Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Pourquoi Google multiplie-t-il les fonctionnalités enrichies au détriment des liens bleus classiques ?
- □ Google retire-t-il des fonctionnalités de recherche uniquement en fonction des clics ?
- □ Faut-il vraiment optimiser les éléments invisibles ou peu cliqués sur une page ?
- □ Google cherche-t-il vraiment à satisfaire l'utilisateur ou à maximiser ses revenus publicitaires ?
- □ Google mesure-t-il la satisfaction de vos pages via les recherches répétées ?
- □ Comment Google choisit-il les fonctionnalités à prioriser dans son algorithme ?
- □ Google peut-il continuer d'exiger toujours plus de travail aux propriétaires de sites ?
- □ Faut-il se réjouir quand Google retire des fonctionnalités SEO ?
- □ Comment Google déploie-t-il réellement ses changements d'algorithme ?
- □ Google est-il obligé d'annoncer publiquement le retrait de toutes ses fonctionnalités SEO ?
- □ Google limite-t-il vraiment ses résultats à un seul par domaine ?
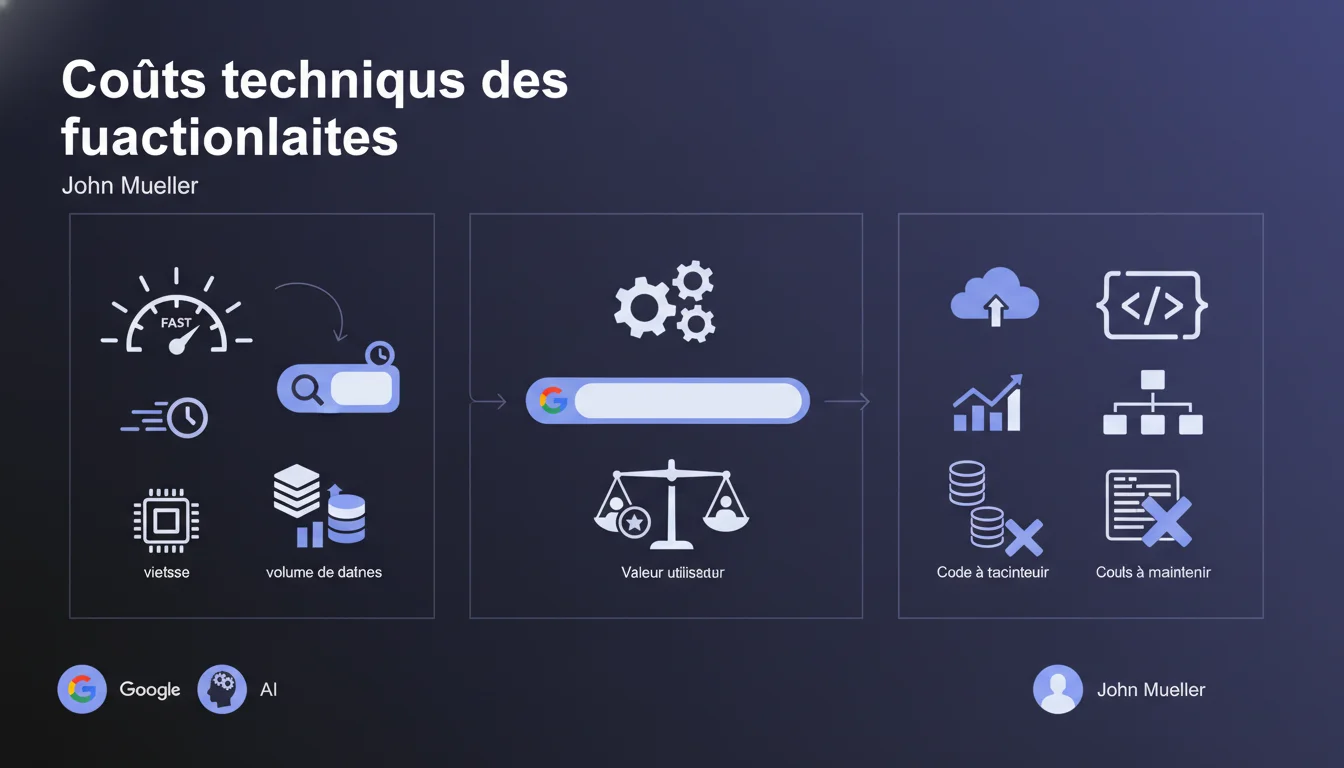
Google ne déploie pas toutes les fonctionnalités techniquement possibles : chaque feature est évaluée selon son coût infrastructure (vitesse, stockage, maintenance du code). Autrement dit, une fonctionnalité peut être théoriquement bénéfique pour l'utilisateur mais rejetée si elle pèse trop lourd sur les systèmes de Google. Pour les SEO, cela explique pourquoi certaines demandes récurrentes (crawl plus fréquent, indexation instantanée, etc.) restent lettres mortes.
Ce qu'il faut comprendre
Pourquoi Google refuse-t-il certaines améliorations pourtant utiles ?
La déclaration de Mueller rappelle une réalité souvent ignorée : Google est une entreprise avec des contraintes d'infrastructure. Chaque feature représente un arbitrage entre valeur utilisateur et coût opérationnel.
Concrètement, trois critères décisifs : vitesse de génération des résultats (latence acceptable pour l'utilisateur), volume de données à stocker (serveurs, réplication, backups), et quantité de code à maintenir (dette technique, bugs potentiels, équipes mobilisées).
Qu'est-ce que cela change pour l'indexation et le crawl ?
Cette logique explique pourquoi Google limite le crawl budget sur les sites peu performants ou redondants, pourquoi certaines pages ne sont jamais indexées malgré leur soumission, ou pourquoi des fonctionnalités comme l'indexation instantanée ont été supprimées.
Si stocker ou analyser une page coûte plus cher que la valeur qu'elle apporte aux utilisateurs, Google la déprioritise ou l'ignore. C'est brutal, mais cohérent avec leur modèle économique.
Comment cette contrainte influence-t-elle les algorithmes de ranking ?
Certains signaux SEO — pourtant pertinents — ne sont pas exploités parce qu'ils nécessitent trop de calculs en temps réel. Par exemple, une analyse sémantique profonde de chaque requête longue traîne pourrait améliorer les résultats, mais si elle ralentit la SERP de 200 ms, elle sera abandonnée.
Google privilégie les signaux peu coûteux à calculer et à maintenir : backlinks (structure de graphe statique), popularité de domaine (métriques agrégées), Core Web Vitals (données déjà collectées via Chrome). Les signaux complexes, même performants, passent à la trappe si l'équation coût/bénéfice penche du mauvais côté.
- Valeur utilisateur vs coût infrastructure : chaque feature est un compromis économique, pas seulement technique
- Crawl budget limité : Google ne crawle pas tout parce que ça coûte cher, pas par caprice
- Signaux de ranking : les algorithmes favorisent les métriques peu gourmandes en calcul et stockage
- Suppressions de fonctionnalités : quand le coût dépasse la valeur, Google coupe (exemple : indexation instantanée)
- Dette technique : plus de code = plus de bugs, plus d'équipes, donc réticence à multiplier les features
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Absolument. On voit depuis des années Google réduire la voilure sur des outils ou fonctionnalités jugés trop coûteux. La suppression de l'API d'indexation instantanée pour les sites non-actualités, la réduction drastique du crawl sur les sites avec du duplicate content massif, le refus d'indexer certaines catégories de pages (filtres, facettes mal gérées) — tout ça s'explique par cette logique comptable.
Les SEO ont tendance à penser que si une feature est techniquement possible, Google devrait l'implémenter. Sauf que Google est une boîte qui doit rentabiliser son infrastructure. Si un webmaster veut être crawlé plus souvent, il doit d'abord prouver que son site mérite ce coût supplémentaire — via du contenu unique, une fraîcheur régulière, une popularité établie.
Quelles nuances faut-il apporter à cette vision purement économique ?
Attention à ne pas tout réduire au ROI infrastructure. Google a aussi des contraintes politiques, juridiques, et de réputation. Certaines fonctionnalités ne sont pas déployées parce qu'elles poseraient des problèmes de vie privée (collecte excessive de données), d'autres parce qu'elles ouvriraient la porte à la manipulation (indexation instantanée = spam massif).
Le coût technique est un filtre parmi d'autres, pas le seul. Mais c'est un filtre puissant et souvent sous-estimé par les SEO qui raisonnent uniquement côté « pertinence » ou « expérience utilisateur ».
Dans quels cas cette règle ne s'applique-t-elle pas ou est-elle contournée ?
Google fait parfois des exceptions pour des secteurs stratégiques. Les sites d'actualité bénéficient d'un crawl ultra-rapide et d'une indexation quasi-instantanée — non pas parce que c'est gratuit, mais parce que Google a intérêt à être compétitif sur l'actu face à Twitter, TikTok, etc.
De même, les gros sites e-commerce (Amazon, eBay) sont crawlés massivement malgré leurs millions de pages redondantes. Pourquoi ? Parce que leur trafic organique génère des clics publicitaires via Google Ads, donc le coût du crawl est compensé ailleurs dans l'écosystème. [À vérifier] : cette hypothèse n'est jamais confirmée officiellement, mais elle colle avec les observations terrain.
Impact pratique et recommandations
Que faut-il faire concrètement pour minimiser le coût de son site aux yeux de Google ?
Réduire le bruit : moins de pages inutiles = moins de crawl gaspillé, donc crawl budget mieux alloué. Chaque page indexée doit avoir une valeur utilisateur claire et une différenciation suffisante. Les filtres e-commerce qui génèrent 10 000 URLs quasi-identiques ? Noindex ou canonical agressif.
Techniquement, cela implique un travail d'architecture SEO rigoureux : robots.txt pour bloquer les répertoires inutiles, balises canonical pour unifier les variantes, sitemap XML propre (sans URLs bloquées ou en noindex), temps de réponse serveur optimisé pour ne pas ralentir le crawl.
Quelles erreurs éviter pour ne pas surcharger l'infrastructure de Google inutilement ?
Ne multipliez pas les facettes de navigation sans contrôle. Chaque nouveau paramètre d'URL (tri, filtre, pagination) multiplie le nombre de combinaisons crawlables. Si Google détecte que 90 % de ces pages apportent zéro valeur, il va throttler votre crawl budget — et vos vraies pages stratégiques seront pénalisées.
Autre piège classique : les redirections en cascade (A → B → C) ou les chaînes de canonical. Chaque saut coûte une requête HTTP supplémentaire, ralentit le crawl, consomme du temps serveur. Google finit par abandonner ou déprioriser.
Comment vérifier que mon site est aligné avec cette logique de coût technique ?
Analysez vos logs serveur pour identifier les URLs crawlées mais non stratégiques. Si Googlebot passe 60 % de son temps sur des pages en noindex, des PDF orphelins ou des URLs de session, vous avez un problème d'efficacité du crawl.
Utilisez la Search Console pour repérer les pages « Découvertes, actuellement non indexées » : souvent, ce sont des pages que Google juge trop coûteuses ou inutiles à indexer. Si elles sont stratégiques, améliorez leur contenu, leur maillage interne, leur vitesse. Si elles sont accessoires, bloquez-les proprement.
- Auditez votre architecture : combien de pages réellement uniques vs combien d'URLs crawlables ?
- Nettoyez les facettes e-commerce : noindex sur les combinaisons de filtres non stratégiques
- Supprimez les redirections en cascade et les chaînes de canonical
- Optimisez le temps de réponse serveur (TTFB) pour accélérer le crawl
- Analysez les logs : identifiez le gaspillage de crawl budget sur des URLs inutiles
- Vérifiez la Search Console : pages découvertes non indexées = signal de faible valeur perçue
- Priorisez le maillage interne vers vos pages stratégiques pour orienter le crawl
❓ Questions frequentes
Google refuse-t-il d'indexer des pages uniquement pour des raisons de coût ?
Pourquoi Google a-t-il supprimé l'API d'indexation instantanée pour les sites non-actualités ?
Comment savoir si mon site coûte trop cher à Google en termes de crawl ?
Est-ce que réduire le nombre de pages améliore forcément mon SEO ?
Google privilégie-t-il certains sites malgré leur coût technique élevé ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/11/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.