Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Faut-il vraiment se préoccuper du crawl budget pour votre site ?
- □ Le crawl budget est-il un concept inventé par Google ou par les SEO ?
- □ Google n'indexe-t-il vraiment qu'une fraction du web à cause de ses coûts de stockage ?
- □ Les requêtes POST plombent-elles vraiment votre crawl budget ?
- □ Le crawl budget d'une nouvelle section est-il hérité de la qualité du site principal ?
- □ Les codes 503 et 429 peuvent-ils vraiment réduire votre crawl budget ?
- □ Peut-on vraiment piloter son crawl budget depuis Google Search Console ?
- □ HTTP/2 améliore-t-il vraiment votre crawl budget ?
- □ Pourquoi vos URLs 'découvertes mais non crawlées' révèlent-elles un problème de fond ?
- □ Faut-il bloquer l'indexation de vos fichiers JavaScript pour optimiser le crawl budget ?
- □ Les 404 et robots.txt gaspillent-ils vraiment votre crawl budget ?
- □ Faut-il bloquer vos fichiers JavaScript décoratifs pour optimiser votre crawl budget ?
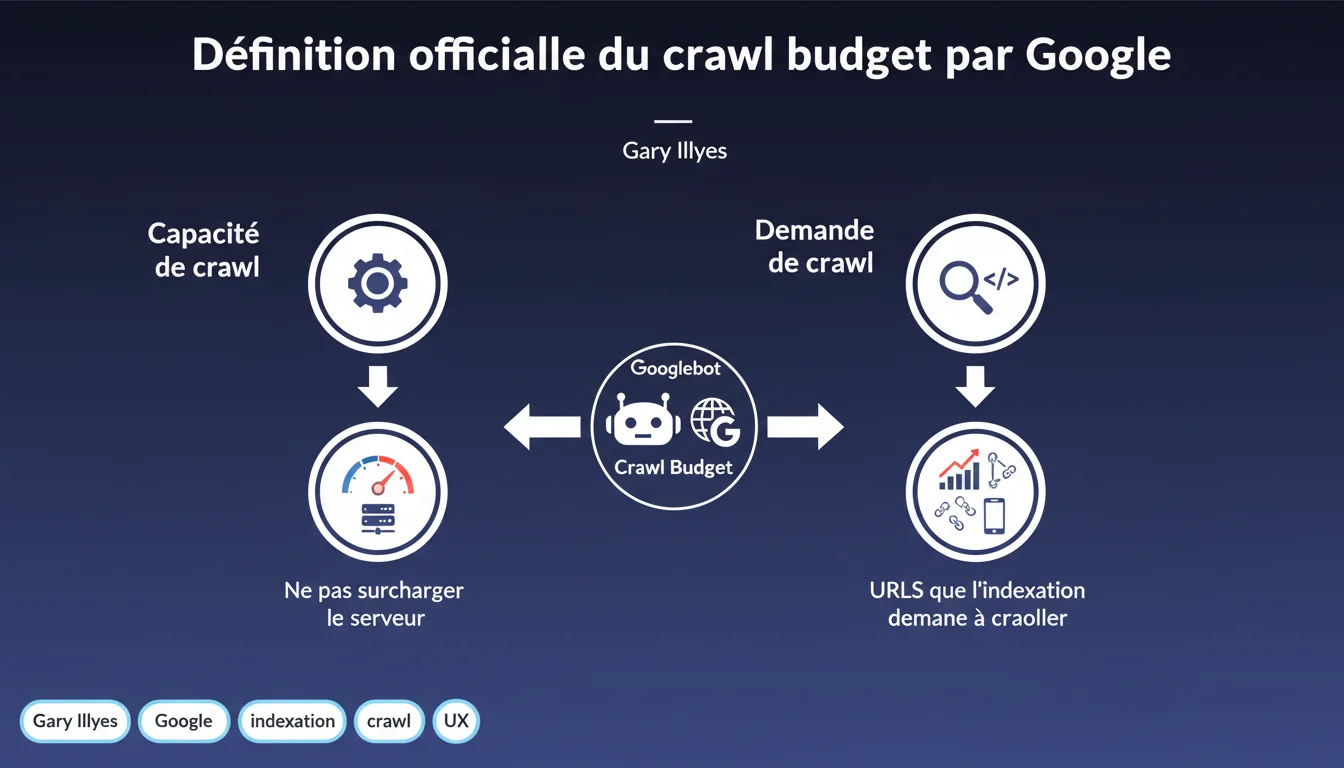
Google décompose le crawl budget en deux piliers : la capacité de crawl (ne pas saturer le serveur) et la demande de crawl (URLs que l'index veut réellement explorer). Gary Illyes officialise une mécanique qu'on soupçonnait, mais qui restait floue. Pour optimiser son crawl budget, il faut donc jouer sur ces deux tableaux : performances serveur ET pertinence des URLs proposées.
Ce qu'il faut comprendre
Pourquoi Google officialise-t-il maintenant cette définition ?
Pendant des années, le crawl budget est resté un concept nébuleux, utilisé à toutes les sauces par les SEO sans vraiment de cadre clair. Gary Illyes met fin à l'ambiguïté en découpant le problème en deux axes distincts : capacité de crawl et demande de crawl.
Cette distinction n'est pas anodine. Elle signifie qu'optimiser le crawl budget ne se résume pas à alléger son serveur ou à nettoyer ses URLs zombies — il faut agir simultanément sur ces deux fronts.
Qu'est-ce que la capacité de crawl concrètement ?
La capacité de crawl, c'est la quantité d'URLs que Googlebot peut explorer sans mettre ton serveur à genoux. Google ne veut pas que son bot devienne un problème pour tes utilisateurs.
Si ton serveur rame, Googlebot lève le pied. Si ton temps de réponse explose, il réduit la fréquence de passage. C'est un mécanisme de protection — pas de générosité de leur part.
Et la demande de crawl, qu'est-ce qui la détermine ?
La demande de crawl, c'est l'appétit de Google pour tes contenus. Plus précisément, c'est l'indexation qui décide quelles URLs méritent d'être crawlées, et à quelle fréquence.
Si tes pages sont jugées peu utiles, dupliquées ou de faible qualité, la demande s'effondre. Si ton contenu est frais, populaire, et que tes URLs changent régulièrement, Googlebot reviendra plus souvent.
- Capacité de crawl : déterminée par les performances serveur et la réactivité du site.
- Demande de crawl : pilotée par la qualité perçue des contenus et leur fréquence de mise à jour.
- Le crawl budget réel = le minimum entre ces deux facteurs. Un serveur ultra-rapide ne compense pas un contenu médiocre.
- Google ajuste automatiquement le crawl budget — on ne peut pas le "forcer", seulement l'optimiser.
Avis d'un expert SEO
Cette définition est-elle vraiment nouvelle ou Google reformule-t-il l'évidence ?
Soyons honnêtes : les SEO expérimentés savaient déjà que le crawl budget dépendait de la santé serveur et de l'intérêt des contenus. Ce qui change, c'est que Google officialise une nomenclature — et ça, c'est utile pour éviter les malentendus.
Cependant, la déclaration reste volontairement floue sur les seuils réels. Combien d'URLs par jour pour un site moyen ? Quel impact précis d'un temps de réponse qui passe de 200ms à 500ms ? [A vérifier] — Google ne donne aucun chiffre exploitable.
Dans quels cas cette règle ne s'applique-t-elle pas vraiment ?
Pour les petits sites (moins de quelques milliers de pages), le crawl budget n'est tout simplement pas un problème. Google crawlera l'ensemble du site régulièrement, sauf si le contenu est catastrophique.
Le sujet devient critique sur les gros sites (e-commerce, médias, annuaires) où des millions d'URLs se disputent l'attention de Googlebot. Là, chaque URL gaspillée (facettes, paginations mal gérées, doublons) grignote directement le budget des pages importantes.
Quelle est la limite de cette approche bipolaire ?
Google présente capacité et demande comme deux variables indépendantes, mais sur le terrain, elles s'influencent mutuellement. Un serveur lent dégrade l'expérience utilisateur, ce qui fait baisser les signaux d'engagement, ce qui réduit… la demande de crawl.
Autrement dit, négliger les performances serveur ne tue pas seulement la capacité — ça affaiblit aussi la demande. L'inverse est vrai : un contenu excellent qui charge en 5 secondes gaspille son potentiel.
Impact pratique et recommandations
Que faut-il faire concrètement pour maximiser son crawl budget ?
Première étape : auditer les performances serveur. Vérifie les temps de réponse dans la Search Console (section "Statistiques d'exploration"). Si Googlebot passe moins de temps sur ton site qu'avant, ou si le temps de téléchargement augmente, c'est un signal d'alerte.
Deuxième axe : éliminer les URLs inutiles. Facettes sans valeur ajoutée, pages de tags vides, sessions ID dans les paramètres — chaque URL crawlée pour rien, c'est une URL stratégique qui attend son tour.
Quelles erreurs éviter absolument ?
Erreur classique : croire qu'un sitemap XML massif va "forcer" Google à tout crawler. Faux. Un sitemap bourré de pages low-quality réduit la confiance de Google dans tes signaux — effet inverse garanti.
Autre piège : bloquer des sections entières via robots.txt en pensant "économiser" du crawl budget. Si ces URLs sont déjà crawlées ailleurs (liens internes, backlinks), Googlebot viendra quand même vérifier — et perdra du temps à se faire refouler. Mieux vaut un noindex propre.
Comment vérifier que mon site est bien optimisé sur ces deux axes ?
Côté capacité : installe un monitoring serveur (temps de réponse médian, taux d'erreurs 5xx). Compare avec les données de crawl dans la Search Console. Si Google ralentit alors que ton serveur tient la charge, le problème est ailleurs.
Côté demande : analyse quelles sections Googlebot crawle le plus. Si c'est du contenu secondaire ou périmé, ton architecture de liens internes envoie les mauvais signaux. Rééquilibre le maillage vers les pages stratégiques.
- Auditer les temps de réponse serveur et corriger les pages > 500ms
- Nettoyer les URLs inutiles (facettes, doublons, paramètres de session)
- Optimiser le sitemap XML : uniquement les pages indexables et à jour
- Revoir le maillage interne pour pousser les contenus stratégiques
- Monitorer l'évolution du crawl budget dans la Search Console (nombre de pages crawlées/jour)
- Éviter les chaînes de redirections et les boucles 301
❓ Questions frequentes
Le crawl budget impacte-t-il tous les sites de la même manière ?
Un sitemap XML bien rempli augmente-t-il automatiquement le crawl budget ?
Peut-on forcer Google à crawler davantage en améliorant uniquement les performances serveur ?
Bloquer des sections entières via robots.txt économise-t-il du crawl budget ?
Comment savoir si mon crawl budget est suffisant ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.