Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Faut-il vraiment se préoccuper du crawl budget pour votre site ?
- □ Comment Google définit-il réellement le crawl budget et quels leviers peut-on actionner ?
- □ Le crawl budget est-il un concept inventé par Google ou par les SEO ?
- □ Google n'indexe-t-il vraiment qu'une fraction du web à cause de ses coûts de stockage ?
- □ Les requêtes POST plombent-elles vraiment votre crawl budget ?
- □ Le crawl budget d'une nouvelle section est-il hérité de la qualité du site principal ?
- □ Les codes 503 et 429 peuvent-ils vraiment réduire votre crawl budget ?
- □ Peut-on vraiment piloter son crawl budget depuis Google Search Console ?
- □ HTTP/2 améliore-t-il vraiment votre crawl budget ?
- □ Pourquoi vos URLs 'découvertes mais non crawlées' révèlent-elles un problème de fond ?
- □ Faut-il bloquer l'indexation de vos fichiers JavaScript pour optimiser le crawl budget ?
- □ Faut-il bloquer vos fichiers JavaScript décoratifs pour optimiser votre crawl budget ?
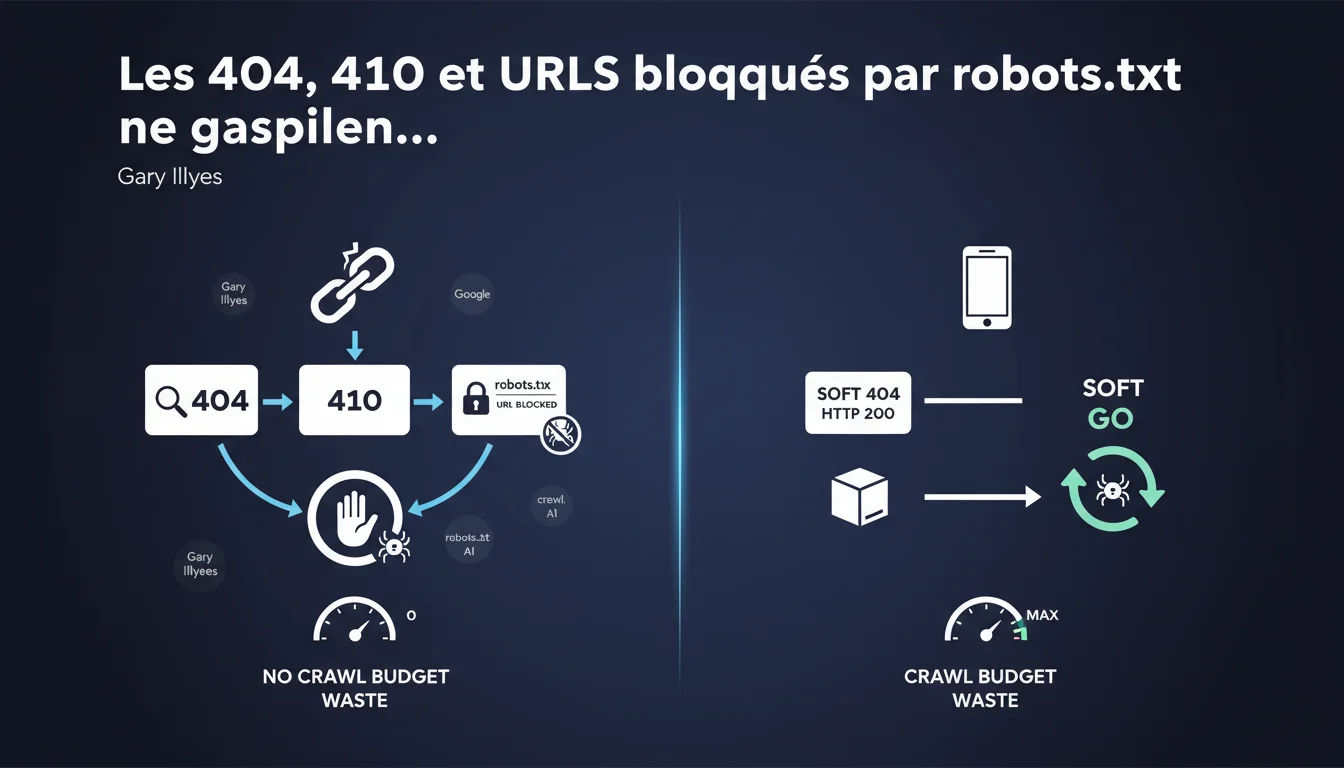
Les codes 404, 410 et les URLs bloquées par robots.txt ne consomment pas de crawl budget selon Google. En revanche, les soft 404 — ces pages qui renvoient un code 200 mais sans contenu réel — gaspillent vos ressources de crawl. La distinction est technique mais cruciale pour optimiser l'exploration de votre site.
Ce qu'il faut comprendre
Pourquoi Google distingue-t-il les 404 des soft 404 ?
Google ne reçoit que le code de statut HTTP pour les 404 et 410, sans télécharger le contenu de la page. Le bot crawle l'URL, obtient le code d'erreur, et passe immédiatement à la suivante. Pas de traitement lourd, pas de rendu, pas de ressources mobilisées.
Les soft 404, eux, renvoient un code 200 — signal que la page existe. Google doit alors analyser le contenu pour comprendre qu'il s'agit en fait d'une erreur. Cette détection mobilise des ressources : téléchargement, parsing, évaluation sémantique. C'est là que le crawl budget file entre vos doigts.
Qu'en est-il des URLs bloquées par robots.txt ?
Une URL bloquée par robots.txt ne génère aucune requête HTTP complète. Googlebot lit le fichier robots.txt, identifie l'interdiction, et ignore l'URL sans même tenter de la charger. Zéro byte téléchargé, zéro traitement.
Concrètement ? Bloquer des sections entières de votre site via robots.txt ne pénalise pas votre crawl budget. C'est même une méthode efficace pour canaliser le bot vers vos pages stratégiques — à condition de savoir ce que vous bloquez.
Quelle est la définition exacte du crawl budget selon Google ?
Le crawl budget est la quantité de pages que Googlebot accepte d'explorer sur votre site dans un laps de temps donné. Cette limite dépend de la santé technique de votre site, de sa popularité, et de la vitesse de vos serveurs.
Google ajuste ce budget en fonction de vos performances. Un site qui répond lentement ou multiplie les erreurs verra son budget réduit. À l'inverse, un site technique propre et réactif peut obtenir davantage de ressources d'exploration.
- Les 404 et 410 ne consomment pas de crawl budget car Google ne traite que le code HTTP
- Les soft 404 gaspillent le budget car Google doit analyser le contenu pour détecter l'erreur
- Les URLs bloquées par robots.txt sont ignorées sans consommation de ressources
- Le crawl budget est une ressource finie qui dépend de votre performance technique
- Optimiser la gestion des erreurs permet de concentrer le budget sur vos pages stratégiques
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est une des rares affirmations de Google qui correspond pile-poil à ce qu'on observe dans les logs. Les 404 apparaissent dans les fichiers de log comme des requêtes ultra-rapides : une ligne, un code, terminé. Aucun poids sur le serveur.
Les soft 404, par contre, c'est le cauchemar discret. Ils génèrent des requêtes complètes — souvent plusieurs secondes de traitement — et Google doit mobiliser son analyse sémantique pour comprendre qu'il s'agit d'une page vide. Sur un site de moyenne taille avec quelques milliers de soft 404, l'impact sur le crawl budget est mesurable.
Faut-il systématiquement corriger tous les 404 ?
Non, et c'est là que beaucoup de SEO se trompent. Un 404 propre sur une URL qui n'a jamais eu de contenu pertinent ou qui n'a aucun backlink n'est pas un problème. Google l'enregistre, le marque comme mort, et n'y revient que rarement.
Le vrai problème, c'est quand des URLs stratégiques — avec du trafic historique, des backlinks, ou mentionnées dans votre maillage interne — renvoient un 404 sans redirection. Là, vous perdez du jus et de l'autorité. Mais un 404 sur une vieille pagination sans intérêt ? Laissez tomber.
Le robots.txt est-il toujours la meilleure solution pour gérer le crawl ?
Soyons honnêtes : le robots.txt est un outil brutal. Bloquer une section entière peut sembler pratique, mais ça empêche aussi Google de découvrir les liens présents dans ces pages. Si ces URLs contiennent du maillage interne vers vos pages importantes, vous créez des points morts dans votre architecture.
La combinaison robots.txt + noindex reste souvent plus intelligente pour les contenus à faible valeur : vous laissez Google explorer pour suivre les liens, mais vous empêchez l'indexation. [À vérifier] sur des volumes massifs — certains sites rapportent une réduction du budget avec cette approche si les pages noindex sont trop nombreuses.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser son crawl budget ?
D'abord, identifiez vos soft 404. Utilisez Google Search Console (section Couverture), croisez avec vos logs serveur, et vérifiez les pages qui renvoient 200 mais affichent un message d'erreur ou un contenu vide. Ce sont vos vampires de crawl budget.
Ensuite, corrigez-les en renvoyant un véritable code 404 ou 410. Si l'URL avait du contenu pertinent dans le passé, redirigez vers une alternative en 301. Si elle n'a jamais servi à rien, un 410 (Gone) est plus propre qu'un 404 — il signale à Google que la page ne reviendra jamais.
Quelles erreurs éviter dans la gestion des codes HTTP ?
Ne bloquez jamais par robots.txt une URL que vous avez l'intention de rediriger. Google ne peut pas suivre une redirection qu'il n'a pas le droit de crawler. Résultat : l'URL reste en erreur dans la Search Console, et vous perdez le transfert de PageRank.
Évitez aussi les chaînes de redirections inutiles. Chaque saut supplémentaire (301 → 301 → 200) consomme du budget et dilue l'autorité transmise. Redirigez toujours directement vers la destination finale.
Comment vérifier que votre site est conforme ?
Analysez vos logs serveur sur une période de 30 jours minimum. Isolez les URLs crawlées par Googlebot, et regardez la répartition des codes HTTP. Si vous voyez une proportion anormale de 200 sur des pages vides ou génériques, vous avez un problème de soft 404.
Utilisez Screaming Frog ou Sitebulb pour simuler un crawl et repérer les pages qui renvoient 200 mais contiennent des patterns de contenu vide (« Aucun résultat », « Page introuvable », etc.). Automatisez cette détection si votre site génère du contenu dynamique.
- Auditer la Search Console section Couverture pour repérer les soft 404 signalés par Google
- Analyser les logs serveur pour identifier les URLs qui consomment du crawl budget sans valeur
- Corriger les soft 404 en renvoyant un véritable code 404 ou 410
- Rediriger en 301 les URLs historiques avec backlinks vers une alternative pertinente
- Éviter de bloquer par robots.txt des URLs avec des backlinks ou du maillage interne stratégique
- Supprimer les chaînes de redirections pour limiter la dilution du PageRank
- Monitorer régulièrement la répartition des codes HTTP dans vos logs pour anticiper les dérives
❓ Questions frequentes
Un 404 peut-il nuire au référencement de mon site ?
Quelle est la différence entre un 404 et un 410 ?
Faut-il bloquer les pages paginées par robots.txt pour économiser du crawl budget ?
Comment détecter automatiquement les soft 404 sur un gros site ?
Peut-on bloquer par robots.txt des URLs déjà indexées ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.