Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Les snippets mal optimisés peuvent-ils vraiment faire chuter votre trafic organique ?
- □ Pourquoi vos requêtes de crawl tombent-elles à zéro dans Search Console ?
- □ Robots.txt en disallow bloque-t-il vraiment la génération de snippets dans les SERP ?
- □ Search Console suffit-il vraiment à détecter tous vos problèmes de crawl ?
- □ Quels outils Google faut-il vraiment utiliser pour auditer correctement un site ?
- □ Lighthouse peut-il vraiment remplacer un audit SEO professionnel ?
- □ Un robots.txt mal configuré peut-il vraiment bloquer vos snippets et votre crawl ?
- □ Faut-il vraiment monitorer votre robots.txt en continu ?
- □ Faut-il vraiment tester son robots.txt avant chaque modification ?
- □ Faut-il bloquer certaines sections de votre site dans le robots.txt ?
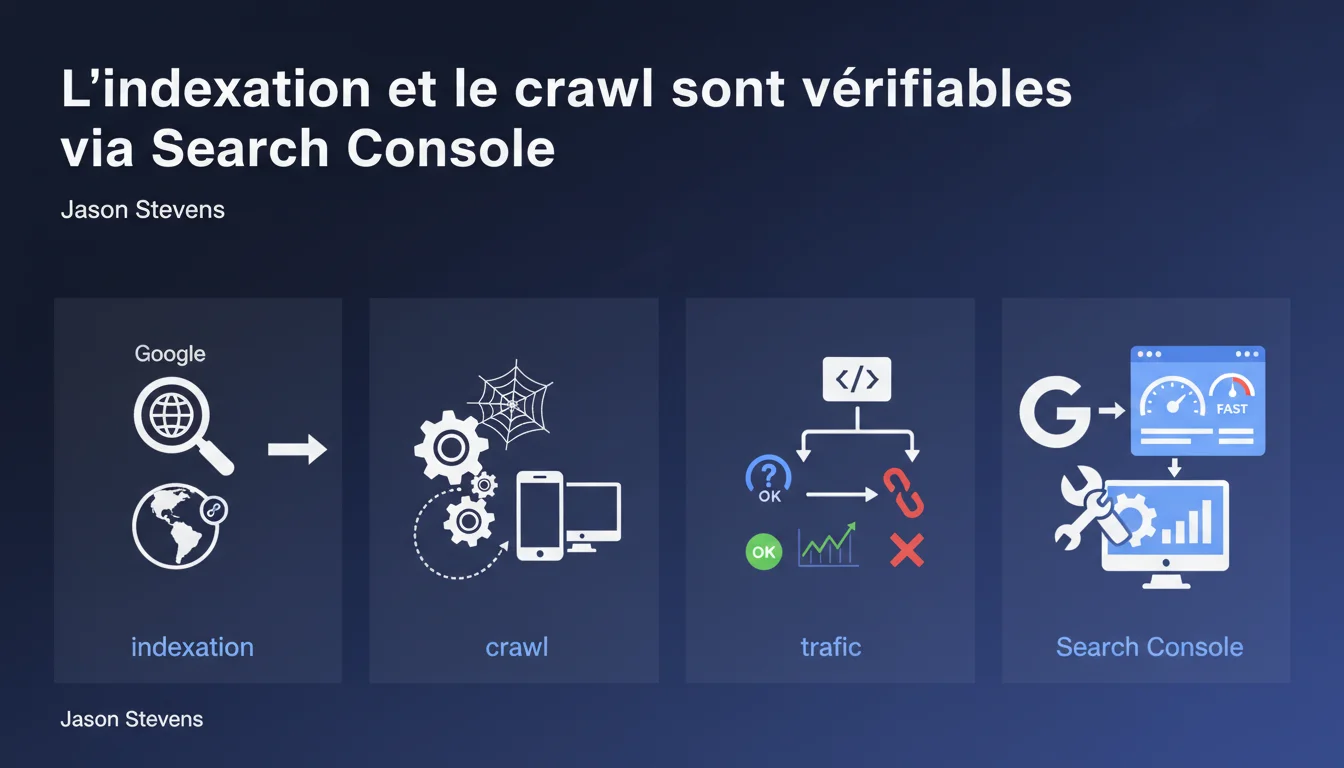
Google recommande d'utiliser Search Console pour vérifier l'indexation et le crawl avant de diagnostiquer un problème de trafic. La plateforme permet de s'assurer que Google accède aux bonnes pages, détecte les nouveautés et ne se perd pas dans l'architecture du site. Reste à savoir si ces données sont toujours fiables et complètes.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur Search Console pour diagnostiquer les baisses de trafic ?
Quand le trafic chute, le réflexe est souvent d'accuser un algorithme ou une pénalité. Google rappelle ici la base : vérifier l'indexation et le crawl avant tout. Si vos pages ne sont pas indexées ou si Googlebot ne passe pas là où il devrait, inutile de chercher plus loin.
Search Console devient l'outil de première ligne. Les rapports de couverture, les logs de crawl, les statistiques d'exploration — tout y est, en théorie. Le message est clair : commencez par les fondamentaux.
Que signifie « Google se perd pendant le crawl » concrètement ?
Un site mal structuré, des redirections en cascade, des loops, du contenu orphelin — Googlebot peut effectivement gaspiller son budget de crawl sur des zones sans valeur. Stevens évoque ce risque sans donner de seuil précis.
L'idée : si Google passe 80% de son temps sur des pages inutiles (filtres, paramètres d'URL, paginations infinies), il ne reste plus grand-chose pour crawler vos contenus stratégiques. D'où l'importance de piloter le crawl via robots.txt, canoniques et maillage interne propre.
Search Console donne-t-elle toujours une image fidèle du crawl ?
Là, ça coince. Search Console agrège des données, mais elle ne montre pas tout. Les logs serveur restent la seule source exhaustive : qui crawle quoi, à quelle fréquence, avec quel user-agent exact.
- Limites de Search Console : données échantillonnées, délais de remontée, absence de détails fins sur les bots tiers ou les passages Googlebot non indexants
- Crawl vs indexation : une page crawlée n'est pas forcément indexée — la distinction est cruciale
- Détection des nouveautés : Google promet de repérer ce qui est neuf, mais combien de temps après publication ? Aucun SLA donné
- Architecture et budget de crawl : plus le site est gros, plus le risque de perte est réel
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Globalement, oui. Search Console est devenue la référence officielle pour diagnostiquer indexation et crawl. Les données sont souvent alignées avec ce qu'on trouve dans les logs — à condition de croiser les sources.
Mais voilà le problème : Stevens présente Search Console comme suffisante, alors qu'elle ne l'est pas toujours. Sur un site de plusieurs millions de pages, les rapports peuvent être trop agrégés pour identifier des problèmes fins. [A vérifier] : Google affirme que l'outil détecte tout ce qui est « nouveau », mais sans préciser le délai ni la méthode exacte.
Quelles nuances faut-il apporter sur le budget de crawl ?
Google répète que le budget de crawl n'est un problème que pour les « très gros sites ». Sauf qu'en pratique, on voit des sites de taille moyenne — 50k à 100k pages — où Googlebot passe à côté de contenus stratégiques parce qu'il s'enlise dans des facettes, des filtres ou des archives.
Le conseil de vérifier « si Google ne se perd pas » est bon, mais comment le vérifier concrètement ? Search Console ne dit pas explicitement « vous avez un problème de budget de crawl ». Il faut analyser les patterns de crawl, comparer avec les logs, regarder la fréquence de passage sur les URLs prioritaires.
Faut-il se contenter de Search Console ou aller plus loin ?
Soyons honnêtes : Search Console, c'est le minimum syndical. Pour un diagnostic sérieux, il faut aussi :
- Logs serveur : seule source de vérité exhaustive
- Outils de crawl tiers (Screaming Frog, OnCrawl, Botify) pour simuler le comportement de Googlebot
- Monitoring en continu : détecter les anomalies avant qu'elles impactent le trafic
Google ne le dira jamais, mais Search Console seule ne suffit pas sur des sites complexes. C'est un point de départ, pas une fin en soi.
Impact pratique et recommandations
Que faut-il vérifier en priorité dans Search Console après cette déclaration ?
Commencez par les rapports de couverture d'indexation. Pages valides, pages exclues, erreurs — tout doit être passé au crible. Si des pages stratégiques sont marquées « Détectée, actuellement non indexée », il y a un problème de crawl ou de qualité perçue.
Ensuite, direction les statistiques d'exploration : nombre de requêtes par jour, temps de téléchargement moyen, erreurs d'exploration. Une baisse brutale du crawl peut signaler un problème technique (serveur lent, timeout, robots.txt mal configuré).
Quelles erreurs éviter pour ne pas perdre Google dans votre site ?
Le piège classique : laisser Google crawler des zones inutiles. Facettes de filtres, paramètres d'URL infinis, paginations mal gérées, contenus dupliqués — autant de ressources gaspillées.
- Vérifier que les URLs prioritaires sont bien crawlées régulièrement (via logs serveur)
- Bloquer les zones non stratégiques via robots.txt ou noindex
- Optimiser le maillage interne pour pousser le crawl vers les contenus prioritaires
- Réduire la profondeur de clic : toute page stratégique doit être accessible en 3 clics max depuis la home
- Nettoyer les redirections en cascade et les chaînes de redirections
- Surveiller les erreurs 4xx/5xx qui bloquent l'accès de Googlebot
Comment s'assurer que Google détecte bien vos nouveaux contenus ?
Google promet de repérer ce qui est neuf, mais combien de temps ça prend ? Ça dépend de votre fréquence de crawl habituelle, de votre autorité, de votre architecture.
Pour accélérer, utilisez l'API Indexing (limitée aux offres d'emploi et contenus en livestream pour l'instant), ou a minima le rapport d'inspection d'URL pour demander une indexation manuelle. Mais sur un gros volume, c'est ingérable.
La déclaration de Stevens est un rappel salutaire : l'indexation et le crawl sont la base de tout. Avant de chercher des explications ésotériques à une baisse de trafic, vérifiez que Google accède bien à vos pages et ne perd pas de temps sur des zones inutiles.
Search Console est un bon point de départ, mais sur des sites complexes ou de forte volumétrie, elle ne suffit pas. Les logs serveur, le monitoring continu et une analyse fine de l'architecture sont indispensables. Ces diagnostics techniques demandent une expertise pointue — si vous constatez des anomalies difficiles à interpréter ou si votre architecture nécessite une refonte en profondeur, faire appel à une agence SEO spécialisée peut vous faire gagner un temps précieux et éviter des erreurs coûteuses.
❓ Questions frequentes
Search Console remplace-t-elle les logs serveur pour analyser le crawl ?
Comment savoir si Google « se perd » dans mon site ?
Le budget de crawl est-il vraiment un problème seulement pour les gros sites ?
Peut-on forcer Google à indexer une nouvelle page rapidement ?
Que faire si des pages stratégiques sont marquées 'Détectée, actuellement non indexée' ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 10/01/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.