Official statement
Other statements from this video 18 ▾
- □ Peut-on vraiment montrer du contenu payant structuré uniquement à Googlebot sans risque de pénalité ?
- □ Le DMCA s'applique-t-il vraiment page par page ou peut-on signaler un site entier ?
- □ Google indexe-t-il vraiment tout le contenu que vous publiez ?
- □ Une page AMP invalide peut-elle quand même être indexée par Google ?
- □ Safe Search peut-il empêcher votre site adulte de ranker sur votre propre marque ?
- □ Le Product Reviews Update peut-il impacter votre site même s'il n'est pas en anglais ?
- □ Géociblage ou hreflang : quelle méthode privilégier pour les contenus multilingues ?
- □ Google peut-il choisir arbitrairement quelle version linguistique indexer quand le contenu est identique ?
- □ Faut-il vraiment bloquer les URLs publicitaires dans robots.txt ?
- □ Faut-il abandonner l'injection dynamique de mots-clés pour éviter les pénalités Google ?
- □ Faut-il vraiment bloquer toutes les URLs de recherche interne dans robots.txt ?
- □ Les sites SEO sont-ils vraiment exemptés des critères YMYL ?
- □ Google pénalise-t-il les breadcrumbs structurés invisibles ou trompeurs ?
- □ Peut-on vraiment lier plusieurs sites dans le footer sans risque SEO ?
- □ Faut-il vraiment traduire l'intégralité d'un site multilingue pour bien se positionner ?
- □ Faut-il vraiment s'inquiéter du crawl budget sur un site de moins de 10 000 URLs ?
- □ Robots.txt ou noindex : lequel choisir pour bloquer l'indexation ?
- □ Le trafic artificiel influence-t-il vraiment le classement Google ?
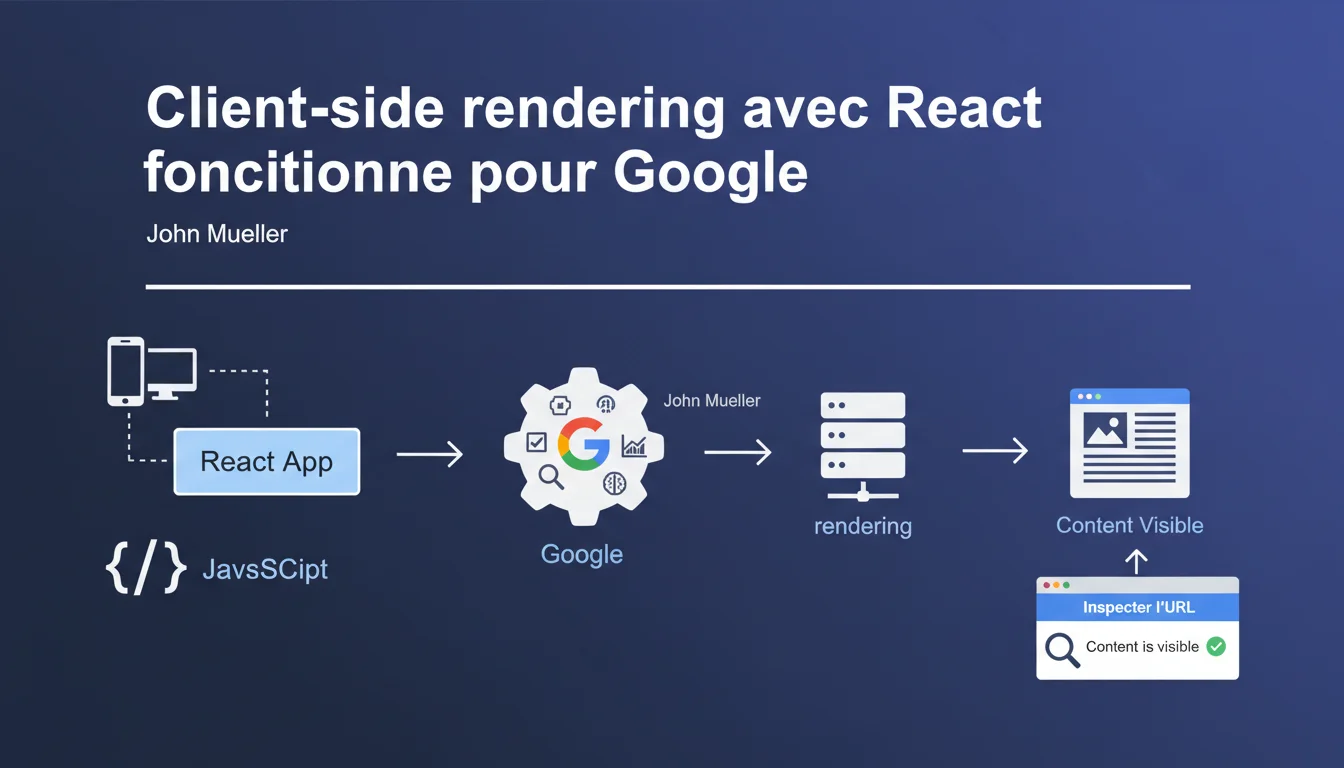
Google states that a React site using client-side rendering does not penalize rankings, even if the initial HTML page is empty. The engine runs the JavaScript and indexes the rendered content. This can be verified using the URL Inspect tool in the Search Console.
What you need to understand
Does Google really index client-side generated content? <\/h3>
The official answer from John Mueller<\/strong> is clear: yes. Google's crawl includes a phase of JavaScript rendering<\/strong> that allows extracting the content displayed by React, even if the initial HTML only contains an empty div and script tags.<\/p> This statement aligns with Google's messages over the years. The engine has a Chrome rendering engine<\/strong> (Chromium) that executes the JavaScript before indexing. In theory, a site fully built on CSR should not be disadvantaged.<\/p> Because the ground reality does not always match official statements. Many experts observe longer indexing delays<\/strong>, issues with the discoverability of internal links, or partially indexed content on pure CSR sites.<\/p> The gap between theory and practice fuels legitimate skepticism. Google says it works, but problematic documented cases are not lacking. Hence the importance of consistently checking with the inspection tool, as Mueller suggests.<\/p> This wording leaves a comfortable margin for interpretation<\/strong>. "Should not" is not the same as "never does." It implies that under normal conditions, with a properly configured site, Google manages CSR.<\/p> But "normal conditions" remains vague. What about sites with a limited crawl budget<\/strong>? JavaScript errors? Server timeouts? Resources blocked by robots.txt? All these factors can compromise rendering on Google’s part, even if technically the engine is capable of executing it.<\/p>Why does this question keep coming up in the SEO community? <\/h3>
What does "should not pose a problem" actually mean? <\/h3>
SEO Expert opinion
Does this statement align with real-world observations? <\/h3>
Partially. Yes, Google indexes CSR content — this is verified daily on thousands of React sites in production. But no, it does not always work as well as Server-Side Rendering<\/strong> or Static Site Generation<\/strong>.<\/p> Sites with a tight crawl budget<\/strong> (new domains, low authority, few backlinks) suffer more. JavaScript rendering consumes additional resources on the Googlebot side, which can slow the indexing of new pages or updates. [To be verified]<\/strong>: Google has never published numerical data on the actual impact of CSR on crawl budgets.<\/p> Let’s be honest: "it works" does not mean "it’s optimal." CSR introduces additional latency<\/strong> into the indexing process. Googlebot must first download the HTML, then the scripts, then execute them, and then wait for the DOM to stabilize. All this takes time.<\/p> Another rarely discussed point: links discovered post-render<\/strong>. If your navigation is entirely JavaScript-generated, Googlebot must execute the code to discover the URLs. No technical problem, but an additional delay compared to links present in the initial HTML.<\/p> And what happens in case of a JavaScript error<\/strong>? An unhandled exception, a dependency failing to load, a timeout — and the content becomes invisible. With SSR, the base HTML remains accessible even if the JS fails on the client side.<\/p> When the crawl budget is critical<\/strong>. E-commerce sites with tens of thousands of regularly updated product pages, news sites with frequent publications, UGC platforms with continuously generated content — all these scenarios benefit more from SSR to ensure quick indexing.<\/p> Sites heavily dependent on social sharing<\/strong> are also affected. Facebook, Twitter, LinkedIn use their crawlers that do not execute (or poorly execute) JavaScript. The result: your client-side generated Open Graph tags won’t be retrieved, and your posts will display empty previews.<\/p> Finally, projects with strict performance constraints<\/strong>. Pure CSR consistently generates a slower First Contentful Paint compared to a hybrid approach. If your Core Web Vitals are already borderline, adding a client-side rendering layer will only worsen the situation.<\/p>What nuances should be added to this claim? <\/h3>
In which cases does this rule not fully apply? <\/h3>
Practical impact and recommendations
What should you do if your site is on CSR React? <\/h3>
First, check<\/strong>. Use the URL Inspect tool in the Search Console on a representative sample of pages. Compare the raw HTML with the rendered version from Googlebot. If the main content appears in the rendered version, you are theoretically covered.<\/p> Next, monitor indexing metrics<\/strong>. Time between publication and indexing, coverage of pages in the index, crawl errors. If you notice unusually long delays or pages not indexed for no obvious reason, CSR could be to blame.<\/p> Consider a hybrid approach<\/strong>. Next.js, Nuxt, Gatsby allow mixing SSR/SSG and CSR depending on the pages. Critical pages for SEO (landing pages, product sheets, articles) in SSR, interactive user interface in CSR. The best of both worlds.<\/p> Never block JavaScript resources<\/strong> via robots.txt. It’s a sure way to kill your indexing. Google must be able to download and execute your JS bundles to see the content.<\/p> Don’t rely on CSR to generate your critical meta tags<\/strong>. Title, meta description, canonical, hreflang — all of these must be present in the initial HTML. React Helmet and equivalents work for Google, but not for other crawlers. Prefer server-side rendering for these elements.<\/p> Avoid JavaScript redirect chains<\/strong>. If your client-side routing makes several redirects before displaying the final content, Googlebot may give up along the way. Limit the complexity of the rendering path as much as possible.<\/p> Optimize the size of your JavaScript bundles<\/strong>. Code splitting, lazy loading, tree shaking — all these techniques reduce download and execution time. The less Googlebot waits, the better it is for your crawl budget.<\/p> Implement prerendering<\/strong> for static or infrequently updated pages. Services like Prerender.io or homemade solutions with Puppeteer generate static HTML served only to crawlers. An acceptable compromise if the transition to SSR is too costly.<\/p> Use dynamic rendering<\/strong> if you have the technical resources. User-agent detection, server-side rendering for bots, CSR for real users. Google officially allows this practice as long as the content served to bots is identical to that served to users.<\/p>What mistakes should you absolutely avoid with a CSR site? <\/h3>
How can you optimize a CSR site to maximize its chances of indexing? <\/h3>
❓ Frequently Asked Questions
Dois-je obligatoirement passer en SSR si mon site React est déjà en production en CSR ?
L'outil Inspecter l'URL suffit-il pour garantir que mon site CSR est correctement indexé ?
Le CSR pénalise-t-il les Core Web Vitals et donc indirectement le classement ?
Puis-je utiliser le dynamic rendering sans risquer une pénalité pour cloaking ?
Les frameworks comme Next.js ou Gatsby règlent-ils définitivement le problème du CSR ?
🎥 From the same video 18
Other SEO insights extracted from this same Google Search Central video · published on 24/12/2021
🎥 Watch the full video on YouTube →Related statements
Get real-time analysis of the latest Google SEO declarations
Be the first to know every time a new official Google statement drops — with full expert analysis.
💬 Comments (0)
Be the first to comment.