Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Les snippets mal optimisés peuvent-ils vraiment faire chuter votre trafic organique ?
- □ Pourquoi vos requêtes de crawl tombent-elles à zéro dans Search Console ?
- □ Robots.txt en disallow bloque-t-il vraiment la génération de snippets dans les SERP ?
- □ Search Console suffit-il vraiment à détecter tous vos problèmes de crawl ?
- □ Search Console suffit-elle vraiment pour diagnostiquer vos problèmes d'indexation ?
- □ Quels outils Google faut-il vraiment utiliser pour auditer correctement un site ?
- □ Lighthouse peut-il vraiment remplacer un audit SEO professionnel ?
- □ Un robots.txt mal configuré peut-il vraiment bloquer vos snippets et votre crawl ?
- □ Faut-il vraiment monitorer votre robots.txt en continu ?
- □ Faut-il vraiment tester son robots.txt avant chaque modification ?
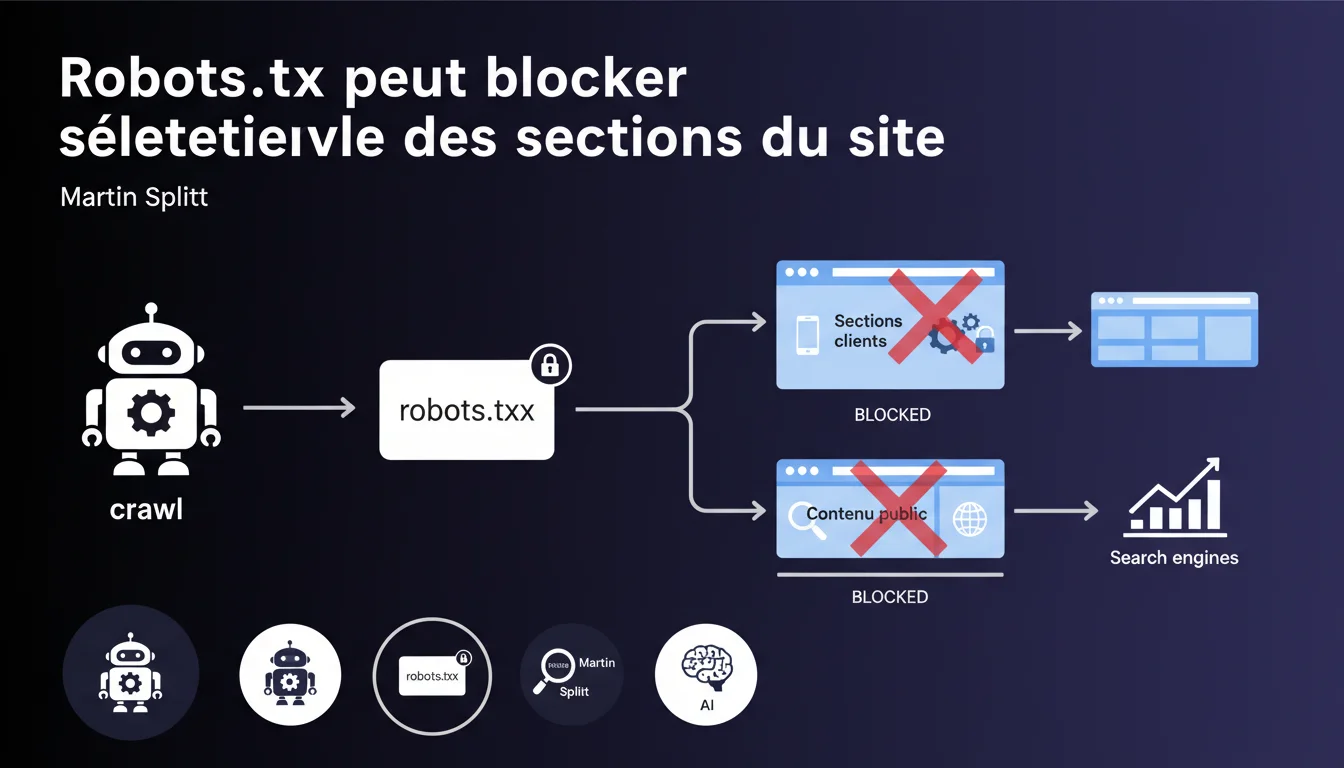
Google recommande officiellement de bloquer via robots.txt certaines parties du site qui consomment du crawl budget sans apporter de valeur SEO : pages de filtres complexes, contenus clients non pertinents pour la recherche. Cette pratique permet d'optimiser l'allocation des ressources de crawl vers les pages stratégiques.
Ce qu'il faut comprendre
Pourquoi Google encourage-t-il ce blocage sélectif ?
Martin Splitt confirme une approche qui va à contre-courant du réflexe "tout laisser accessible". L'idée : concentrer le crawl budget sur ce qui compte vraiment pour votre visibilité organique. Les pages de filtres combinés (couleur + taille + prix, etc.) génèrent souvent des milliers d'URLs redondantes qui diluent l'effort du bot sans créer de valeur SEO.
Le second cas visé — le contenu important pour les clients mais pas pour la recherche — demande plus de discernement. On parle typiquement d'espaces membres, de pages de suivi de commande, de configurateurs propriétaires qui n'ont aucune raison d'apparaître dans les SERP.
Quelle est la différence avec un noindex ?
Le robots.txt bloque le crawl, le noindex bloque l'indexation. Si vous bloquez via robots.txt, Google ne visite même pas la page — donc ne voit pas la balise noindex si elle existe. C'est une économie de ressources serveur et bot, mais ça empêche aussi la découverte de liens internes.
Le noindex, lui, nécessite que Google crawle la page pour lire la directive. Plus coûteux en budget, mais il permet au bot de suivre les liens présents sur la page. Le choix entre les deux n'est pas anodin.
Quels types de pages sont concernés en priorité ?
- Facettes de navigation complexes : filtres combinés, tris multiples, pagination infinie générée dynamiquement
- Pages de recherche interne : résultats de recherche on-site qui créent du contenu dupliqué ou thin
- Espaces authentifiés : zones membres, dashboards clients, paniers abandonnés
- Contenus temporaires : promotions flash, événements passés, landing pages de campagnes expirées
- Ressources techniques : fichiers CSS/JS si déjà consolidés, dossiers admin, APIs internes
Avis d'un expert SEO
Cette recommandation est-elle toujours pertinente en 2025 ?
Oui, mais avec une nuance de taille : Google est devenu bien meilleur pour comprendre les patterns de facettes et ignorer le bruit. Leur système de crawl priorise désormais mieux les URLs à forte valeur ajoutée, même sans blocage explicite.
Cela dit, pour les gros sites (e-commerce 100k+ pages, médias, plateformes), le robots.txt reste un levier de contrôle indispensable. Laisser Google décider seul de ce qu'il crawle, c'est prendre le risque qu'il passe à côté de vos nouvelles pages stratégiques parce qu'il s'est embourbé dans vos filtres.
[À vérifier] La formule "contenu important pour les clients mais pas pour la recherche" reste floue. Google ne donne aucun exemple concret, ce qui laisse une large marge d'interprétation. Un espace membre peut contenir des ressources riches que vous souhaitez indexer pour certaines requêtes spécifiques — bloquer par défaut serait une erreur.
Quels sont les risques d'un blocage trop agressif ?
Le principal danger : couper des chemins de crawl. Si vous bloquez une catégorie de pages qui contient des liens vers d'autres sections stratégiques, vous fragmentez votre maillage interne. Google peut alors mettre plus de temps à découvrir vos nouvelles pages importantes, voire ne jamais les atteindre si elles ne sont accessibles que via ces URLs bloquées.
Deuxième piège : bloquer des pages qui génèrent du trafic de longue traîne sans que vous le sachiez. Une page de filtre mal perçue peut en réalité ranker sur une intention très spécifique. Avant de bloquer massivement, passez vos logs serveur au crible et croisez avec la Search Console.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre site fait moins de 10 000 pages et que votre crawl budget n'est pas un problème (vérifiable en Search Console : fréquence de crawl stable, pas de pages stratégiques ignorées), bloquer des sections entières peut être contre-productif. Vous risquez de sur-optimiser pour un gain marginal.
Les sites d'actualité, eux, ont un besoin inverse : maximiser la fraîcheur du crawl sur toutes les pages. Bloquer des sections ralentirait la découverte de nouveaux contenus. Même logique pour les sites à forte saisonnalité où des URLs "temporaires" doivent être indexées rapidement puis désindexées proprement.
Impact pratique et recommandations
Comment identifier les pages à bloquer en priorité ?
Commencez par croiser trois sources : les logs serveur (pour voir ce que Google crawle réellement), la Search Console (onglet "Couverture" et "Statistiques d'exploration"), et votre analytics (pour repérer les pages à zéro trafic organique mais fort crawl). Les écarts révèlent les zones de gaspillage.
Utilisez un crawler comme Screaming Frog ou Oncrawl pour mapper vos patterns d'URLs. Filtrez par type (facettes, pagination, search interne) et mesurez le volume. Si 40% de votre crawl budget part sur des combinaisons de filtres qui ne rankent sur rien, vous avez votre réponse.
Quelle syntaxe robots.txt adopter pour un blocage propre ?
Soyez chirurgical, pas brutal. Un Disallow: /produits/ tue toute la catégorie. Préférez des patterns précis : Disallow: /*?filtre= cible les URLs avec paramètres de filtres, Disallow: /*?sort= bloque les tris, Disallow: /recherche? neutralise la recherche interne.
Testez systématiquement avec l'outil "Tester le fichier robots.txt" de la Search Console avant de mettre en prod. Une erreur de syntaxe peut bloquer des sections entières par accident. Et documentez chaque règle avec un commentaire — dans six mois, vous aurez oublié pourquoi vous avez bloqué /api/legacy/.
Comment vérifier que le blocage fonctionne sans casser l'indexation stratégique ?
- Auditez vos logs serveur 2 semaines après la mise en place : le crawl des sections bloquées doit chuter à zéro
- Surveillez la Search Console pour détecter toute baisse inhabituelle de pages indexées ou de trafic organique
- Vérifiez que vos pages stratégiques restent accessibles : crawlez votre sitemap XML et confirmez qu'aucune URL critique n'est bloquée par erreur
- Testez manuellement quelques URLs bloquées avec "Inspection d'URL" dans la GSC — elles doivent afficher "Bloquée par le fichier robots.txt"
- Croisez avec Google Analytics : si des pages bloquées génèrent encore du trafic organique 30 jours après, c'est qu'elles étaient déjà indexées et que des backlinks les maintiennent (gérez avec noindex ou redirection)
❓ Questions frequentes
Peut-on bloquer des pages via robots.txt tout en les gardant indexées ?
Le blocage robots.txt améliore-t-il directement le classement des autres pages ?
Faut-il bloquer les paramètres UTM de tracking dans le robots.txt ?
Comment savoir si mon site souffre d'un problème de crawl budget ?
Un blocage robots.txt empêche-t-il le passage de PageRank via les liens internes ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 10/01/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.