Declaration officielle
Autres déclarations de cette vidéo 18 ▾
- □ Peut-on vraiment montrer du contenu payant structuré uniquement à Googlebot sans risque de pénalité ?
- □ Le DMCA s'applique-t-il vraiment page par page ou peut-on signaler un site entier ?
- □ Google indexe-t-il vraiment tout le contenu que vous publiez ?
- □ Une page AMP invalide peut-elle quand même être indexée par Google ?
- □ Safe Search peut-il empêcher votre site adulte de ranker sur votre propre marque ?
- □ Le Product Reviews Update peut-il impacter votre site même s'il n'est pas en anglais ?
- □ Géociblage ou hreflang : quelle méthode privilégier pour les contenus multilingues ?
- □ Google peut-il choisir arbitrairement quelle version linguistique indexer quand le contenu est identique ?
- □ Faut-il vraiment bloquer les URLs publicitaires dans robots.txt ?
- □ Faut-il abandonner l'injection dynamique de mots-clés pour éviter les pénalités Google ?
- □ Le client-side rendering React pose-t-il vraiment un problème de classement pour Google ?
- □ Faut-il vraiment bloquer toutes les URLs de recherche interne dans robots.txt ?
- □ Les sites SEO sont-ils vraiment exemptés des critères YMYL ?
- □ Google pénalise-t-il les breadcrumbs structurés invisibles ou trompeurs ?
- □ Peut-on vraiment lier plusieurs sites dans le footer sans risque SEO ?
- □ Faut-il vraiment traduire l'intégralité d'un site multilingue pour bien se positionner ?
- □ Faut-il vraiment s'inquiéter du crawl budget sur un site de moins de 10 000 URLs ?
- □ Le trafic artificiel influence-t-il vraiment le classement Google ?
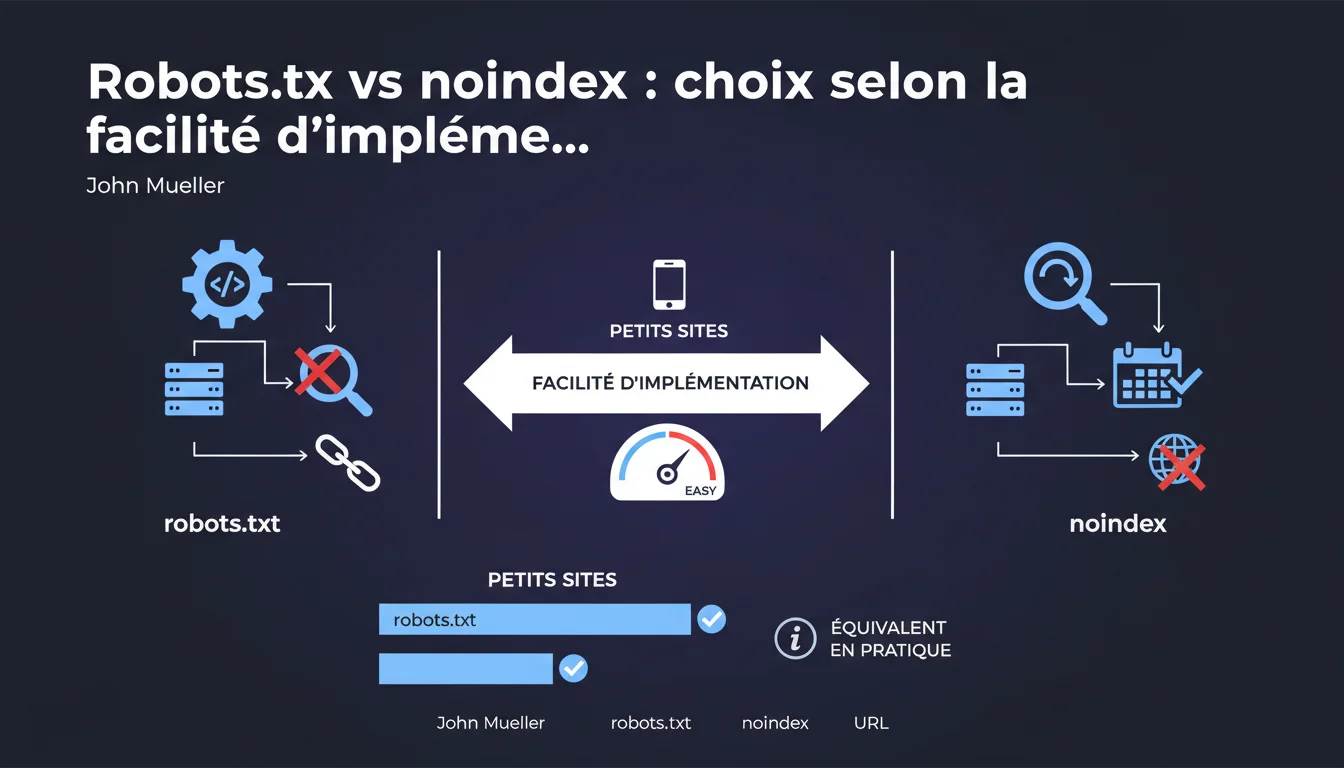
Mueller affirme que robots.txt et noindex sont équivalents pour les petits sites, le choix dépendant de la facilité d'implémentation. Attention : robots.txt peut laisser l'URL indexée sans contenu, noindex nécessite une exploration périodique. La décision est technique, pas stratégique selon Google.
Ce qu'il faut comprendre
Pourquoi Google présente-t-il ces deux méthodes comme équivalentes ?
La position de Mueller est pragmatique pour les petits sites : si l'objectif est simplement d'empêcher l'affichage de contenu dans les résultats, les deux méthodes aboutissent au même résultat fonctionnel. Pour un site avec peu de pages critiques, la différence technique importe moins que la facilité de mise en œuvre.
Cette approche reflète une réalité terrain — Google sait que beaucoup de webmasters choisissent la solution la plus simple à déployer plutôt que la théoriquement optimale. Pour un blog WordPress de 50 pages, installer un plugin qui ajoute noindex ou modifier le robots.txt revient souvent au même impact business.
Quelles sont les différences mécaniques entre les deux ?
Le robots.txt bloque l'exploration : Googlebot ne visite pas l'URL, mais si elle a déjà été indexée ou possède des backlinks, elle peut rester dans l'index avec une description générique du type "Une description pour cette page n'est pas disponible". Résultat bizarre mais fréquent.
Le noindex exige que Googlebot accède à la page pour lire la balise meta ou l'en-tête HTTP. Si le bot vient régulièrement, la désindexation est propre et complète. Mais si l'exploration est rare (budget de crawl limité, site peu autoritaire), la désindexation peut prendre des semaines voire des mois.
Dans quels cas cette équivalence ne tient-elle pas ?
Dès qu'on sort du cadre "petit site", les nuances deviennent critiques. Un site e-commerce avec des milliers de pages facettées, un média avec des archives massives, un site international avec gestion complexe du hreflang — là, choisir robots.txt ou noindex n'est absolument pas équivalent.
Si vous bloquez par robots.txt des URLs avec des backlinks de qualité, vous gaspillez du PageRank. Si vous utilisez noindex sur des sections entières accessibles via navigation interne, vous forcez Googlebot à les crawler inutilement. La facilité d'implémentation ne compense pas une stratégie bancale.
- Robots.txt : bloque le crawl mais peut laisser l'URL dans l'index si elle a des signaux externes
- Noindex : nécessite l'exploration périodique pour maintenir la désindexation
- L'équivalence ne vaut que pour les petits sites sans enjeux complexes de crawl budget ou PageRank
- Le choix technique ne doit jamais primer sur la logique SEO si le site a une architecture élaborée
Avis d'un expert SEO
Cette approche pragmatique est-elle réellement adaptée aux sites actuels ?
Mueller simplifie — peut-être trop. Même sur un "petit site", la distinction compte si vous avez une stratégie de maillage interne ou des pages temporaires (événements, promos). Dire que c'est équivalent, c'est ignorer les cas où robots.txt masque des signaux utiles ou où noindex consomme du crawl budget inutilement.
L'argument "facilité d'implémentation" est légitime pour un site vitrine de TPE sans ressources techniques. Mais dès qu'on parle d'un site qui grandit, qui a des objectifs de trafic SEO, cette logique devient dangereuse. [A vérifier] : Google n'a jamais publié de définition chiffrée de "petit site" — 50 pages ? 500 ? La zone grise est énorme.
Que révèle cette déclaration sur la vision Google du SEO technique ?
Google continue de pousser une vision "accessibility over optimization". L'idée sous-jacente : peu importe comment vous bloquez l'indexation, du moment que ça fonctionne pour l'utilisateur final. Sauf que pour un SEO, comment on bloque a un impact sur le reste de l'architecture.
Bloquer par robots.txt sans redirection peut créer des culs-de-sac dans le crawl. Utiliser noindex sur des sections massives sans nettoyer le maillage interne force Google à re-crawler ces pages indéfiniment. La facilité technique cache souvent une dette SEO qu'on paiera plus tard.
Quand cette recommandation devient-elle contre-productive ?
Typiquement sur les sites e-commerce ou à fort volume éditorial. Si vous avez 10 000 pages de filtres ou de tags, mettre du noindex partout sans gérer le crawl budget via robots.txt ou paramètres Search Console, c'est gaspiller des ressources serveur et des passages Googlebot.
Inversement, bloquer par robots.txt des catégories entières qui reçoivent des backlinks externes, c'est sacrifier du jus de lien. La facilité d'implémentation ne justifie jamais une décision qui casse la distribution du PageRank ou surcharge le crawl.
Impact pratique et recommandations
Quelle méthode privilégier selon votre contexte technique ?
Si votre CMS permet d'ajouter facilement des balises meta noindex (WordPress avec Yoast, Shopify avec app dédiée), c'est souvent la voie la plus propre. Vous gardez le contrôle granulaire, page par page, sans risquer de bloquer l'exploration d'URLs qui ont besoin d'être crawlées pour lire d'autres signaux (redirections, canoniques).
Si vous devez bloquer des répertoires entiers (type /admin, /test, /dev) et que vous êtes sûr qu'aucune URL de ces sections n'a de backlinks externes, robots.txt est plus rapide et évite de gaspiller du crawl. Mais vérifiez d'abord dans Search Console si ces URLs ne sont pas déjà indexées — sinon vous créez des zombies.
Quelles erreurs éviter absolument ?
Ne jamais bloquer par robots.txt une URL que vous avez mise en noindex. C'est une erreur classique : vous ajoutez noindex, puis par souci de "sécurité" vous bloquez aussi le crawl. Résultat ? Googlebot ne peut plus lire le noindex, l'URL reste indexée indéfiniment. Google l'a répété cent fois, ça arrive encore tous les jours.
Autre piège : utiliser noindex sur des pages avec du contenu dupliqué au lieu de canonicaliser. Vous perdez le signal de consolidation. Google voit du duplicate, n'indexe rien, et vous n'avez aucune version qui se positionne. Le noindex n'est pas un substitut à une vraie gestion des duplicatas.
Comment auditer votre configuration actuelle ?
Commencez par extraire toutes les URLs bloquées par robots.txt (Screaming Frog peut le faire). Croisez avec les URLs indexées dans Search Console (site:votredomaine.com + filtres). Si des URLs bloquées apparaissent encore dans l'index, vous avez un problème : soit elles ont des backlinks externes, soit elles ont été indexées avant le blocage.
Pour les pages en noindex, vérifiez la fréquence de crawl dans les logs serveur. Si Google ne repasse que tous les 3 mois sur certaines sections, le noindex mettra autant de temps à faire effet. Dans ce cas, robots.txt peut être plus efficace si vous n'avez pas besoin de préserver des signaux sur ces pages.
- Listez toutes les URLs que vous souhaitez désindexer et vérifiez leur profil de backlinks
- Si backlinks présents : privilégiez noindex + redirection 301 vers contenu pertinent si possible
- Si aucun backlink et répertoire entier à exclure : robots.txt est acceptable
- Ne combinez jamais robots.txt et noindex sur la même URL
- Auditez régulièrement (tous les 3 mois) les URLs bloquées qui restent indexées
- Surveillez les messages Search Console sur les URLs bloquées par robots.txt mais avec backlinks
❓ Questions frequentes
Puis-je utiliser robots.txt et noindex en même temps sur une URL ?
Combien de temps faut-il pour qu'une page en noindex disparaisse de l'index ?
Si j'ai des URLs bloquées par robots.txt qui apparaissent encore dans l'index, que faire ?
Le choix entre robots.txt et noindex a-t-il un impact sur le PageRank ?
Pour un site e-commerce avec des milliers de pages filtrées, quelle méthode utiliser ?
🎥 De la même vidéo 18
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 24/12/2021
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.