Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Les snippets mal optimisés peuvent-ils vraiment faire chuter votre trafic organique ?
- □ Pourquoi vos requêtes de crawl tombent-elles à zéro dans Search Console ?
- □ Search Console suffit-il vraiment à détecter tous vos problèmes de crawl ?
- □ Search Console suffit-elle vraiment pour diagnostiquer vos problèmes d'indexation ?
- □ Quels outils Google faut-il vraiment utiliser pour auditer correctement un site ?
- □ Lighthouse peut-il vraiment remplacer un audit SEO professionnel ?
- □ Un robots.txt mal configuré peut-il vraiment bloquer vos snippets et votre crawl ?
- □ Faut-il vraiment monitorer votre robots.txt en continu ?
- □ Faut-il vraiment tester son robots.txt avant chaque modification ?
- □ Faut-il bloquer certaines sections de votre site dans le robots.txt ?
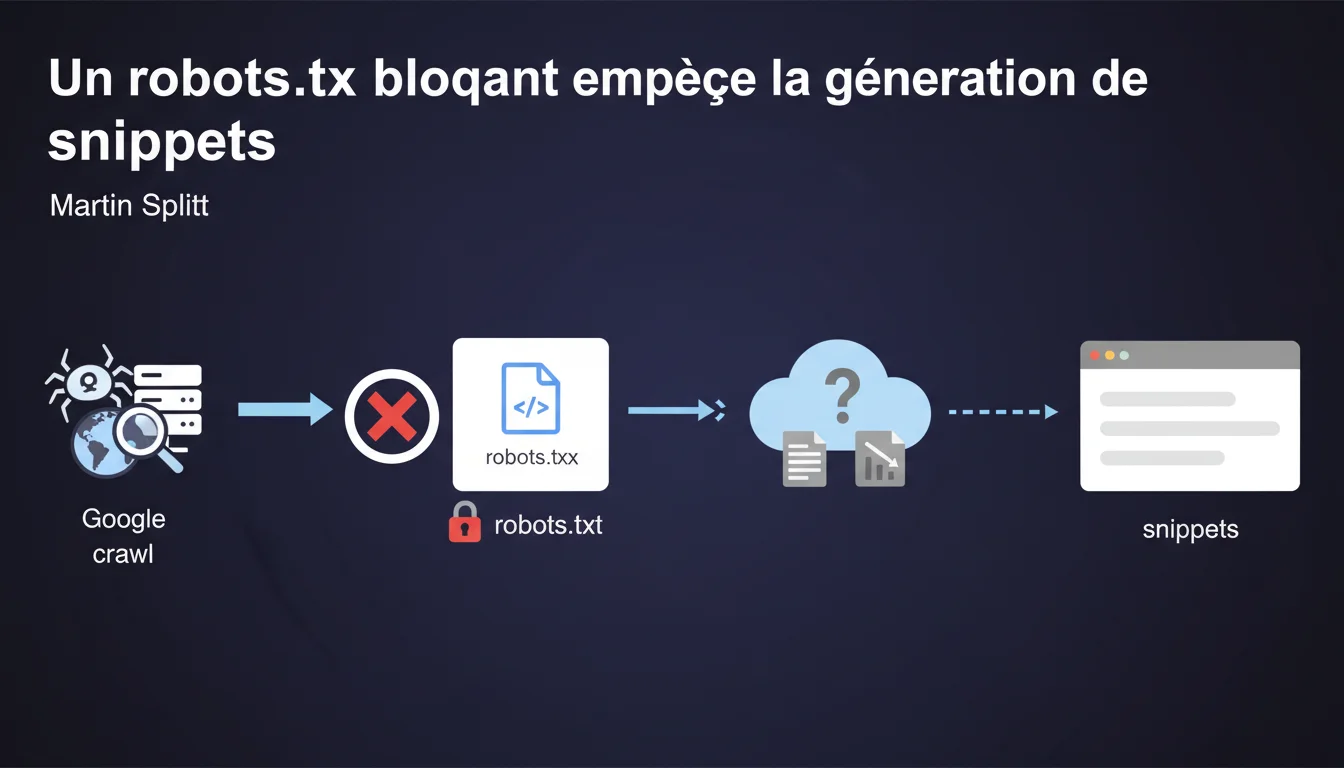
Martin Splitt confirme qu'un robots.txt bloquant empêche Google de générer des snippets dans les résultats de recherche. Sans accès au contenu via le crawl, Google ne dispose d'aucune donnée pour composer une description. Le résultat apparaît donc sans extrait, ce qui dégrade drastiquement le CTR.
Ce qu'il faut comprendre
Pourquoi un disallow dans robots.txt bloque-t-il les snippets ?
Quand une directive disallow figure dans le robots.txt, Googlebot ne peut pas crawler les pages concernées. Sans crawler, pas de lecture du contenu HTML, des balises meta description, ni du texte visible.
Le moteur se retrouve donc incapable de composer un snippet — cet extrait qui s'affiche sous le titre dans les SERP. La page peut être indexée via des liens externes, mais elle apparaît nue : titre uniquement, sans description.
Quelle différence entre indexation et snippet ?
Une page bloquée en robots.txt peut quand même être indexée si Google la découvre via des backlinks. C'est une nuance capitale que beaucoup de praticiens oublient.
Par contre, sans accès au contenu, impossible de générer un snippet. Google affiche alors un message générique du type « Aucune information disponible pour cette page ».
Quels sont les impacts concrets sur la visibilité ?
Un résultat sans snippet, c'est un CTR effondré. L'utilisateur n'a aucune idée du contenu de la page, aucun élément pour juger de sa pertinence.
Les concurrents avec des snippets bien rédigés captent mécaniquement plus de clics, même avec un positionnement équivalent. Le trafic organique en pâtit directement.
- Robots.txt disallow empêche le crawl, donc la lecture du contenu
- Sans contenu crawlé, pas de snippet généré dans les SERP
- La page peut être indexée via des liens externes, mais reste « vide »
- Le CTR s'effondre faute d'extrait informatif
- Cette situation s'applique à toutes les pages, pas seulement les nouvelles
Avis d'un expert SEO
Cette déclaration colle-t-elle aux observations terrain ?
Oui, et c'est même un classique des audits SEO. On trouve régulièrement des sites avec un robots.txt mal configuré qui bloque des sections entières, parfois par erreur après une migration.
Les pages concernées figurent dans l'index, mais sans snippet — signe typique d'un problème de crawlabilité. La Search Console remonte d'ailleurs ces URLs comme « Indexées, bien que bloquées par robots.txt ».
Quelles nuances faut-il apporter ?
Le discours de Martin Splitt est factuel mais incomplet. Il ne précise pas que Google peut quand même indexer une URL bloquée en robots.txt si elle reçoit des backlinks — c'est une confusion fréquente chez les débutants.
Autre point : même si le contenu est crawlable, un noindex en X-Robots-Tag ou meta empêche carrément l'indexation. Donc pas de présence dans les SERP, snippet ou pas. Les deux mécanismes (robots.txt et noindex) se complètent mais ne se substituent pas. [A vérifier] : Google n'a jamais clarifié publiquement si certains types de contenus (images, vidéos embarquées) peuvent générer des snippets partiels malgré un disallow partiel.
Quel piège rencontre-t-on le plus souvent ?
Le cas classique : un site bloque /wp-admin/ et /wp-includes/ en robots.txt — normal — mais ajoute par erreur une ligne Disallow: /wp-content/ qui barre l'accès aux ressources CSS, JS, images.
Google ne peut plus rendre correctement les pages, ce qui impacte l'indexation mobile (rendering incomplet) et dégrade l'expérience perçue. Le snippet peut être généré, mais tronqué ou incohérent.
Impact pratique et recommandations
Que faut-il vérifier en priorité sur son site ?
Première étape : auditer le robots.txt. Télécharge-le directement (monsite.com/robots.txt) et passe chaque directive au crible. Cherche des disallow trop larges, des wildcards mal placés, des sections critiques bloquées par erreur.
Ensuite, croise avec la Search Console : l'onglet « Couverture » signale les URLs indexées malgré un blocage robots.txt. Si tu en trouves, c'est qu'elles reçoivent des backlinks — mais sans snippet.
Comment corriger un robots.txt qui bloque les snippets ?
Supprime ou affine la directive Disallow concernée. Si tu veux empêcher l'indexation, utilise plutôt une balise meta name="robots" content="noindex" ou un header HTTP X-Robots-Tag.
Après modification du robots.txt, demande une réindexation via la Search Console. Google recrawle, découvre le contenu, génère le snippet. Ça peut prendre quelques jours selon le crawl budget.
Quelles erreurs éviter absolument ?
Ne mélange jamais robots.txt disallow et noindex sur la même URL. Le robots.txt bloque le crawl, donc Google ne peut pas lire la balise noindex — la page reste indexée, sans snippet. C'est contre-productif.
Autre piège : bloquer les paramètres d'URL (ex: Disallow: /*?) sans réfléchir. Certains paramètres servent au tracking mais d'autres génèrent du contenu unique — tu risques de couper l'accès à des pages utiles.
- Télécharger et analyser le fichier robots.txt ligne par ligne
- Vérifier dans la Search Console les URLs « Indexées, bien que bloquées par robots.txt »
- Retirer les disallow sur les contenus destinés aux SERP
- Utiliser meta noindex ou X-Robots-Tag pour empêcher l'indexation, pas robots.txt
- Tester le robots.txt avec l'outil de la Search Console avant toute modification
- Ne jamais bloquer CSS, JS, images en robots.txt — ça casse le rendering
- Demander une réindexation après correction pour accélérer le recrawl
❓ Questions frequentes
Une page bloquée en robots.txt peut-elle quand même apparaître dans Google ?
Quelle différence entre robots.txt disallow et meta noindex ?
Combien de temps faut-il pour que Google génère un snippet après correction du robots.txt ?
Peut-on bloquer certaines sections en robots.txt sans perdre les snippets ailleurs ?
Faut-il bloquer les ressources CSS et JS en robots.txt pour économiser le crawl budget ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 10/01/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.