Official statement
Other statements from this video 18 ▾
- □ Peut-on vraiment montrer du contenu payant structuré uniquement à Googlebot sans risque de pénalité ?
- □ Le DMCA s'applique-t-il vraiment page par page ou peut-on signaler un site entier ?
- □ Google indexe-t-il vraiment tout le contenu que vous publiez ?
- □ Une page AMP invalide peut-elle quand même être indexée par Google ?
- □ Safe Search peut-il empêcher votre site adulte de ranker sur votre propre marque ?
- □ Le Product Reviews Update peut-il impacter votre site même s'il n'est pas en anglais ?
- □ Géociblage ou hreflang : quelle méthode privilégier pour les contenus multilingues ?
- □ Google peut-il choisir arbitrairement quelle version linguistique indexer quand le contenu est identique ?
- □ Faut-il vraiment bloquer les URLs publicitaires dans robots.txt ?
- □ Faut-il abandonner l'injection dynamique de mots-clés pour éviter les pénalités Google ?
- □ Le client-side rendering React pose-t-il vraiment un problème de classement pour Google ?
- □ Faut-il vraiment bloquer toutes les URLs de recherche interne dans robots.txt ?
- □ Les sites SEO sont-ils vraiment exemptés des critères YMYL ?
- □ Google pénalise-t-il les breadcrumbs structurés invisibles ou trompeurs ?
- □ Peut-on vraiment lier plusieurs sites dans le footer sans risque SEO ?
- □ Faut-il vraiment traduire l'intégralité d'un site multilingue pour bien se positionner ?
- □ Faut-il vraiment s'inquiéter du crawl budget sur un site de moins de 10 000 URLs ?
- □ Le trafic artificiel influence-t-il vraiment le classement Google ?
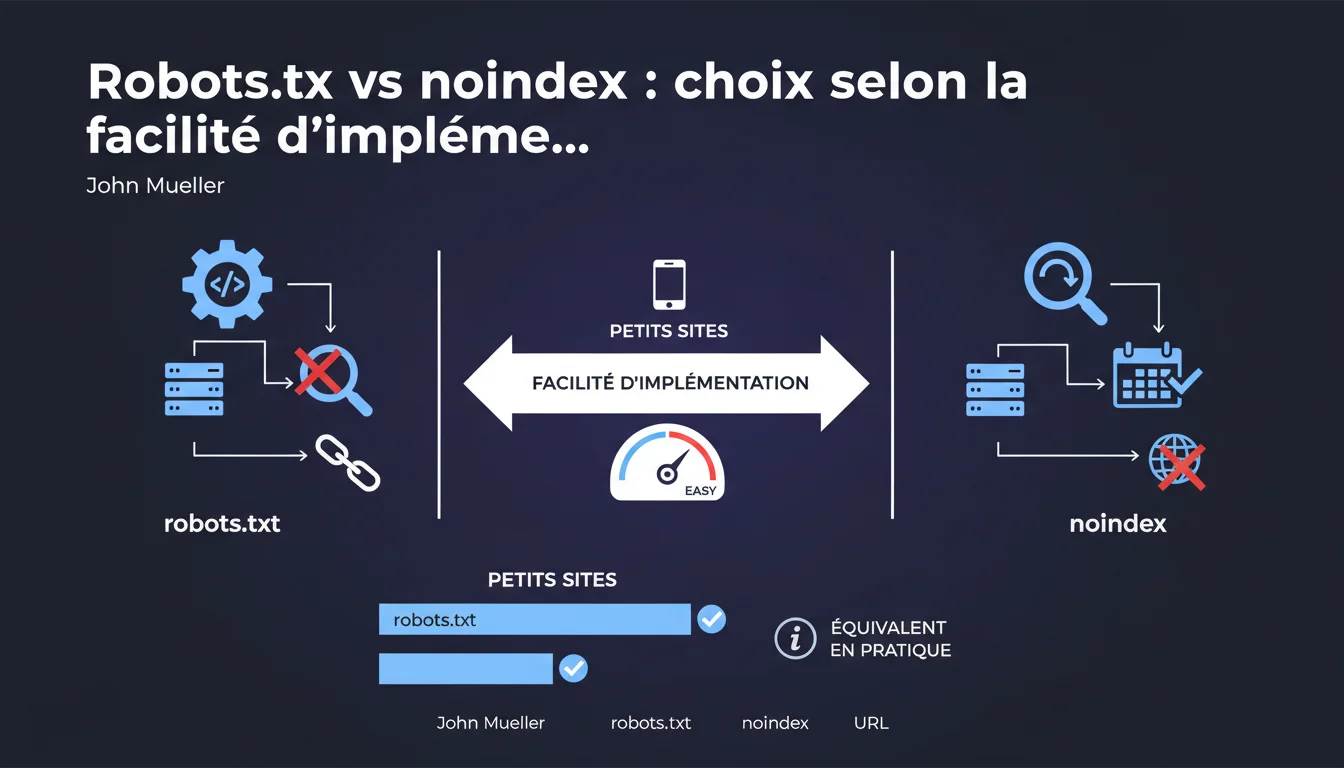
Mueller states that robots.txt and noindex are equivalent for small sites, with the choice depending on ease of implementation. Be careful: robots.txt can leave the URL indexed without content, while noindex requires periodic crawling. The decision is technical, not strategic, according to Google.
What you need to understand
Why does Google present these two methods as equivalent?
Mueller's stance is pragmatic for small sites: if the goal is simply to prevent content from appearing in search results, both methods achieve the same functional result. For a site with a few critical pages, the technical difference matters less than the ease of implementation.
This approach reflects a ground reality — Google knows that many webmasters choose the simplest solution to deploy rather than the theoretically optimal one. For a 50-page WordPress blog, installing a plugin that adds noindex or modifying robots.txt often yields the same business impact.
What are the mechanical differences between the two?
Robots.txt blocks crawling: Googlebot does not visit the URL, but if it has already been indexed or has backlinks, it can remain in the index with a generic description like "A description for this page is not available." A strange yet common result.
Noindex requires that Googlebot access the page to read the meta tag or HTTP header. If the bot comes regularly, the deindexing is clean and complete. But if crawling is rare (limited crawl budget, low authority site), deindexing can take weeks or even months.
In what cases does this equivalence not hold?
Once you step outside the "small site" framework, nuances become critical. An e-commerce site with thousands of faceted pages, media with massive archives, or an international site with complex hreflang management — in these cases, choosing robots.txt or noindex is absolutely not equivalent.
If you block URLs with quality backlinks using robots.txt, you waste PageRank. If you use noindex on entire sections accessible via internal navigation, you force Googlebot to crawl them unnecessarily. The ease of implementation does not compensate for a shaky strategy.
- Robots.txt: blocks crawling but can leave the URL in the index if it has external signals
- Noindex: requires periodic crawling to maintain deindexing
- The equivalence only holds for small sites without complex crawl budget or PageRank issues
- The technical choice should never override SEO logic if the site has a complex architecture
SEO Expert opinion
Is this pragmatic approach actually suitable for current sites?
Mueller simplifies — perhaps too much. Even on a "small site", the distinction matters if you have a link structure strategy or temporary pages (events, promotions). Saying it’s equivalent ignores cases where robots.txt masks useful signals or where noindex unnecessarily consumes crawl budget.
The argument of "ease of implementation" is valid for a small business showcase site without technical resources. But once we talk about a site that is growing, aiming for SEO traffic, this logic becomes dangerous. [To be verified]: Google has never published a quantified definition of a "small site" — 50 pages? 500? The gray area is huge.
What does this statement reveal about Google's view of technical SEO?
Google continues to push a view of "accessibility over optimization". The underlying idea: it doesn’t matter how you block indexing, as long as it works for the end user. Except for an SEO, how you block has an impact on the rest of the architecture.
Blocking using robots.txt without redirection can create dead ends in crawling. Using noindex on massive sections without cleaning the internal linking forces Google to recrawl these pages indefinitely. Technical ease often hides SEO debt that we will pay for later.
When does this recommendation become counterproductive?
Typically on e-commerce sites or those with high editorial volume. If you have 10,000 pages of filters or tags, placing noindex everywhere without managing crawl budget through robots.txt or Search Console parameters, is wasting server resources and Googlebot hits.
Conversely, blocking entire categories that receive external backlinks with robots.txt sacrifices link juice. The ease of implementation never justifies a decision that disrupts PageRank distribution or overloads crawling.
Practical impact and recommendations
Which method should you prioritize based on your technical context?
If your CMS allows you to easily add noindex meta tags (WordPress with Yoast, Shopify with dedicated apps), this is often the cleanest way. You maintain granular control, page by page, without risking blocking the crawling of URLs that need to be crawled to read other signals (redirects, canonicals).
If you must block entire directories (like /admin, /test, /dev) and are sure no URLs in these sections have external backlinks, robots.txt is faster and avoids wasting crawl. But first, check in Search Console if these URLs are not already indexed — otherwise you create zombies.
What mistakes should you absolutely avoid?
Never ever block a URL you have set to noindex using robots.txt. This is a classic mistake: you add noindex, then out of "security" you also block crawling. Result? Googlebot can no longer read the noindex, the URL remains indexed indefinitely. Google has repeated this a hundred times, yet it still happens every day.
Another trap: using noindex on pages with duplicate content instead of canonicalizing. You lose the consolidation signal. Google sees duplicates, indexes nothing, and you have no version that ranks. Noindex is not a substitute for proper duplicate management.
How to audit your current configuration?
Start by extracting all URLs blocked by robots.txt (Screaming Frog can do this). Cross-reference with the indexed URLs in Search Console (site:yourdomain.com + filters). If blocked URLs still appear in the index, you have a problem: either they have external backlinks, or they were indexed before the block.
For pages set to noindex, check the crawl frequency in the server logs. If Google only revisits certain sections every 3 months, the noindex will take just as long to take effect. In this case, robots.txt may be more effective if you don’t need to preserve signals on these pages.
- List all URLs you want to deindex and check their backlink profile
- If backlinks are present: prioritize noindex + 301 redirect to relevant content if possible
- If no backlinks and an entire directory to exclude: robots.txt is acceptable
- Never combine robots.txt and noindex on the same URL
- Regularly audit (every 3 months) blocked URLs that remain indexed
- Monitor Search Console messages regarding URLs blocked by robots.txt but with backlinks
❓ Frequently Asked Questions
Puis-je utiliser robots.txt et noindex en même temps sur une URL ?
Combien de temps faut-il pour qu'une page en noindex disparaisse de l'index ?
Si j'ai des URLs bloquées par robots.txt qui apparaissent encore dans l'index, que faire ?
Le choix entre robots.txt et noindex a-t-il un impact sur le PageRank ?
Pour un site e-commerce avec des milliers de pages filtrées, quelle méthode utiliser ?
🎥 From the same video 18
Other SEO insights extracted from this same Google Search Central video · published on 24/12/2021
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.