Official statement
Other statements from this video 18 ▾
- □ Peut-on vraiment montrer du contenu payant structuré uniquement à Googlebot sans risque de pénalité ?
- □ Le DMCA s'applique-t-il vraiment page par page ou peut-on signaler un site entier ?
- □ Google indexe-t-il vraiment tout le contenu que vous publiez ?
- □ Une page AMP invalide peut-elle quand même être indexée par Google ?
- □ Safe Search peut-il empêcher votre site adulte de ranker sur votre propre marque ?
- □ Le Product Reviews Update peut-il impacter votre site même s'il n'est pas en anglais ?
- □ Géociblage ou hreflang : quelle méthode privilégier pour les contenus multilingues ?
- □ Google peut-il choisir arbitrairement quelle version linguistique indexer quand le contenu est identique ?
- □ Faut-il vraiment bloquer les URLs publicitaires dans robots.txt ?
- □ Faut-il abandonner l'injection dynamique de mots-clés pour éviter les pénalités Google ?
- □ Le client-side rendering React pose-t-il vraiment un problème de classement pour Google ?
- □ Les sites SEO sont-ils vraiment exemptés des critères YMYL ?
- □ Google pénalise-t-il les breadcrumbs structurés invisibles ou trompeurs ?
- □ Peut-on vraiment lier plusieurs sites dans le footer sans risque SEO ?
- □ Faut-il vraiment traduire l'intégralité d'un site multilingue pour bien se positionner ?
- □ Faut-il vraiment s'inquiéter du crawl budget sur un site de moins de 10 000 URLs ?
- □ Robots.txt ou noindex : lequel choisir pour bloquer l'indexation ?
- □ Le trafic artificiel influence-t-il vraiment le classement Google ?
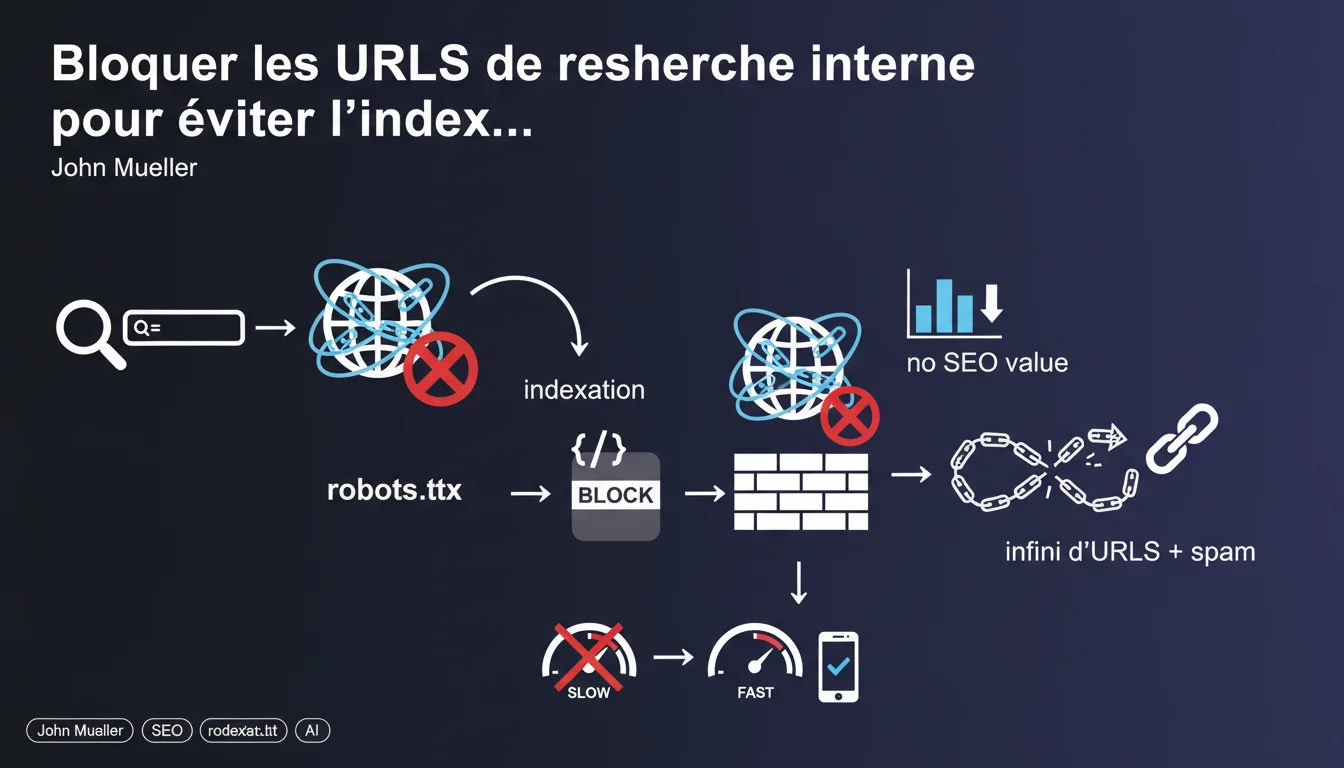
Google recommends systematically blocking internal search URLs via robots.txt to avoid indexing an infinite space of low-value pages for SEO. This directive aims to protect crawl budget and prevent query spam. However, this binary approach deserves to be nuanced depending on use cases.
What you need to understand
Why does Google consider internal search URLs problematic? <\/h3>
Internal search engines generate parameterized URLs that can create an almost infinite number of combinations. Each user query produces a new URL, often with GET parameters (e.g., ?q=shoes&filter=red&sort=price<\/code>).
For Google, these pages pose two major problems: they dilute the crawl budget by forcing Googlebot to explore thousands of variants with no unique value, and they open the door to query injection spam in the URL parameters.
What does this "infinite space of URLs" mentioned by Mueller refer to? <\/h3>
In concrete terms: if your site allows site.com\/search?q=X<\/code>, a malicious bot or even a scraper can generate millions of URLs by testing all possible combinations of keywords. Googlebot follows these links, crawls them, and attempts to evaluate them.
As a result: your server is overwhelmed with requests, your crawl budget is exhausted on duplicate or empty content, and Google potentially indexes "No results found" pages that pollute your SERPs. It’s a technical and SEO nightmare.
What is Google's official recommendation on this point? <\/h3>
John Mueller is emphatic: block these URLs in robots.txt. No noindex, no canonical — a simple blocking so that Googlebot does not even discover them.
The argument: these pages provide no SEO value as they only reflect one-off user queries, lacking stable editorial content or coherent external search intent.
- Internal search URLs create an infinite space of variations with no added value
- They unnecessarily consume crawl budget and slow down the indexing of actual strategic pages
- They expose the site to spam by injecting malicious parameters into URLs
- Google recommends a robots.txt block rather than noindex to prevent even discovery
SEO Expert opinion
Is this directive truly universal, or are there legitimate exceptions? <\/h3>
Let's be honest: Mueller's position is valid for 90% of sites, but it overlooks certain specific use cases. On large e-commerce sites or marketplaces, some filter combinations represent real search intentions with Google volume.
For example: "women's running shoes Nike size 38" may correspond to a genuine long-tail query. If you systematically block all facet URLs, you may potentially miss qualified traffic. Amazon, Cdiscount, or Leboncoin massively index these pages — and it works.
[To verify]: Google states "no SEO value," but field data shows that well-optimized internal search pages can rank and convert, especially for ultra-specific queries that your standard categories do not cover.
Is the robots.txt blocking really the best technical solution? <\/h3>
Blocking in robots.txt prevents discovery, indeed — but if an external link points to one of these URLs (backlink, social share), Google will see it in its logs and treat it as a blocked page with unknown authority. This is rarely optimal.
In reality, a noindex + canonical tag pointing to the parent page offers greater flexibility: it allows Google to understand the relationship between the pages while avoiding indexing. For complex sites, managing URL parameters via Search Console (though deprecated) or dynamic rel="canonical"<\/code> remains more targeted.
What about sites where internal search generates aggregated unique content? <\/h3>
Some sites display on internal search results pages contextual editorial content, buying guides, or relevant aggregations. In this case, these pages are no longer mere mirrors of queries — they become full-fledged landing pages.
In that case, blocking would be counterproductive. But this assumes a genuine editorial strategy behind each search template, not just a generic product listing. The nuance is essential: Mueller speaks of "default pages," not cases where you're investing in differentiated content.
Practical impact and recommendations
What should you do if you are currently indexing your internal search pages? <\/h3>
The first step: audit in Search Console. Filter your indexed URLs by parameter (?q=<\/code>, ?search=<\/code>, ?s=<\/code>) and assess the volume. If you have thousands of such pages with zero impressions, it's a clear signal that they are wasting crawl budget.
Next, decide on the treatment: block robots.txt if no identifiable SEO value, or noindex + canonical if some variants deserve to be preserved for UX but not indexed. Never mix the two approaches on the same URL pattern.
How to implement robots.txt blocking without breaking the existing setup? <\/h3>
Add a targeted directive in your robots.txt<\/code> like Disallow: \/search?<\/code> or Disallow: \/*?q=<\/code> depending on your structure. First, test with the Search Console robots.txt testing tool to avoid accidentally blocking strategic URLs.
If internal search pages are already indexed, Google will eventually remove them naturally<\/strong> after a few crawls — but this can take weeks. To speed up, submit a removal request via Search Console, then wait for the index to clean up before measuring the impact on crawl budget.
What critical mistakes should you avoid during this migration? <\/h3>
Never block in robots.txt a URL that you have put in noindex — it’s contradictory, and Google cannot read the meta tag. As a result: the page remains in the index with the note "Blocked by robots.txt".
Also avoid blocking too broadly: Disallow: \/*?<\/code> will kill all your URLs with parameters, including session IDs, UTM tracking parameters, or legitimate pagination variants. Be surgical in your patterns.
- Audit the current index to identify already indexed internal search URLs
- Choose between blocking robots.txt (if no value) or noindex + canonical (if fine-tuned control is needed)
- Test the robots.txt directives before deployment with the Search Console tool
- Manually delete indexed URLs via Search Console to accelerate cleanup
- Never combine robots.txt + noindex on the same pattern
- Monitor crawl budget and indexing rate in the weeks following the migration
❓ Frequently Asked Questions
Puis-je utiliser noindex au lieu de robots.txt pour bloquer les pages de recherche interne ?
Si je bloque mes URLs de recherche interne, est-ce que je perds le trafic des utilisateurs qui cliquent dessus depuis Google ?
Les filtres produit sur un site e-commerce sont-ils considérés comme de la recherche interne ?
Combien de temps faut-il pour que Google désindexe les pages de recherche interne après blocage robots.txt ?
Le blocage des URLs de recherche interne améliore-t-il vraiment le crawl budget ?
🎥 From the same video 18
Other SEO insights extracted from this same Google Search Central video · published on 24/12/2021
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.