Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Pourquoi Google refuse-t-il désormais certaines directives dans le robots.txt ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi Google extrait-il les balises meta robots et canonical pendant l'indexation plutôt qu'au crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
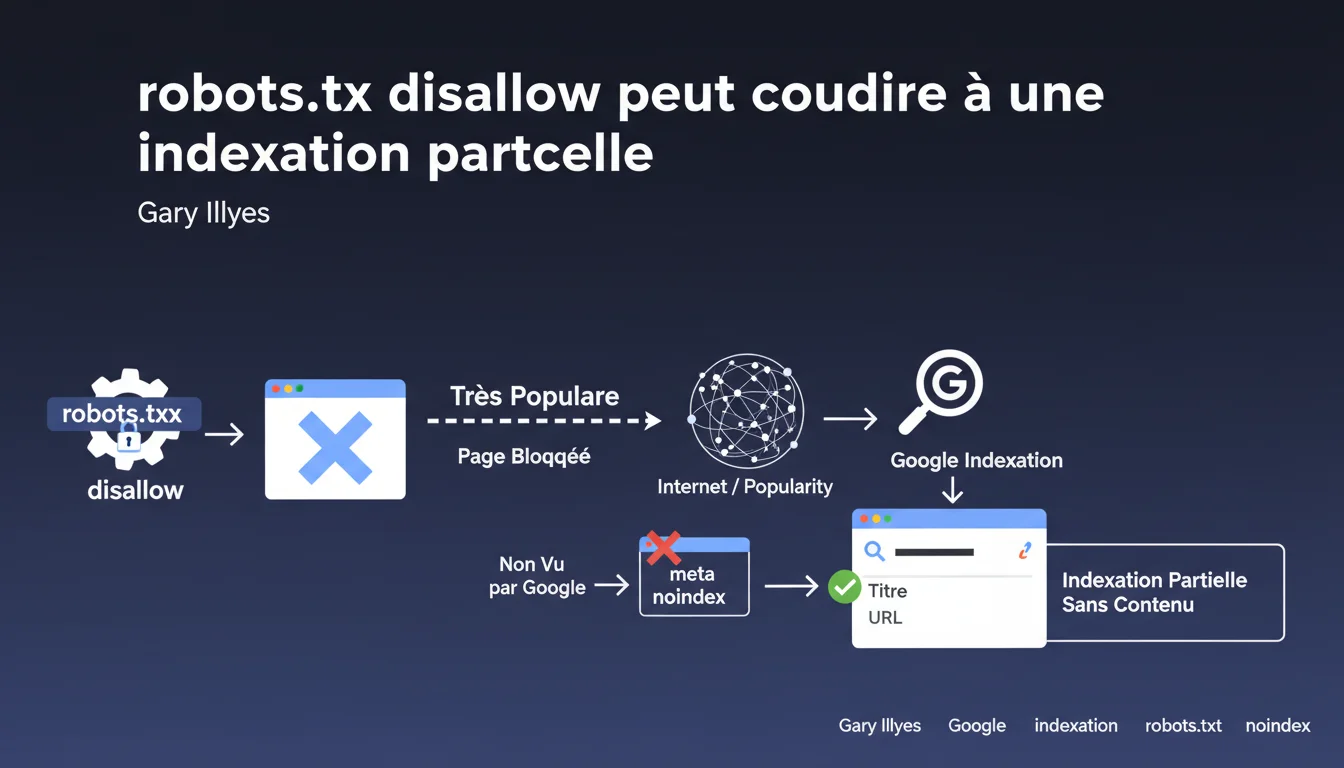
Google peut indexer l'URL d'une page bloquée par robots.txt si elle est très populaire sur le web, mais sans son contenu ni snippet. Le problème : votre balise meta noindex ne sera jamais lue à cause du blocage robots.txt, vous laissant sans contrôle réel sur cette indexation partielle.
Ce qu'il faut comprendre
Comment Google peut-il indexer une page qu'il ne crawle pas ?
C'est le paradoxe qui déroute beaucoup de professionnels SEO. Quand vous bloquez une URL via robots.txt disallow, vous interdisez à Googlebot de crawler la page. Logiquement, pas de crawl = pas d'indexation.
Sauf que Google ne fonctionne pas uniquement sur du crawl. Si une page accumule suffisamment de signaux de popularité externes — backlinks, mentions sur les réseaux sociaux, partages — Google peut décider d'indexer l'URL seule. Pas le contenu, juste l'adresse. Le résultat dans les SERP affichera l'URL et éventuellement un titre reconstruit, mais aucun snippet.
Pourquoi la balise meta noindex ne fonctionne-t-elle pas dans ce cas ?
Pour qu'une balise meta noindex soit prise en compte, Google doit crawler la page et lire son code HTML. Si robots.txt bloque l'accès, Googlebot ne peut jamais atteindre cette balise.
C'est un conflit de directives : vous interdisez le crawl tout en espérant que Google respecte une instruction qu'il ne peut physiquement pas voir. Dans cette configuration, robots.txt l'emporte — mais de manière contre-intuitive, puisque la page peut quand même apparaître dans l'index.
Quels sont les signaux de popularité qui déclenchent cette indexation ?
Google ne donne pas de seuil précis, mais on parle de pages qui reçoivent des backlinks de qualité, des mentions fréquentes dans des contenus tiers, ou un volume important de partages. Pensez à des PDF sensibles, des documents internes qui fuient, ou des pages de staging qui se retrouvent linkées par erreur.
L'indexation partielle n'est pas systématique. Elle intervient quand Google juge que l'URL a une pertinence suffisante pour les utilisateurs, malgré l'absence d'accès au contenu.
- robots.txt disallow bloque le crawl, pas nécessairement l'indexation
- Une URL très populaire peut être indexée sans son contenu ni snippet
- La balise meta noindex ne sera jamais lue si robots.txt bloque l'accès
- Seuls des signaux externes (backlinks, mentions) déclenchent cette indexation partielle
- Le résultat affiché sera une URL nue, parfois avec un titre reconstitué
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même un classique des audits SEO mal ficelés. On voit régulièrement des sites qui bloquent par robots.txt des sections entières — /admin/, /test/, /staging/ — et qui se retrouvent quand même avec ces URLs dans l'index. Souvent découvert par hasard via un site: commande.
Le problème, c'est que cette indexation partielle passe inaperçue jusqu'à ce qu'elle pose un souci de réputation ou de duplicate content fantôme. Une URL de staging indexée sans snippet, c'est discret — mais ça peut aussi pointer vers des contenus sensibles ou non finalisés.
Pourquoi Google ne bloque-t-il pas complètement l'indexation dans ce cas ?
Parce que robots.txt n'a jamais été conçu pour gérer l'indexation, uniquement le crawl. C'est un protocole des années 90 qui sert à économiser la bande passante, pas à contrôler la visibilité dans les SERP.
Google a toujours maintenu cette position : si vous voulez empêcher l'indexation, utilisez meta noindex ou X-Robots-Tag. Mais la nuance ici, c'est que ces directives nécessitent un crawl pour être lues. [À vérifier] : Google ne fournit aucune donnée sur le seuil de popularité déclenchant cette indexation partielle, ni sur la fréquence de ce phénomène.
Existe-t-il des exceptions ou des cas limites ?
Oui. Une URL sans aucun backlink ni mention externe a peu de chances d'être indexée, même si elle est techniquement accessible. À l'inverse, une page bloquée par robots.txt mais massivement relayée sur Reddit ou Hacker News peut se retrouver indexée en quelques heures.
Autre nuance : si vous débloquez temporairement une URL via robots.txt pour que Google lise votre meta noindex, puis la rebloquez, vous créez une fenêtre de crawl opportuniste. Google peut indexer le contenu pendant ce laps de temps, surtout si la page change de statut fréquemment.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter cette indexation partielle ?
D'abord, ne jamais compter uniquement sur robots.txt pour gérer l'indexation. Si une page doit rester hors de l'index, la stratégie recommandée est de la laisser crawlable mais d'y ajouter une balise meta noindex ou un header X-Robots-Tag: noindex.
Pour les contenus vraiment sensibles — données internes, pages de staging, environnements de test — utilisez une authentification HTTP (login/password au niveau serveur) ou une restriction par IP whitelisting. Aucun signal externe ne peut forcer l'indexation d'une page inaccessible.
Comment détecter si votre site souffre déjà de ce problème ?
Lancez une recherche site:votredomaine.com dans Google et scrutez les résultats. Les URLs indexées sans snippet, avec juste un titre générique ou l'URL brute, sont suspectes. Croisez ensuite avec votre robots.txt pour identifier les pages bloquées au crawl mais indexées quand même.
Utilisez aussi Google Search Console : section "Pages" > "Pourquoi les pages ne sont pas indexées" > "Bloquées par robots.txt". Si certaines de ces URLs apparaissent malgré tout dans l'index, vous êtes en plein dans le cas décrit par Gary Illyes.
Quelles erreurs éviter absolument ?
Ne bloquez pas par robots.txt une page que vous voulez désindexer via meta noindex. C'est une erreur courante : on pense sécuriser doublement, mais en réalité on annule l'effet de noindex. Google ne peut pas lire une directive qu'il n'a jamais crawlée.
Autre piège : débloquer temporairement robots.txt pour "laisser passer" le noindex, puis rebloquer. Timing hasardeux, et vous risquez de créer des fluctuations d'indexation imprévisibles. Mieux vaut choisir une stratégie stable.
- Autoriser le crawl des pages avec meta noindex plutôt que de les bloquer par robots.txt
- Utiliser l'authentification HTTP ou IP whitelisting pour les contenus vraiment sensibles
- Auditer régulièrement les URLs indexées via site: commande et Search Console
- Croiser les données robots.txt avec l'état d'indexation réel pour détecter les incohérences
- Ne jamais combiner robots.txt disallow et meta noindex sur une même URL
- Surveiller les backlinks entrants vers des pages sensibles via des outils comme Ahrefs ou Majestic
❓ Questions frequentes
Peut-on forcer la désindexation d'une URL bloquée par robots.txt ?
Combien de backlinks faut-il pour déclencher cette indexation partielle ?
Robots.txt disallow protège-t-il contre le scraping ou la copie de contenu ?
Si je débloque robots.txt pour ajouter noindex, combien de temps avant que Google crawle la page ?
Une URL indexée sans snippet a-t-elle un impact SEO négatif ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.