Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Faut-il se fier à PageSpeed Insights ou à la Search Console pour mesurer la vitesse de son site ?
- □ Google indexe-t-il vraiment tout le contenu de votre site ?
- □ Google a-t-il vraiment abandonné l'idée d'un score SEO global ?
- □ Peut-on créer des liens vers des sites HTTP sans risque SEO ?
- □ Faut-il vraiment écrire « naturellement » pour ranker sur Google ?
- □ Faut-il vraiment supprimer son fichier de désaveu de liens ?
- □ Faut-il vraiment éviter d'implémenter le Schema markup via Google Tag Manager ?
- □ Robots.txt vs meta robots : pourquoi bloquer le crawl peut-il nuire à la désindexation ?
- □ Peut-on dupliquer la même URL dans plusieurs fichiers sitemap sans risque SEO ?
- □ Comment indexer le contenu d'une iframe sans indexer la page source ?
- □ HSTS et preload list : une fausse piste pour le référencement ?
- □ Pourquoi un nom de domaine descriptif ne garantit-il pas votre classement sur sa requête ?
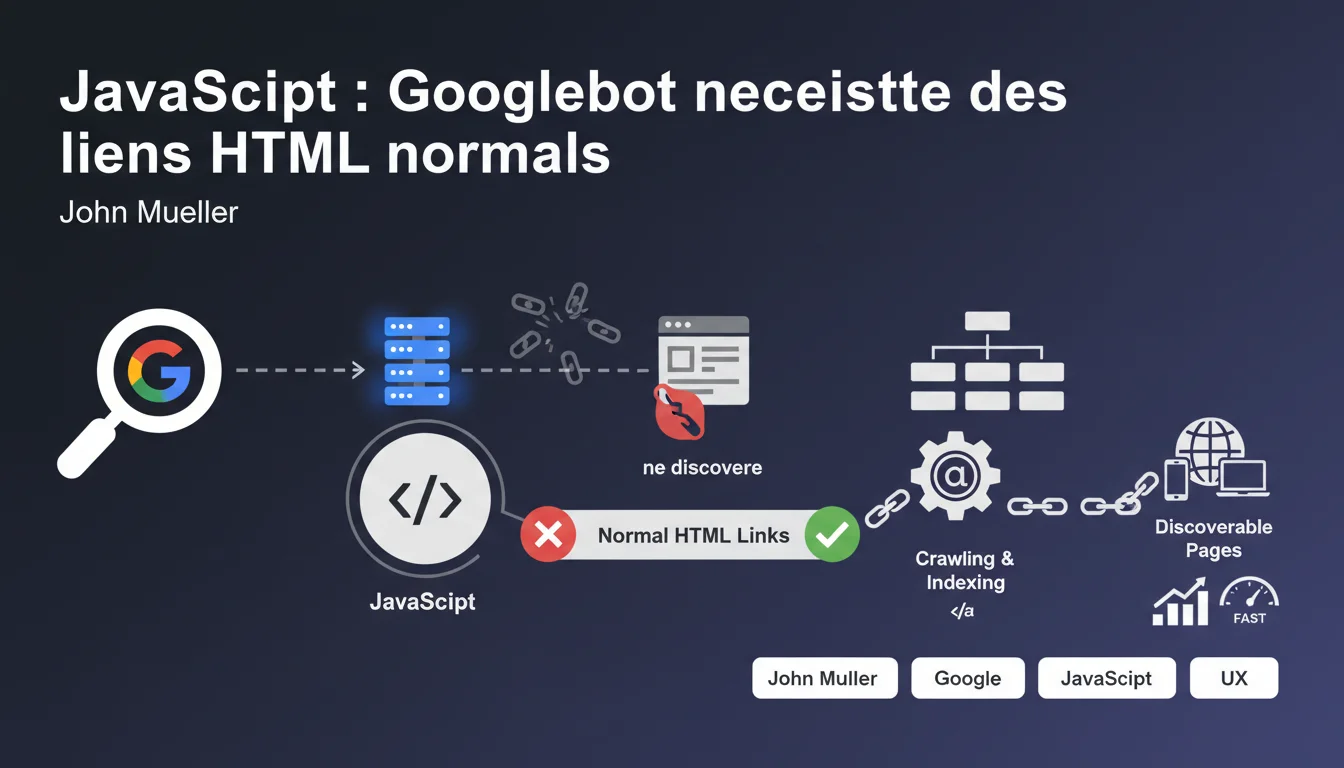
Googlebot ne clique pas sur les éléments interactifs pour découvrir vos pages — il cherche exclusivement des liens HTML classiques (balises <a>). Si votre framework JavaScript génère des liens via du JavaScript pur (onClick, routeurs SPA sans fallback HTML), Google risque de ne jamais découvrir une partie de votre site. La solution : s'assurer que chaque lien important existe sous forme de balise <a> avec un attribut href valide.
Ce qu'il faut comprendre
Qu'est-ce que Google entend exactement par "liens HTML normaux" ?
Un lien HTML normal, c'est une balise <a href="/page"> classique. Pas un <div onClick="navigate()">, pas un bouton géré par un écouteur d'événement JavaScript, pas un lien dynamique injecté après coup par React ou Vue.
Googlebot parse le DOM rendu — il exécute bien le JavaScript depuis plusieurs années — mais il ne simule pas le comportement d'un utilisateur qui clique partout. Il cherche des attributs href dans des balises <a>. Point.
Pourquoi cette distinction est-elle cruciale pour l'exploration ?
Beaucoup de frameworks modernes (React Router, Vue Router, Next.js en mode client-side) génèrent des Single Page Applications (SPA) où la navigation se fait sans rechargement complet de la page. Si ces frameworks n'exposent pas de vraies balises <a> dans le HTML, Googlebot ne détecte pas les liens.
Concrètement : vous pouvez avoir 500 pages parfaitement fonctionnelles côté utilisateur, mais si elles ne sont accessibles que via des événements JavaScript sans balise <a>, Google ne les verra jamais — sauf si elles apparaissent dans votre sitemap XML ou via des liens externes.
Est-ce que cela concerne uniquement les sites en JavaScript ?
Non. Même un site WordPress classique peut tomber dans ce piège si un plugin de menu utilise du JavaScript pour gérer la navigation sans générer de vrais liens HTML. Ou si vous implémentez un mega-menu dynamique qui charge les sous-rubriques en AJAX sans ancres HTML.
La règle est universelle : Googlebot ne clique pas, il lit le DOM. S'il n'y a pas de <a href>, il n'y a pas de découverte automatique.
- Googlebot cherche exclusivement des balises
<a>avec un attributhrefvalide - Il n'interagit pas avec les éléments cliquables (boutons, divs, événements onClick)
- Les frameworks JavaScript modernes doivent générer des liens HTML classiques, même en mode SPA
- Le sitemap XML ou les liens externes peuvent compenser partiellement, mais ne remplacent pas une architecture de liens interne solide
- Cette règle s'applique à tous les types de sites, pas uniquement aux applications JavaScript complexes
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est un rappel bienvenu. On observe régulièrement des sites en SPA où des sections entières ne sont pas indexées parce que les développeurs ont privilégié l'expérience utilisateur (navigation fluide, pas de rechargement) sans penser au crawl. [A vérifier] : Google prétend exécuter le JavaScript "comme un navigateur moderne", mais dans la pratique, le rendering budget est limité — si votre JS met 5 secondes à charger, Googlebot ne verra peut-être pas vos liens dynamiques injectés tardivement.
Les frameworks modernes (Next.js, Nuxt, SvelteKit) ont intégré cette contrainte depuis longtemps : ils génèrent des <a> classiques même en mode client-side routing. Mais beaucoup de développeurs custom ou de vieux setups React passent encore à côté.
Quelles nuances faut-il apporter à cette règle ?
Google ne dit pas que le JavaScript est un problème en soi — il dit que l'absence de balises <a> est un problème. Si ton React Router génère du <Link to="/page"> qui se transforme en <a href="/page"> dans le DOM, tout va bien.
Mais — et c'est là que ça coince — si ton menu se charge en lazy loading après un scroll ou un hover, et que la balise <a> n'apparaît qu'à ce moment-là, Googlebot risque de ne jamais la voir. Il ne scroll pas, il ne hover pas.
Dans quels cas cette règle peut-elle poser problème ?
Sur les sites e-commerce avec filtres JavaScript : si les pages filtrées (ex: "Chaussures rouges taille 42") ne sont accessibles que via des boutons JavaScript sans URL dédiée ni balise <a>, elles ne seront jamais indexées. Même logique pour les sites d'annonces ou les portfolios avec navigation modale.
Le piège classique : un développeur implémente un système de pagination en JavaScript pur (bouton "Charger plus" sans URL) — résultat, seule la première page est crawlée. Soyons honnêtes : beaucoup de sites perdent 30 à 50% de leur potentiel d'indexation à cause de ce genre de détails.
Impact pratique et recommandations
Que faut-il faire concrètement pour s'assurer que vos liens sont crawlables ?
Audit technique immédiat : inspectez le DOM rendu de vos pages clés. Désactivez JavaScript dans Chrome DevTools (Cmd+Shift+P > "Disable JavaScript") et vérifiez si vos liens de navigation principaux sont toujours présents. Si la moitié de votre menu disparaît, vous avez un problème.
Pour les frameworks JavaScript : utilisez des composants qui génèrent des vraies balises <a>. React Router ? <Link>. Next.js ? <Link>. Vue Router ? <router-link> qui compile en <a>. Évitez les <div onClick={navigate}> pour la navigation principale.
Quelles erreurs éviter absolument ?
Ne vous fiez pas uniquement au sitemap XML pour compenser une mauvaise architecture de liens. Google explore en priorité les liens internes — le sitemap est un complément, pas une béquille. Si vos pages ne sont liées nulle part en HTML, elles auront moins de poids en crawl budget.
Autre erreur fréquente : les mega-menus qui chargent leurs sous-rubriques en AJAX au survol. Si ces sous-rubriques n'existent pas sous forme de <a> dans le HTML initial, Googlebot ne les verra pas. Solution : injecter tous les liens dans le HTML, même masqués en CSS, ou utiliser un menu mobile-first qui les expose par défaut.
Comment vérifier que votre site est conforme ?
Trois vérifications rapides : (1) Crawlez votre site avec Screaming Frog ou Sitebulb en mode "Googlebot smartphone" — comparez le nombre de pages découvertes avec votre inventory réel. (2) Utilisez l'outil d'inspection d'URL dans Search Console et regardez le DOM rendu — vérifiez que vos liens internes apparaissent bien. (3) Testez vos pages en JavaScript désactivé pour identifier les liens qui dépendent du JS.
Si vous détectez des écarts importants, le correctif peut être technique : refactoriser un composant React, ajuster votre système de routing, ou restructurer votre menu. Ces optimisations nécessitent souvent une expertise croisée SEO-développement — erreur courante, les développeurs ne pensent pas spontanément crawl, et les SEO ne maîtrisent pas toujours les subtilités des frameworks modernes.
- Auditez le DOM rendu de vos pages clés avec JavaScript désactivé
- Vérifiez que tous vos liens de navigation utilisent des balises
<a href> - Si vous utilisez un framework JS, privilégiez les composants natifs (Link, router-link) qui génèrent du HTML valide
- Crawlez votre site avec un outil professionnel et comparez le nombre de pages découvertes à votre inventory
- Contrôlez le DOM rendu dans Search Console pour confirmer la présence des liens
- Évitez les liens conditionnels (affichés uniquement après un clic ou un scroll)
- Ne comptez pas uniquement sur le sitemap XML pour compenser une architecture défaillante
<a>. Si vos liens dépendent d'événements JavaScript sans fallback HTML, une partie de votre site restera invisible. Cette problématique touche autant les SPAs complexes que les sites WordPress mal configurés. L'audit technique est la première étape, mais la mise en conformité peut impliquer des refactorisations profondes — si votre stack technique est complexe ou si vous constatez des pertes d'indexation importantes, un accompagnement par une agence SEO spécialisée dans le JavaScript SEO peut vous faire gagner des mois et éviter des erreurs coûteuses.❓ Questions frequentes
Est-ce que Googlebot exécute le JavaScript ou pas ?
Mon site en React utilise React Router, est-ce suffisant ?
Le sitemap XML peut-il compenser l'absence de liens HTML ?
Comment tester si mes liens sont crawlables par Googlebot ?
Les attributs rel=nofollow bloquent-ils la découverte des pages ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/07/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.