Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Faut-il se fier à PageSpeed Insights ou à la Search Console pour mesurer la vitesse de son site ?
- □ Google indexe-t-il vraiment tout le contenu de votre site ?
- □ Pourquoi Googlebot ignore-t-il vos liens JavaScript si vous n'utilisez pas de balises <a> ?
- □ Google a-t-il vraiment abandonné l'idée d'un score SEO global ?
- □ Peut-on créer des liens vers des sites HTTP sans risque SEO ?
- □ Faut-il vraiment écrire « naturellement » pour ranker sur Google ?
- □ Faut-il vraiment supprimer son fichier de désaveu de liens ?
- □ Faut-il vraiment éviter d'implémenter le Schema markup via Google Tag Manager ?
- □ Peut-on dupliquer la même URL dans plusieurs fichiers sitemap sans risque SEO ?
- □ Comment indexer le contenu d'une iframe sans indexer la page source ?
- □ HSTS et preload list : une fausse piste pour le référencement ?
- □ Pourquoi un nom de domaine descriptif ne garantit-il pas votre classement sur sa requête ?
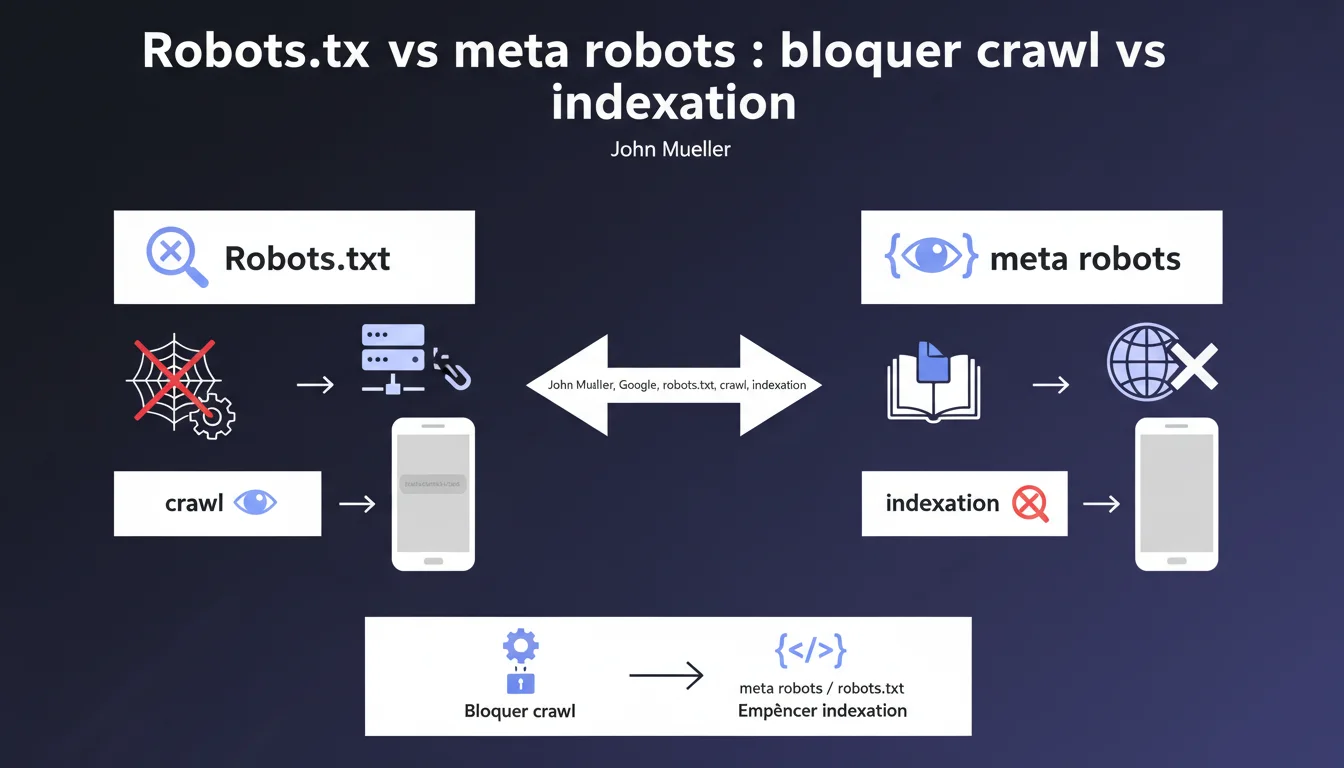
Robots.txt bloque l'exploration mais l'URL peut apparaître dans Google sans contenu ni description. La balise meta robots noindex permet à Google de voir la page avant de la retirer complètement. Pour une désindexation propre, privilegiez le noindex plutôt que le robots.txt.
Ce qu'il faut comprendre
Quelle est la différence fondamentale entre ces deux méthodes ?
Le robots.txt empêche Googlebot d'accéder à une page. Le robot ne peut ni lire le contenu, ni analyser les balises meta, ni suivre les liens. C'est un garde-barrière qui dit « n'entre pas ».
La balise meta robots noindex fonctionne à l'opposé : elle laisse Google explorer la page, lire son contenu, comprendre sa structure — puis lui demande de ne pas l'indexer. Le robot entre, constate qu'on ne veut pas de cette page dans l'index, et la retire ou ne l'ajoute jamais.
Pourquoi une URL bloquée par robots.txt peut-elle quand même apparaître dans les résultats ?
Google peut découvrir une URL via des liens externes ou des sitemaps, sans jamais crawler la page elle-même. Dans ce cas, l'URL peut apparaître dans les SERP avec la mention « Aucune information disponible » — parce que Google sait que la page existe, mais n'a jamais pu y accéder pour vérifier son contenu.
C'est paradoxal mais logique : robots.txt bloque le crawl, pas la connaissance de l'existence de l'URL. Si vous voulez qu'une page disparaisse totalement des résultats, bloquer l'accès ne suffit pas.
Quand utiliser l'une ou l'autre méthode ?
Utilisez robots.txt pour économiser du crawl budget sur des ressources inutiles : fichiers JS lourds, PDF internes, pages de filtres infinis, zones admin. L'objectif est d'éviter que Google perde du temps sur ces URLs.
Utilisez meta robots noindex quand vous voulez qu'une page soit totalement absente de l'index : pages de remerciement, résultats de recherche interne, pages privées mais accessibles. Google doit pouvoir lire la directive pour l'appliquer — donc pas de blocage en amont.
- Robots.txt : contrôle le crawl, pas l'indexation — l'URL peut rester visible
- Meta robots noindex : contrôle l'indexation — Google doit pouvoir crawler pour lire la directive
- Ne jamais combiner les deux : bloquer une page en robots.txt empêche Google de voir le noindex
- Pour retirer complètement une URL, privilégiez toujours le noindex
Avis d'un expert SEO
Cette distinction est-elle vraiment respectée par Google dans la pratique ?
Oui, et c'est un piège classique. On voit régulièrement des sites qui bloquent des pages sensibles en robots.txt — pages de compte, paniers abandonnés, filtres de recherche — et qui découvrent ensuite ces URLs dans Google avec le message « Description non disponible pour cette page ».
Le problème ? Ces URLs sont connues via des backlinks ou des fuites de sitemap. Google les indexe comme « pages existantes » sans jamais pouvoir y accéder. Résultat : vous avez des URLs zombies dans l'index, sans contrôle sur leur présentation.
Quelles erreurs terrain voit-on encore trop souvent ?
L'erreur numéro un : bloquer en robots.txt une page qu'on veut désindexer. Exemple typique : une refonte où on bloque l'ancien site en robots.txt pour « forcer » la désindexation. Google ne peut plus crawler, donc ne voit jamais les redirections 301, les balises noindex, rien. Les anciennes URLs restent dans l'index pendant des mois.
Deuxième erreur fréquente : mettre un noindex sur une page puis la bloquer en robots.txt « par sécurité ». Google ne peut plus vérifier si le noindex est toujours présent — et peut réindexer la page s'il la juge pertinente via des signaux externes. [A vérifier] sur des volumes importants, car Google semble parfois ignorer cette règle si la page reçoit beaucoup de signaux positifs.
Google est-il cohérent avec ses propres recommandations historiques ?
Pendant des années, Google a dit « utilisez robots.txt pour bloquer l'indexation » — ce qui était techniquement faux mais fonctionnait souvent en pratique, parce que Google ne crawlait pas et finissait par retirer les URLs de l'index. Puis la Search Console a commencé à signaler des « URLs indexées malgré le blocage robots.txt ».
Aujourd'hui, le message est clair : robots.txt ne garantit pas la désindexation. C'est un changement de doctrine assumé, et il faut adapter les pratiques en conséquence — surtout pour les gros sites où on gérait historiquement l'indexation via robots.txt.
Impact pratique et recommandations
Que faut-il auditer en priorité sur un site existant ?
Commencez par croiser deux sources : les URLs bloquées en robots.txt (via votre CMS ou un crawl Screaming Frog en mode liste) et les URLs indexées dans Google (via site: ou la Search Console). Toute intersection entre ces deux listes est un problème potentiel.
Ensuite, vérifiez les pages avec noindex : sont-elles accessibles au crawl ? Si vous avez un noindex sur une page bloquée en robots.txt, la directive est inutile — Google ne peut pas la lire. Débloquez, attendez le recrawl, puis rebloquez si nécessaire pour économiser du crawl budget.
Comment corriger une désindexation mal configurée ?
Si des pages sont bloquées en robots.txt mais apparaissent dans l'index : débloquez-les immédiatement. Ajoutez une balise <meta name="robots" content="noindex"> dans le <head>. Demandez une réindexation via la Search Console pour accélérer le processus.
Une fois les pages désindexées (vérifiez avec site:votreurl.com), vous pouvez rebloquer en robots.txt si vous voulez économiser du crawl budget. Mais si le risque d'indexation via liens externes existe, laissez le noindex en place — c'est plus sûr.
Quelles bonnes pratiques adopter pour éviter ces erreurs à l'avenir ?
- Ne jamais bloquer en robots.txt une page que vous voulez désindexer — utilisez toujours meta robots noindex
- Réservez robots.txt au contrôle du crawl budget : ressources inutiles, fichiers lourds, zones admin sans valeur SEO
- Auditez régulièrement les URLs indexées malgré un blocage robots.txt via la Search Console (rapport Couverture)
- Documentez clairement la stratégie d'indexation : quelles pages doivent être crawlées, lesquelles indexées, lesquelles ni l'un ni l'autre
- Testez vos directives sur un environnement de staging avant de les déployer en production
- Utilisez la Search Console pour forcer le recrawl des pages critiques après modification des directives
❓ Questions frequentes
Peut-on utiliser robots.txt ET meta robots noindex sur la même page ?
Pourquoi mes pages bloquées en robots.txt apparaissent-elles encore dans Google ?
Le X-Robots-Tag HTTP fonctionne-t-il comme la balise meta robots ?
Combien de temps faut-il pour qu'une page en noindex disparaisse de l'index ?
Faut-il retirer les pages en noindex du sitemap XML ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/07/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.