Declaration officielle
Autres déclarations de cette vidéo 18 ▾
- □ Peut-on vraiment montrer du contenu payant structuré uniquement à Googlebot sans risque de pénalité ?
- □ Le DMCA s'applique-t-il vraiment page par page ou peut-on signaler un site entier ?
- □ Google indexe-t-il vraiment tout le contenu que vous publiez ?
- □ Une page AMP invalide peut-elle quand même être indexée par Google ?
- □ Safe Search peut-il empêcher votre site adulte de ranker sur votre propre marque ?
- □ Le Product Reviews Update peut-il impacter votre site même s'il n'est pas en anglais ?
- □ Géociblage ou hreflang : quelle méthode privilégier pour les contenus multilingues ?
- □ Google peut-il choisir arbitrairement quelle version linguistique indexer quand le contenu est identique ?
- □ Faut-il vraiment bloquer les URLs publicitaires dans robots.txt ?
- □ Faut-il abandonner l'injection dynamique de mots-clés pour éviter les pénalités Google ?
- □ Le client-side rendering React pose-t-il vraiment un problème de classement pour Google ?
- □ Les sites SEO sont-ils vraiment exemptés des critères YMYL ?
- □ Google pénalise-t-il les breadcrumbs structurés invisibles ou trompeurs ?
- □ Peut-on vraiment lier plusieurs sites dans le footer sans risque SEO ?
- □ Faut-il vraiment traduire l'intégralité d'un site multilingue pour bien se positionner ?
- □ Faut-il vraiment s'inquiéter du crawl budget sur un site de moins de 10 000 URLs ?
- □ Robots.txt ou noindex : lequel choisir pour bloquer l'indexation ?
- □ Le trafic artificiel influence-t-il vraiment le classement Google ?
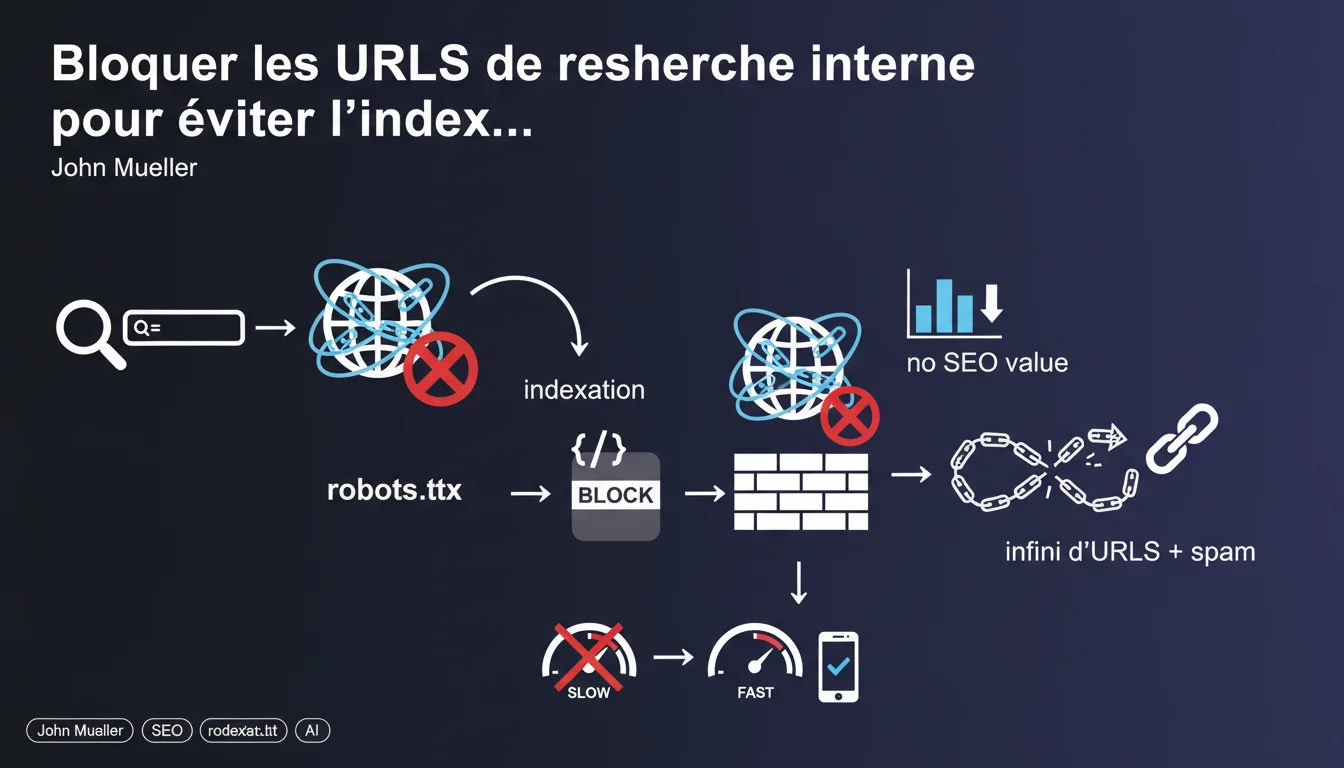
Google recommande de bloquer systématiquement les URLs de recherche interne via robots.txt pour éviter l'indexation d'un espace infini de pages sans valeur SEO. Cette directive vise à protéger le crawl budget et empêcher le spam de requêtes. Mais cette approche binaire mérite d'être nuancée selon les cas d'usage.
Ce qu'il faut comprendre
Pourquoi Google considère-t-il les URLs de recherche interne comme problématiques ?
Les moteurs de recherche interne génèrent des URLs paramétrées qui peuvent créer un nombre quasi infini de combinaisons. Chaque requête d'utilisateur produit une nouvelle URL, souvent avec des paramètres GET (ex: ?q=chaussures&filter=rouge&sort=price).
Pour Google, ces pages posent deux problèmes majeurs : elles diluent le crawl budget en forçant Googlebot à explorer des milliers de variantes sans valeur unique, et elles ouvrent la porte au spam par injection de requêtes dans les paramètres d'URL.
Qu'est-ce que cet "espace infini d'URLs" évoqué par Mueller ?
Concrètement : si votre site permet site.com/search?q=X, un bot malveillant ou même un scraper peut générer des millions d'URLs en testant toutes les combinaisons possibles de mots-clés. Googlebot suit ces liens, les crawle, tente de les évaluer.
Résultat : votre serveur croule sous les requêtes, votre crawl budget est épuisé sur du contenu dupliqué ou vide, et Google indexe potentiellement des pages "Aucun résultat trouvé" qui polluent vos SERPs. Un cauchemar technique et SEO.
Quelle est la recommandation officielle de Google sur ce point ?
John Mueller est catégorique : bloquer ces URLs dans robots.txt. Pas de noindex, pas de canonical — un blocage pur et simple pour que Googlebot ne les découvre même pas.
L'argument : ces pages n'apportent aucune valeur SEO puisqu'elles ne font que refléter des requêtes utilisateur ponctuelles, sans contenu éditorial stable ni intention de recherche externe cohérente.
- Les URLs de recherche interne créent un espace infini de variations sans valeur ajoutée
- Elles consomment du crawl budget inutilement et ralentissent l'indexation des vraies pages stratégiques
- Elles exposent le site au spam par injection de paramètres malveillants dans les URLs
- Google recommande un blocage robots.txt plutôt que noindex pour éviter même la découverte
Avis d'un expert SEO
Cette directive est-elle vraiment universelle ou existe-t-il des exceptions légitimes ?
Soyons honnêtes : la position de Mueller est valable pour 90% des sites, mais elle ignore certains cas d'usage spécifiques. Sur les gros sites e-commerce ou les marketplaces, certaines combinaisons de filtres représentent des intentions de recherche réelles avec du volume Google.
Exemple : "chaussures running femme Nike taille 38" peut correspondre à une vraie requête longue traîne. Si vous bloquez systématiquement toutes les URLs de facettes, vous perdez potentiellement du trafic qualifié. Amazon, Cdiscount ou Leboncoin indexent massivement ces pages — et ça fonctionne.
[A vérifier] : Google affirme "aucune valeur SEO", mais les données terrain montrent que des pages de recherche interne bien optimisées peuvent ranker et convertir, surtout sur des requêtes ultra-spécifiques que vos catégories standard ne couvrent pas.
Le blocage robots.txt est-il vraiment la meilleure solution technique ?
Bloquer dans robots.txt empêche la découverte, certes — mais si un lien externe pointe vers une de ces URLs (backlink, partage social), Google la verra dans ses logs et la traitera comme une page bloquée avec autorité inconnue. C'est rarement optimal.
En réalité, une combinaison noindex + canonical vers la page parent offre plus de souplesse : elle permet à Google de comprendre la relation entre les pages tout en évitant l'indexation. Pour les sites complexes, une gestion via Search Console des paramètres d'URL (bien que dépréciée) ou via rel="canonical" dynamique reste plus chirurgicale.
Quid des sites où la recherche interne génère du contenu unique agrégé ?
Certains sites affichent sur les pages de résultats de recherche interne des contenus éditoriaux contextuels, des guides d'achat, ou des agrégations pertinentes. Dans ce cas, ces pages ne sont plus de simples miroirs de requêtes — elles deviennent des landing pages à part entière.
Là, bloquer serait contre-productif. Mais cela suppose une véritable stratégie éditoriale derrière chaque template de recherche, pas juste un listing produits générique. La nuance est essentielle : Mueller parle des pages "par défaut", pas des cas où vous investissez dans du contenu différenciant.
Impact pratique et recommandations
Que faut-il faire concrètement si vous indexez actuellement vos pages de recherche interne ?
Première étape : audit dans Search Console. Filtrez vos URLs indexées par paramètre (?q=, ?search=, ?s=) et évaluez le volume. Si vous avez des milliers de pages de ce type avec zéro impression, c'est un signal clair qu'elles pompent du crawl budget pour rien.
Ensuite, décidez du traitement : blocage robots.txt si aucune valeur SEO identifiable, ou noindex + canonical si certaines variantes méritent d'être préservées pour l'UX mais pas indexées. Ne mélangez jamais les deux approches sur le même pattern d'URL.
Comment implémenter le blocage robots.txt sans casser l'existant ?
Ajoutez dans votre robots.txt une directive ciblée comme Disallow: /search? ou Disallow: /*?q= selon votre structure. Testez d'abord avec l'outil de test robots.txt de Search Console pour éviter de bloquer accidentellement des URLs stratégiques.
Si des pages de recherche interne sont déjà indexées, Google finira par les supprimer naturellement après quelques crawls — mais cela peut prendre des semaines. Pour accélérer, soumettez une demande de suppression via Search Console, puis attendez que l'index se nettoie avant de mesurer l'impact sur le crawl budget.
Quelles erreurs critiques éviter lors de cette migration ?
Ne bloquez jamais dans robots.txt une URL que vous avez mise en noindex — c'est contradictoire et Google ne pourra pas lire la balise meta. Résultat : la page reste dans l'index avec la mention "Bloquée par robots.txt".
Évitez aussi de bloquer trop large : Disallow: /*? va tuer toutes vos URLs avec paramètres, y compris les IDs de session, les paramètres de tracking UTM, ou les variantes de pagination légitimes. Soyez chirurgical dans vos patterns.
- Auditer l'index actuel pour identifier les URLs de recherche interne déjà indexées
- Choisir entre blocage robots.txt (si aucune valeur) ou noindex + canonical (si besoin de contrôle fin)
- Tester les directives robots.txt avant déploiement avec l'outil Search Console
- Supprimer manuellement les URLs indexées via Search Console pour accélérer le nettoyage
- Ne jamais combiner robots.txt + noindex sur le même pattern
- Monitorer le crawl budget et le taux d'indexation dans les semaines suivant la migration
❓ Questions frequentes
Puis-je utiliser noindex au lieu de robots.txt pour bloquer les pages de recherche interne ?
Si je bloque mes URLs de recherche interne, est-ce que je perds le trafic des utilisateurs qui cliquent dessus depuis Google ?
Les filtres produit sur un site e-commerce sont-ils considérés comme de la recherche interne ?
Combien de temps faut-il pour que Google désindexe les pages de recherche interne après blocage robots.txt ?
Le blocage des URLs de recherche interne améliore-t-il vraiment le crawl budget ?
🎥 De la même vidéo 18
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 24/12/2021
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.