Faut-il vraiment éviter de combiner noindex, canonical et disallow sur une même page ?
John Mueller
23/07/2018
★★★
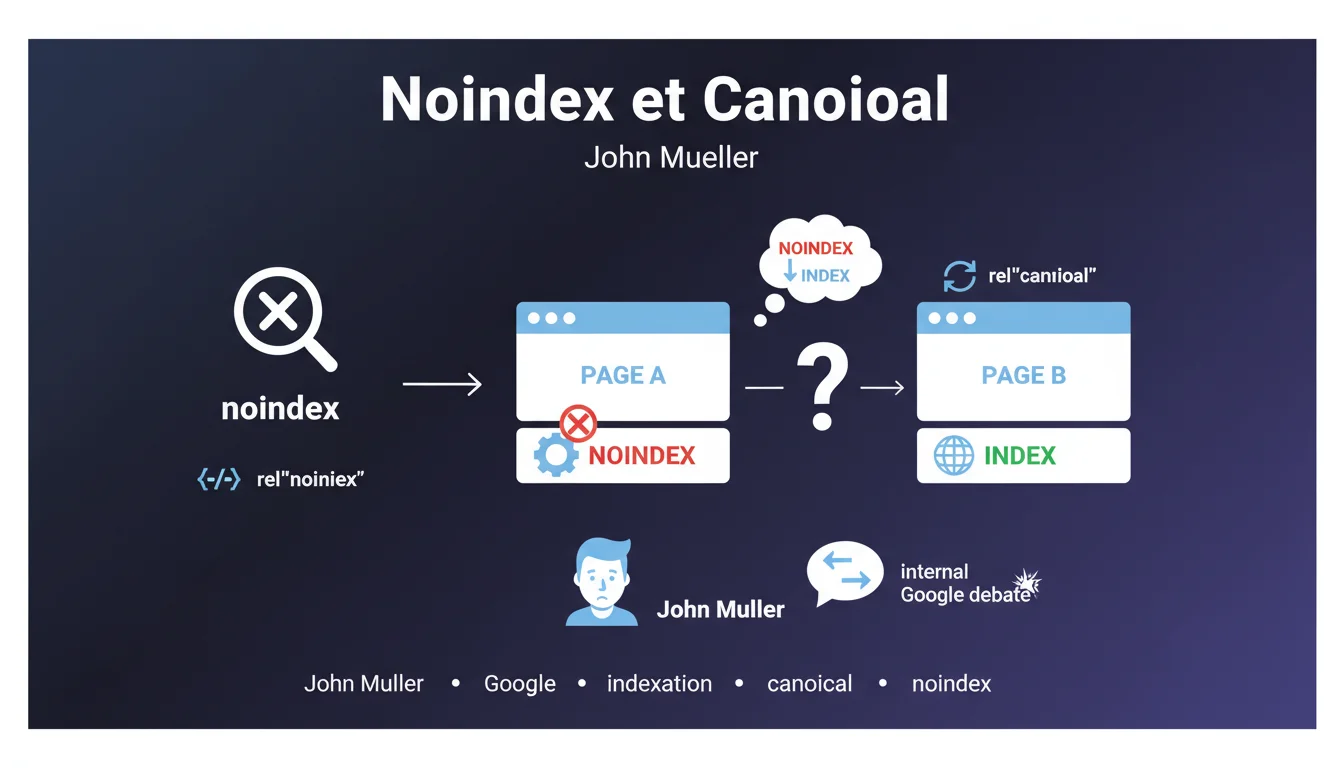
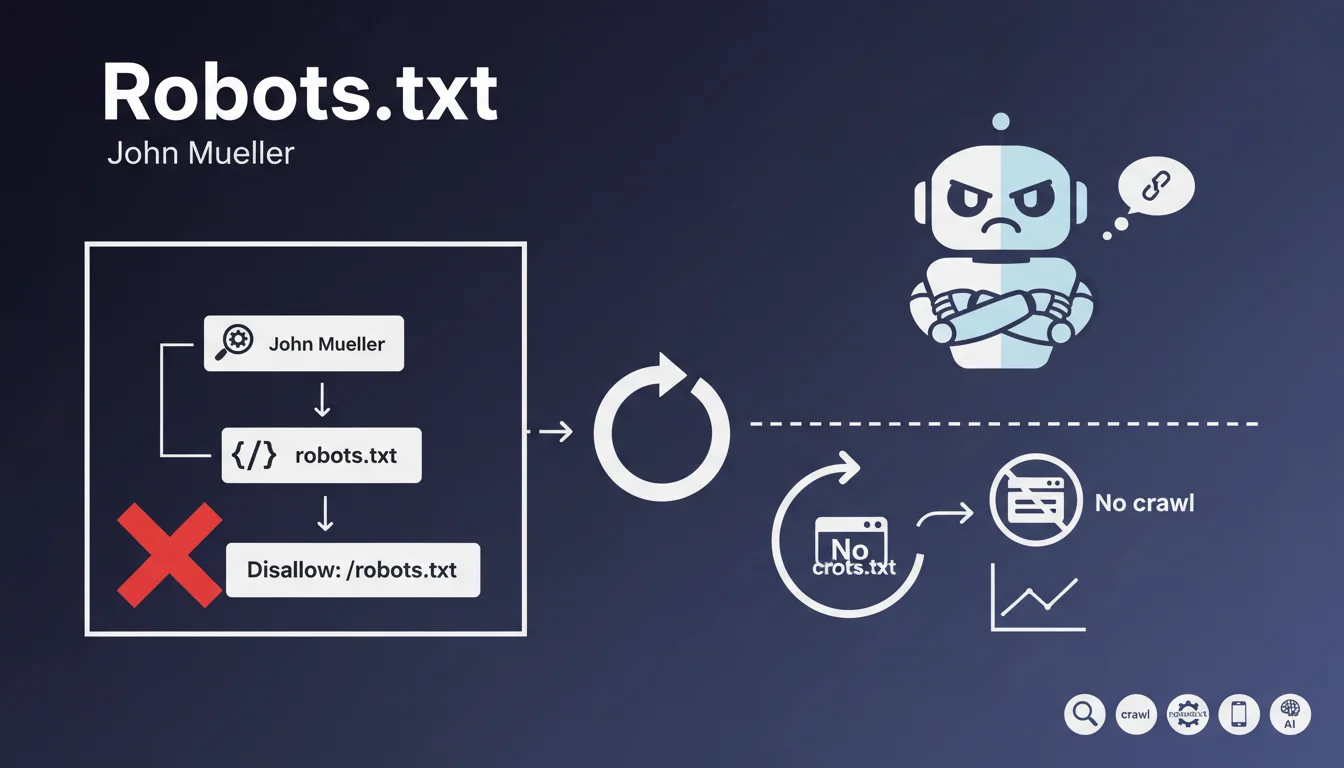
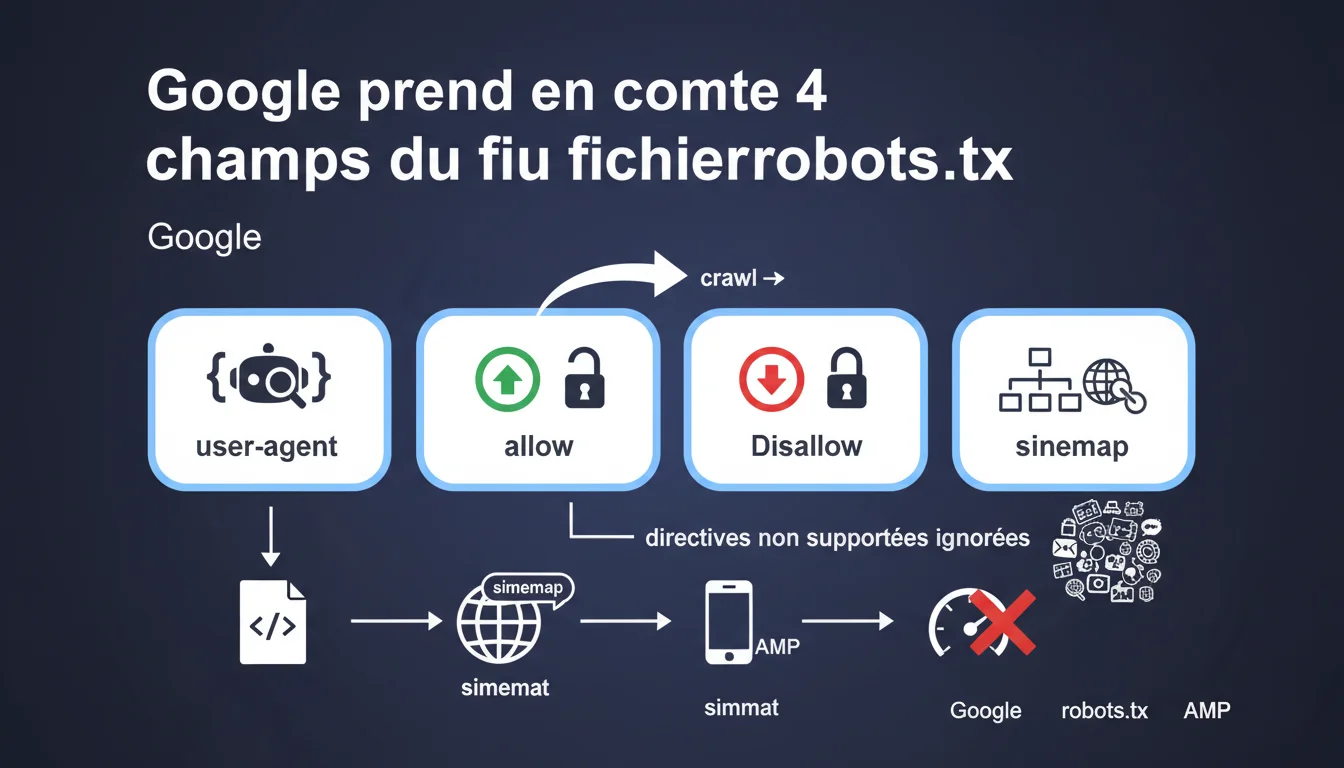
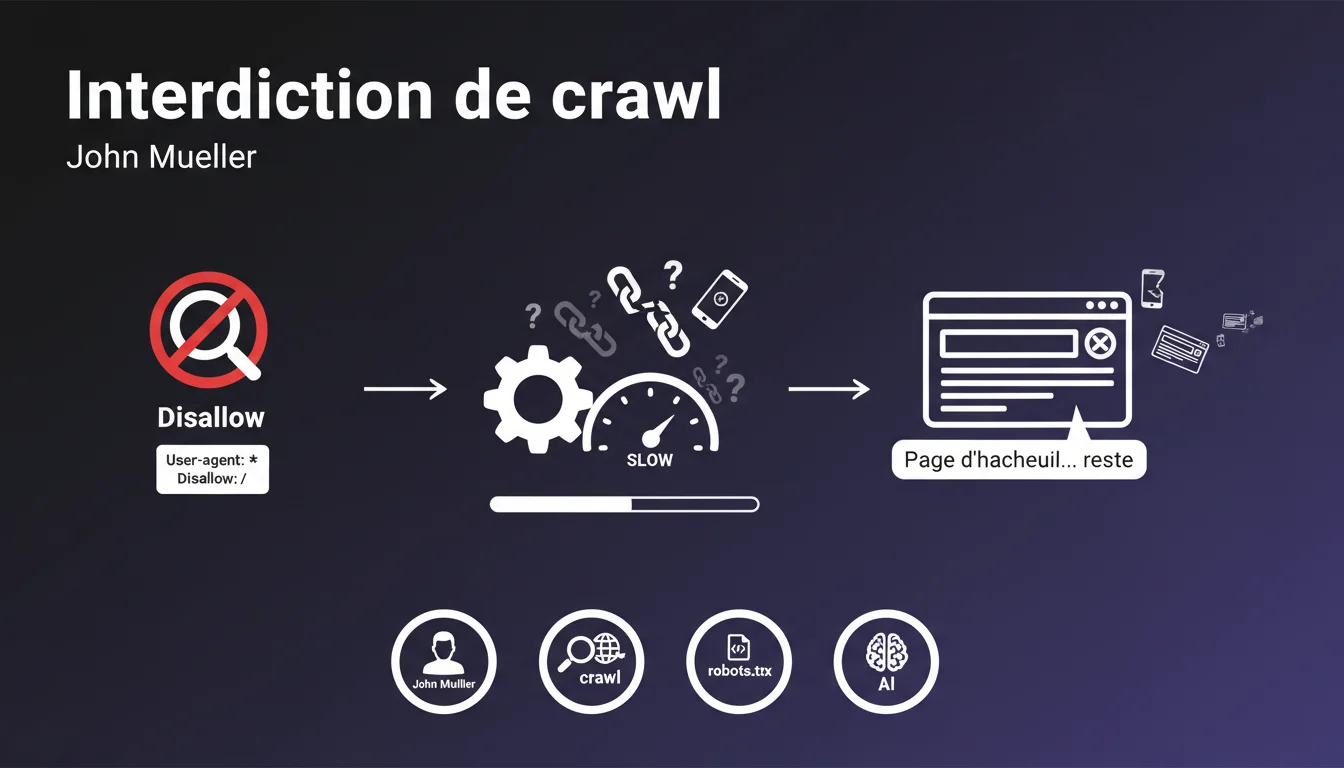
John Mueller, sur Reddit cette fois, a indiqué que les balises Canonical et meta robots "noindex" (tout comme les Disallow: dans le fichier ...