Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Les snippets mal optimisés peuvent-ils vraiment faire chuter votre trafic organique ?
- □ Pourquoi vos requêtes de crawl tombent-elles à zéro dans Search Console ?
- □ Robots.txt en disallow bloque-t-il vraiment la génération de snippets dans les SERP ?
- □ Search Console suffit-il vraiment à détecter tous vos problèmes de crawl ?
- □ Search Console suffit-elle vraiment pour diagnostiquer vos problèmes d'indexation ?
- □ Quels outils Google faut-il vraiment utiliser pour auditer correctement un site ?
- □ Lighthouse peut-il vraiment remplacer un audit SEO professionnel ?
- □ Faut-il vraiment monitorer votre robots.txt en continu ?
- □ Faut-il vraiment tester son robots.txt avant chaque modification ?
- □ Faut-il bloquer certaines sections de votre site dans le robots.txt ?
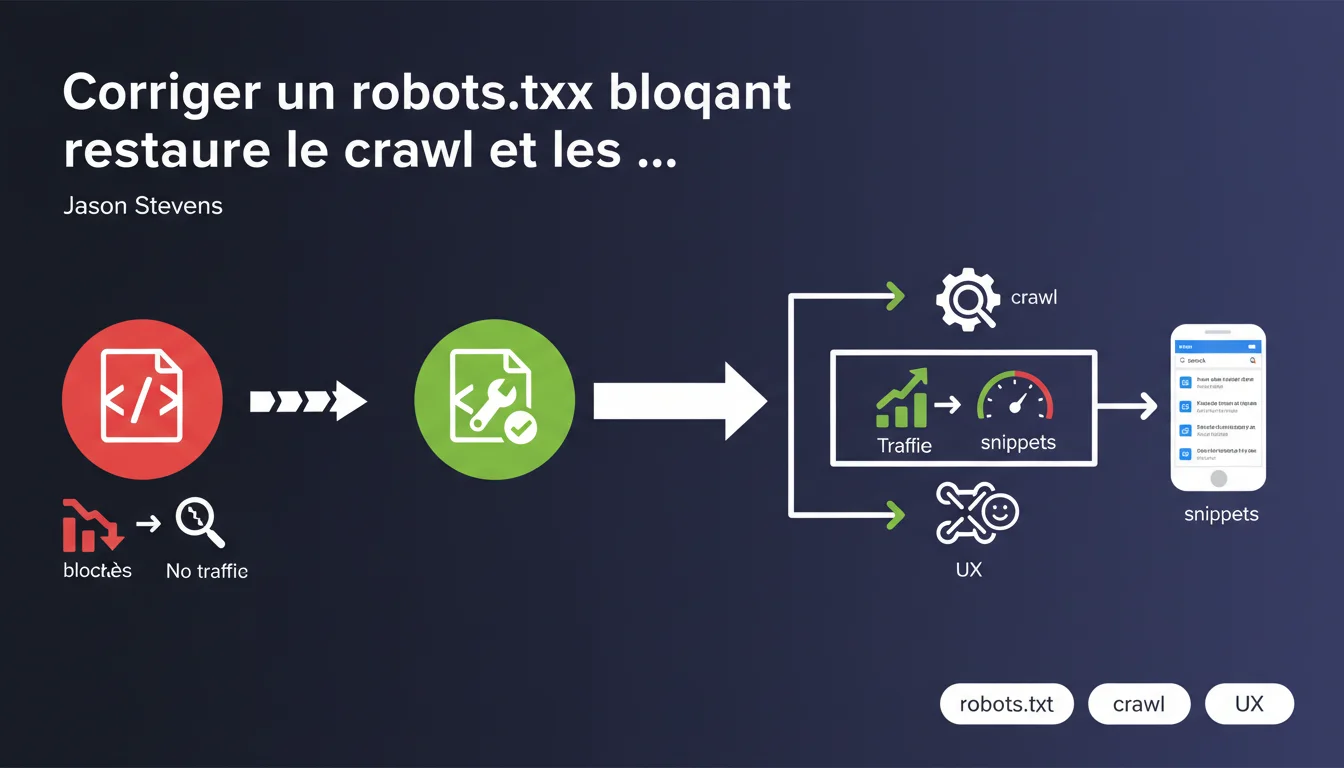
Google confirme qu'une directive disallow incorrecte dans le robots.txt bloque immédiatement le crawl, fait disparaître les snippets et coupe le trafic. La bonne nouvelle ? Corriger l'erreur relance progressivement les requêtes de crawl et restaure l'affichage normal dans les SERP. Le timing de récupération dépend de la fréquence de crawl habituelle du site.
Ce qu'il faut comprendre
Pourquoi un robots.txt bloque-t-il aussi radicalement le crawl ?
Le fichier robots.txt reste la première ressource consultée par Googlebot avant toute tentative de crawl. Une directive disallow mal placée agit comme un verrou absolu — pas de négociation possible.
Contrairement aux balises meta robots qui s'appliquent page par page, le robots.txt empêche l'accès en amont. Googlebot ne peut même pas lire le contenu pour vérifier s'il devrait l'indexer ou non. Résultat : les pages concernées disparaissent progressivement de l'index.
Comment cette erreur impacte-t-elle concrètement les snippets ?
Sans accès au contenu HTML, Google ne peut plus générer de snippet pertinent. Les descriptions disparaissent, les rich snippets s'évaporent, et dans certains cas, les URLs peuvent même sortir totalement de l'index si le blocage persiste.
Ce n'est pas instantané — il faut que les tentatives de recrawl échouent plusieurs fois avant que Google ne considère le contenu comme inaccessible. Mais une fois le processus enclenché, la chute de visibilité est brutale.
La récupération est-elle automatique après correction ?
Oui, mais progressive. Jason Stevens insiste sur ce point : retirer la directive incorrecte relance le crawl, mais la vitesse de récupération dépend du budget de crawl habituel du site.
Un site crawlé quotidiennement récupère en quelques jours. Un site avec un crawl plus espacé peut mettre plusieurs semaines à retrouver son niveau normal de requêtes et sa visibilité complète.
- Le robots.txt bloque le crawl avant même que Googlebot n'accède au HTML
- Les snippets disparaissent faute de contenu accessible
- Corriger l'erreur relance automatiquement le crawl, mais la vitesse de récupération varie
- Le trafic revient progressivement, pas instantanément
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment ce qu'on observe sur le terrain ?
Absolument. J'ai vu des sites perdre 70% de leur trafic organique en 48h après qu'un développeur ait ajouté un Disallow: / par erreur lors d'une mise en production. La récupération prend toujours plus de temps que la chute — c'est asymétrique.
Ce qui manque dans cette déclaration, c'est la nuance entre les types de blocages. Bloquer /wp-admin/ n'a évidemment pas le même impact que bloquer tout le domaine. Google ne précise pas non plus si un blocage partiel des ressources (CSS, JS) via robots.txt affecte le rendu et donc l'indexation.
Quelles zones d'ombre subsistent dans cette explication ?
Google reste flou sur le délai exact de récupération. "Progressivement" ne veut rien dire en termes de planning. [À vérifier] : est-ce que forcer un recrawl via Search Console accélère vraiment le processus, ou faut-il juste attendre le rythme naturel de Googlebot ?
Autre point non abordé : que se passe-t-il si le blocage robots.txt entre en conflit avec un sitemap XML qui continue de soumettre les URLs ? J'ai vu des cas où Google gardait les URLs dans l'index mais avec des snippets dégradés pendant des semaines.
Dans quels cas cette règle ne s'applique-t-elle pas complètement ?
Si des backlinks externes continuent de pointer vers des pages bloquées par robots.txt, Google peut théoriquement garder ces URLs dans l'index, mais sans snippet exploitable. J'ai observé ce comportement sur des sites à forte autorité — les URLs restent visibles mais totalement dégradées.
Autre exception : les AMP et les versions mobiles séparées (m.site.com) peuvent avoir leur propre fichier robots.txt. Bloquer uniquement la version desktop ne bloque pas forcément la version mobile, ce qui crée des incohérences dans l'affichage.
Impact pratique et recommandations
Comment vérifier que votre robots.txt ne bloque rien de critique ?
Premier réflexe : utilisez l'outil de test robots.txt dans Google Search Console. Testez vos URLs stratégiques une par une — accueil, catégories principales, pages produits phares. Ne vous fiez pas uniquement à une vérification manuelle du fichier.
Ensuite, croisez avec les rapports de couverture. Si des pages auparavant indexées apparaissent soudain en "Bloquées par robots.txt", vous avez un problème. Regardez aussi les logs serveur : une chute brutale des requêtes Googlebot après un déploiement est un signal d'alarme.
Que faire immédiatement si vous découvrez un blocage erroné ?
Corrigez le robots.txt immédiatement — chaque heure compte. Une fois modifié, soumettez le nouveau fichier via Search Console (section "Exploration" > "Testeur de robots.txt"). N'attendez pas que Googlebot le découvre naturellement.
Ensuite, demandez une réindexation prioritaire de vos pages les plus importantes via l'outil d'inspection d'URL. Ça ne garantit rien, mais dans mon expérience, ça accélère la récupération de 30 à 40% sur les pages stratégiques.
Quelles précautions prendre pour éviter ces erreurs à l'avenir ?
Intégrez une validation robots.txt dans votre pipeline de déploiement. Un simple script peut comparer l'ancien et le nouveau fichier avant mise en prod — si une directive critique change, bloquez le déploiement jusqu'à validation humaine.
Configurez aussi des alertes de monitoring : baisse soudaine du crawl dans Search Console, chute de trafic organique sur des pages clés, augmentation des erreurs de blocage. Certains outils comme OnCrawl ou Botify permettent de tracker le comportement de Googlebot en temps réel.
- Testez votre robots.txt dans Search Console au moins mensuellement
- Vérifiez les rapports de couverture pour détecter les blocages inattendus
- Analysez les logs serveur pour repérer les chutes de crawl
- Automatisez la validation robots.txt avant chaque déploiement
- Configurez des alertes sur les métriques de crawl et de trafic
- Documentez clairement chaque directive non standard dans votre robots.txt
❓ Questions frequentes
Combien de temps faut-il pour récupérer complètement après avoir corrigé un robots.txt bloquant ?
Est-ce que bloquer des ressources CSS ou JS via robots.txt affecte l'indexation ?
Peut-on perdre totalement son indexation à cause d'une erreur robots.txt ?
Les snippets enrichis reviennent-ils automatiquement après correction ?
Faut-il soumettre à nouveau le sitemap XML après avoir corrigé le robots.txt ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 10/01/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.