Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Faut-il vraiment se préoccuper du crawl budget pour votre site ?
- □ Comment Google définit-il réellement le crawl budget et quels leviers peut-on actionner ?
- □ Le crawl budget est-il un concept inventé par Google ou par les SEO ?
- □ Les requêtes POST plombent-elles vraiment votre crawl budget ?
- □ Le crawl budget d'une nouvelle section est-il hérité de la qualité du site principal ?
- □ Les codes 503 et 429 peuvent-ils vraiment réduire votre crawl budget ?
- □ Peut-on vraiment piloter son crawl budget depuis Google Search Console ?
- □ HTTP/2 améliore-t-il vraiment votre crawl budget ?
- □ Pourquoi vos URLs 'découvertes mais non crawlées' révèlent-elles un problème de fond ?
- □ Faut-il bloquer l'indexation de vos fichiers JavaScript pour optimiser le crawl budget ?
- □ Les 404 et robots.txt gaspillent-ils vraiment votre crawl budget ?
- □ Faut-il bloquer vos fichiers JavaScript décoratifs pour optimiser votre crawl budget ?
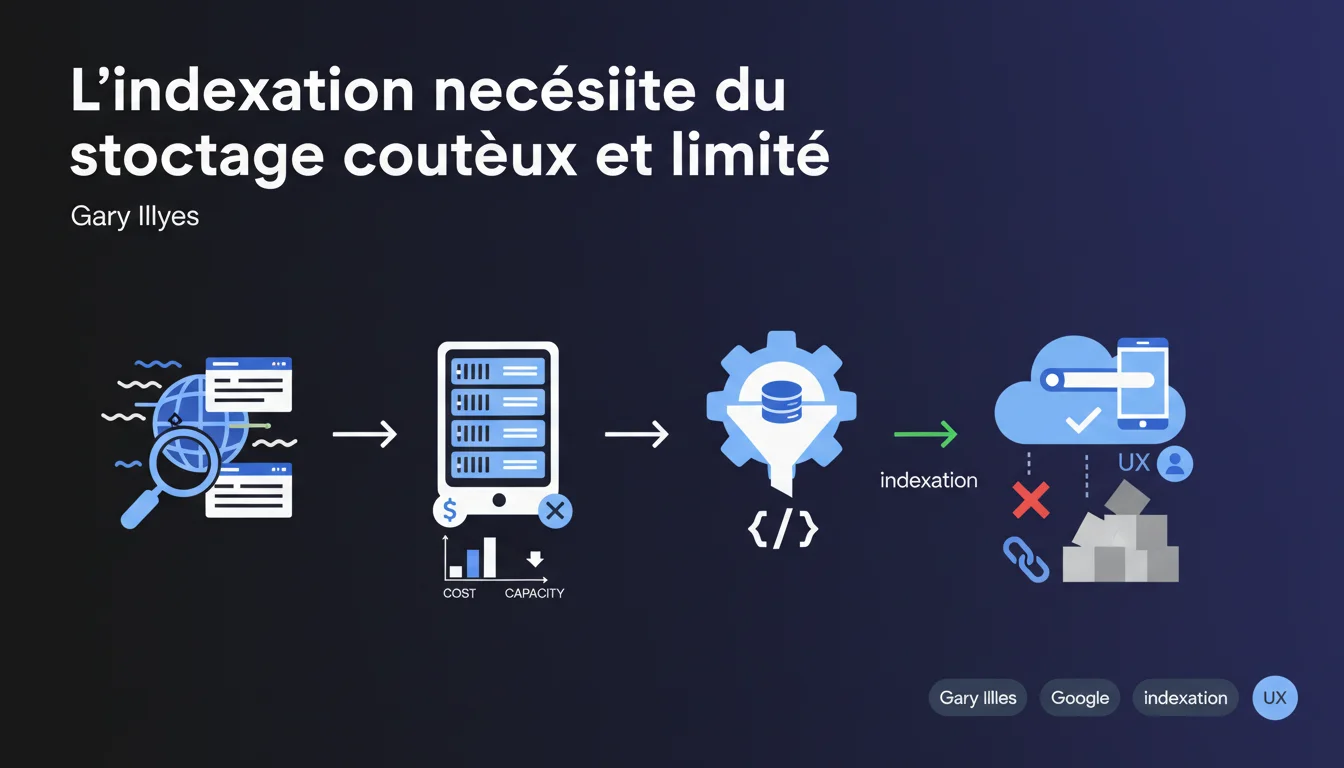
Google assume ouvertement que sa capacité de stockage n'est pas infinie et que l'indexation coûte cher. Résultat : seul le contenu susceptible d'être recherché par les utilisateurs est indexé. Pour les praticiens SEO, cela signifie qu'optimiser la « désirabilité » de vos pages aux yeux de Google devient aussi crucial que de les rendre techniquement crawlables.
Ce qu'il faut comprendre
Pourquoi Google avoue-t-il publiquement ses limites techniques ?
Contrairement à l'image d'une infrastructure sans limites, Google reconnaît ici que l'indexation a un coût réel — disques durs, SSD, mémoire, électricité, maintenance. Cette déclaration de Gary Illyes casse le mythe d'un moteur qui indexerait tout par défaut.
La véritable information : Google opère des choix stratégiques d'indexation basés sur la probabilité qu'un contenu soit recherché. Ce n'est pas une question de volume brut, mais de pertinence anticipée.
Qu'est-ce que cela change concrètement pour un site web ?
Si votre contenu n'est pas jugé « désirable » par Google — comprendre : susceptible de générer des clics depuis les résultats de recherche — il peut tout simplement ne jamais entrer dans l'index. Même si votre site est techniquement parfait.
Cela rejoint des observations terrain : pages orphelines ignorées, contenus à faible potentiel de trafic écartés, sites entiers exclus malgré un crawl régulier. Le crawl budget ne garantit pas l'indexation.
Quels signaux Google utilise-t-il pour décider ?
Google ne détaille pas ses critères exacts, mais on peut déduire plusieurs axes : popularité du site, fraîcheur du contenu, signaux comportementaux existants, autorité thématique, liens internes et externes. Un contenu isolé, sans contexte, sans liens, sans trafic préexistant a peu de chances d'être priorisé.
- Google n'indexe pas tout le web, seulement ce qu'il juge potentiellement recherché
- Le coût de stockage est un facteur économique réel qui influence les choix d'indexation
- La capacité technique à crawler un contenu ne garantit pas son indexation
- Les sites doivent prouver que leur contenu mérite d'être stocké et servi aux utilisateurs
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Absolument. Depuis des années, on constate que des pages techniquement accessibles ne s'indexent jamais. Google Search Console regorge d'URLs marquées « Crawlée, actuellement non indexée » — un statut qui illustre exactement ce que dit Illyes.
La nuance : Google ne dit pas combien coûte ce stockage, ni quel pourcentage du web est effectivement indexé. [À vérifier] On manque de chiffres officiels sur le ratio crawl/indexation réel. Les estimations externes varient énormément.
Dans quels cas cette règle ne s'applique-t-elle pas vraiment ?
Les sites d'autorité forte — médias nationaux, marques établies, sites gouvernementaux — bénéficient d'une tolérance bien supérieure. Leurs pages sont indexées massivement, même celles à faible potentiel de trafic.
Pour les petits sites ou les nouveaux entrants, c'est une autre histoire. Chaque page doit justifier son existence dans l'index. Soyons honnêtes : Google n'applique pas les mêmes règles de sélectivité à tout le monde.
Que faire des contenus qui méritent d'être indexés mais ne le sont pas ?
C'est là que ça coince. Si votre contenu est objectivement utile mais ignoré par Google, vous devez lui créer des signaux artificiels de désirabilité : liens internes stratégiques, mentions externes, trafic direct, engagement social. Tout ce qui prouve qu'il existe une demande.
Impact pratique et recommandations
Que faut-il faire concrètement pour maximiser ses chances d'indexation ?
D'abord, prioriser impitoyablement. Si vous avez 10 000 pages et que Google n'en indexe que 3 000, c'est peut-être que 7 000 ne méritent effectivement pas d'être indexées. Auditez votre contenu et supprimez ou consolidez ce qui n'apporte rien.
Ensuite, concentrez vos efforts sur les pages à fort potentiel : maillage interne dense vers elles, mentions externes, actualisation régulière, signaux d'engagement. Google doit comprendre que ces pages sont activement recherchées ou consultées.
Quelles erreurs éviter absolument ?
Arrêtez de croire qu'un sitemap XML garantit l'indexation. Arrêtez de produire du contenu en masse sans stratégie de distribution. Et surtout, arrêtez de penser que Google a une obligation morale d'indexer votre site.
Le piège classique : générer automatiquement des milliers de pages produit ou catégories fines, puis s'étonner qu'elles ne s'indexent pas. Google voit ça comme du bruit sans valeur ajoutée.
Comment vérifier que votre stratégie fonctionne ?
Surveillez le ratio entre URLs crawlées et URLs indexées dans Google Search Console. Si l'écart se creuse, c'est que Google juge votre contenu non prioritaire. Comparez également l'évolution mensuelle : un site sain voit son taux d'indexation stable ou croissant.
- Auditez régulièrement les pages « Crawlée, actuellement non indexée » et décidez : améliorer, fusionner ou supprimer
- Renforcez le maillage interne vers les pages stratégiques que Google ignore
- Supprimez les contenus faibles ou redondants qui diluent votre crawl budget
- Créez des signaux de demande utilisateur (trafic direct, liens externes, partages)
- Privilégiez la qualité et la spécificité plutôt que le volume de pages
- Surveillez mensuellement l'évolution du taux d'indexation dans GSC
❓ Questions frequentes
Google indexe-t-il vraiment moins de pages qu'avant à cause de ces contraintes ?
Si ma page est crawlée mais non indexée, est-ce définitif ?
Le coût de stockage explique-t-il la dépriorisation des sites de niche ?
Faut-il bloquer le crawl des pages qu'on ne veut pas indexer pour économiser le crawl budget ?
Cette logique s'applique-t-elle aussi aux images, vidéos et PDFs ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.