawl budget ?
- □ Peut-on vraiment piloter son crawl budget depuis Google Search Console ?
- □ Pourquoi vos URLs 'découvertes mais non crawlées' révèlent-elles un problème de fond ?
- □ Faut-il bloquer l'indexation de vos fichiers JavaScript pour optimiser le crawl budget ?
- □ Les 404 et robots.txt gaspillent-ils vraiment votre crawl budget ?
- □ Faut-il bloquer vos fichiers JavaScript décoratifs pour optimiser votre crawl budget ?
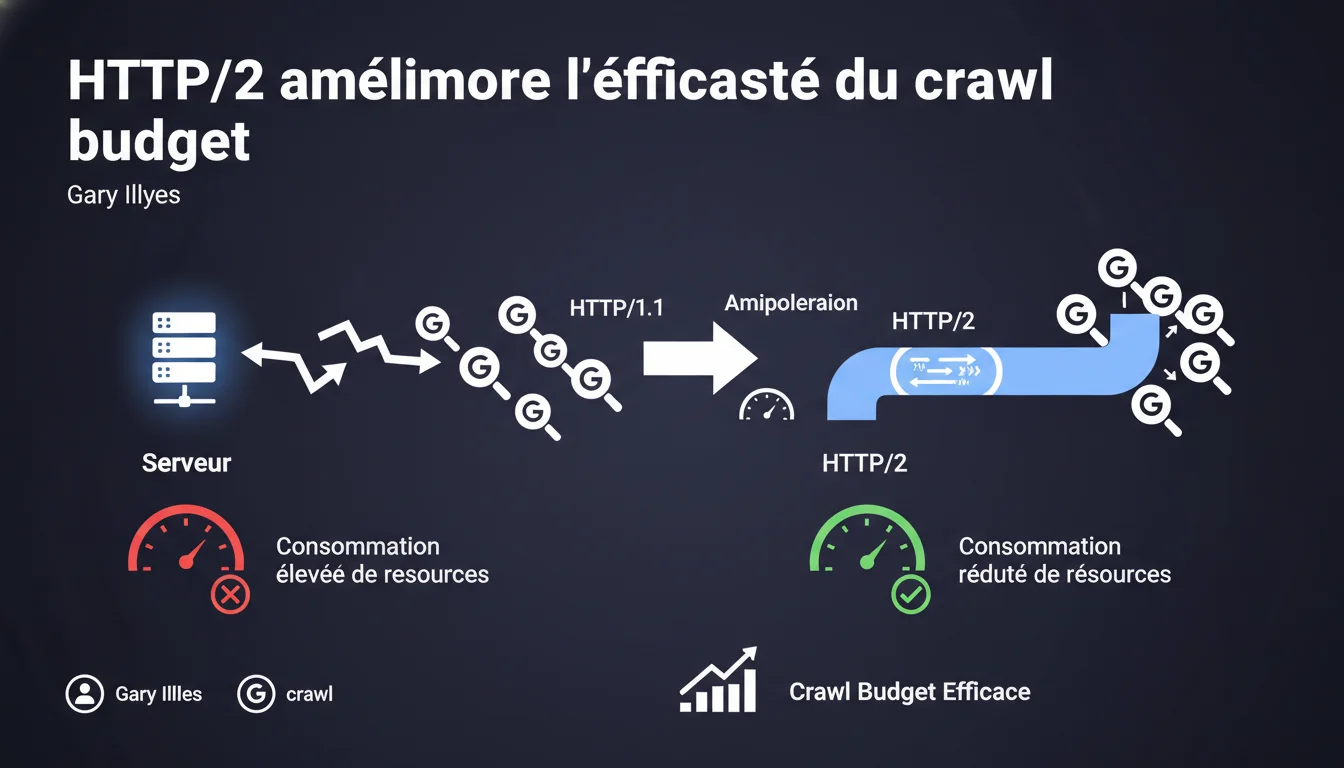
Gary Illyes confirme que HTTP/2 optimise le crawl budget en permettant à Googlebot d'utiliser une seule connexion pour streamer plusieurs requêtes simultanées, au lieu d'ouvrir plusieurs connexions parallèles. Cette approche réduit la charge serveur et améliore l'efficacité du crawl. Pour les sites à fort volume de pages, cette optimisation peut faire la différence entre un crawl complet et un crawl partiel.
Ce qu'il faut comprendre
Pourquoi Googlebot préfère-t-il HTTP/2 au HTTP/1.1 ?
La différence fondamentale tient au multiplexage des requêtes. Avec HTTP/1.1, Googlebot ouvre plusieurs connexions TCP simultanées pour crawler plusieurs URLs en parallèle, ce qui génère une charge importante côté serveur : handshakes répétés, gestion de multiples sockets, overhead de connexion.
HTTP/2 change la donne en permettant le streaming de multiples requêtes sur une unique connexion. Concrètement, Googlebot établit une connexion TCP, puis envoie des dizaines de requêtes en parallèle sur ce même canal. Le serveur répond dans un flux continu, sans avoir à gérer l'ouverture et la fermeture de connexions multiples.
Qu'est-ce que cela signifie pour le crawl budget en pratique ?
Le crawl budget, c'est la quantité de ressources que Google alloue au crawl de votre site. Cette allocation dépend de deux facteurs principaux : la popularité du site et la capacité du serveur à répondre rapidement sans saturer.
Avec HTTP/2, votre serveur consomme moins de ressources pour servir le même nombre de pages. Résultat : Googlebot peut crawler plus de pages dans le même laps de temps, ou crawler le même nombre de pages en sollicitant moins votre infrastructure. Pour les sites de plusieurs milliers de pages, cette efficacité se traduit par un crawl plus fréquent et plus complet.
Tous les sites bénéficient-ils de la même manière ?
Non. L'impact est proportionnel au volume de pages et à la fréquence de crawl. Un site de 50 pages ne verra aucune différence notable. En revanche, un site e-commerce avec 100 000 fiches produits, ou un site média publiant 200 articles par jour, gagnera significativement en réactivité d'indexation.
Les serveurs déjà sous tension lors des pics de crawl bénéficieront également d'un soulagement immédiat. Si vos logs montrent des erreurs 503 ou des timeouts pendant les passages intensifs de Googlebot, HTTP/2 peut résoudre une partie du problème.
- HTTP/2 réduit le nombre de connexions simultanées ouvertes par Googlebot, allégeant la charge serveur
- Le multiplexage permet de streamer plusieurs requêtes sur une seule connexion TCP
- L'impact est maximal sur les sites à fort volume de pages et ceux qui publient fréquemment
- Les petits sites (moins de 1000 pages) ne verront probablement aucun changement perceptible
- HTTP/2 nécessite HTTPS — impossible de l'activer sur du HTTP non sécurisé
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Oui, et les données de logs le confirment depuis plusieurs années. Dès 2016-2017, quand Googlebot a commencé à supporter HTTP/2, les sites ayant activé le protocole ont constaté une baisse du nombre de connexions simultanées dans leurs logs Apache ou Nginx, accompagnée d'une légère hausse du volume de pages crawlées quotidiennement.
Les serveurs qui peinaient à absorber les rafales de crawl ont vu leur charge CPU et leurs temps de réponse s'améliorer. Mais attention : HTTP/2 ne fait pas de miracles. Si votre serveur est mal configuré ou sous-dimensionné, le problème de fond reste entier. Le protocole optimise la communication, il ne compense pas une infrastructure défaillante.
Quelles nuances faut-il apporter à cette affirmation ?
Gary Illyes parle d'une amélioration « significative », mais ne donne aucun chiffre. [À vérifier] : l'ampleur réelle de l'amélioration varie énormément selon la configuration serveur, le CDN utilisé, et la latence réseau. Certains sites rapportent des gains de 20-30% en volume crawlé, d'autres ne voient rien.
Autre point crucial : HTTP/2 nécessite HTTPS obligatoire. Si vous êtes encore en HTTP pur, vous devez d'abord migrer en HTTPS avant même de penser à HTTP/2. Cette migration elle-même peut poser des problèmes (redirections, mixed content, performances SSL/TLS mal optimisées). HTTP/2 n'est donc pas un quick win pour tout le monde.
Enfin, tous les CDN et configurations serveur ne gèrent pas HTTP/2 de manière optimale. Un Nginx mal configuré, un CDN qui désactive certaines features HTTP/2 par défaut, ou un certificat SSL mal implémenté peuvent annuler les bénéfices attendus.
Dans quels cas cette optimisation ne sert à rien ?
Si votre site a moins de 1000 pages et publie peu de contenu neuf, Googlebot le crawle déjà entièrement sans difficulté. HTTP/2 n'apportera rien. Idem si votre goulot d'étranglement n'est pas le protocole HTTP mais la génération dynamique des pages : une base de données lente, des requêtes SQL mal optimisées, un CMS mal configuré.
De même, si votre problème d'indexation est lié à du contenu dupliqué, des balises noindex mal placées ou une architecture en silos trop profonde, HTTP/2 ne changera rien. Le crawl sera peut-être plus efficace, mais les pages problématiques resteront problématiques.
Impact pratique et recommandations
Comment vérifier que HTTP/2 est activé sur mon site ?
Ouvrez Chrome DevTools, onglet Network, rechargez votre page et inspectez la colonne « Protocol ». Si vous voyez « h2 », HTTP/2 est actif. Si vous voyez « http/1.1 », ce n'est pas le cas. Vous pouvez aussi utiliser des outils en ligne comme KeyCDN HTTP/2 Test ou tools.keycdn.com/http2-test.
Côté serveur, consultez vos logs d'accès. Googlebot identifie désormais les requêtes HTTP/2 dans son User-Agent ou via des headers spécifiques selon votre configuration. Si vous voyez une baisse du nombre de connexions simultanées et une hausse du nombre de requêtes par connexion, c'est que HTTP/2 fonctionne correctement.
Quelles erreurs éviter lors de la migration vers HTTP/2 ?
La première erreur, c'est de croire qu'activer HTTP/2 suffit. Si votre certificat SSL est mal configuré (protocoles obsolètes, cipher suites faibles), les performances peuvent se dégrader. Vérifiez votre configuration SSL avec SSL Labs et visez au minimum un A.
Deuxième piège : ne pas tester la charge serveur avant et après. HTTP/2 réduit le nombre de connexions, mais chaque connexion transporte plus de requêtes. Si votre serveur n'est pas dimensionné pour gérer ce flux, vous risquez des timeouts ou des erreurs 503 en cas de pic de crawl.
Troisième erreur : oublier de vérifier la compatibilité avec votre CDN. Certains CDN activent HTTP/2 par défaut, d'autres nécessitent une configuration manuelle. Cloudflare, Fastly et AWS CloudFront supportent HTTP/2, mais avec des nuances dans l'implémentation. Vérifiez la documentation de votre fournisseur.
Que faut-il faire concrètement pour maximiser les bénéfices ?
- Migrer vers HTTPS si ce n'est pas déjà fait — HTTP/2 ne fonctionne qu'en HTTPS
- Activer HTTP/2 sur votre serveur (Nginx, Apache, LiteSpeed) ou via votre CDN
- Vérifier la configuration SSL/TLS avec SSL Labs et corriger les faiblesses détectées
- Surveiller les logs serveur et la Search Console pendant 2-3 semaines pour mesurer l'impact sur le crawl
- Optimiser les temps de réponse serveur (TTFB) — HTTP/2 ne compense pas un backend lent
- Désactiver les anciennes optimisations HTTP/1.1 devenues contre-productives (domain sharding, sprite CSS excessif)
- Tester la charge serveur en conditions réelles pour éviter les mauvaises surprises lors des pics de crawl
❓ Questions frequentes
HTTP/2 est-il obligatoire pour un bon référencement ?
Peut-on activer HTTP/2 sans HTTPS ?
Quels sont les risques d'activer HTTP/2 ?
HTTP/2 améliore-t-il aussi la vitesse de chargement pour les utilisateurs ?
Faut-il désactiver les optimisations HTTP/1.1 après avoir migré vers HTTP/2 ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.