Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Pourquoi Google refuse-t-il désormais certaines directives dans le robots.txt ?
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi Google extrait-il les balises meta robots et canonical pendant l'indexation plutôt qu'au crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
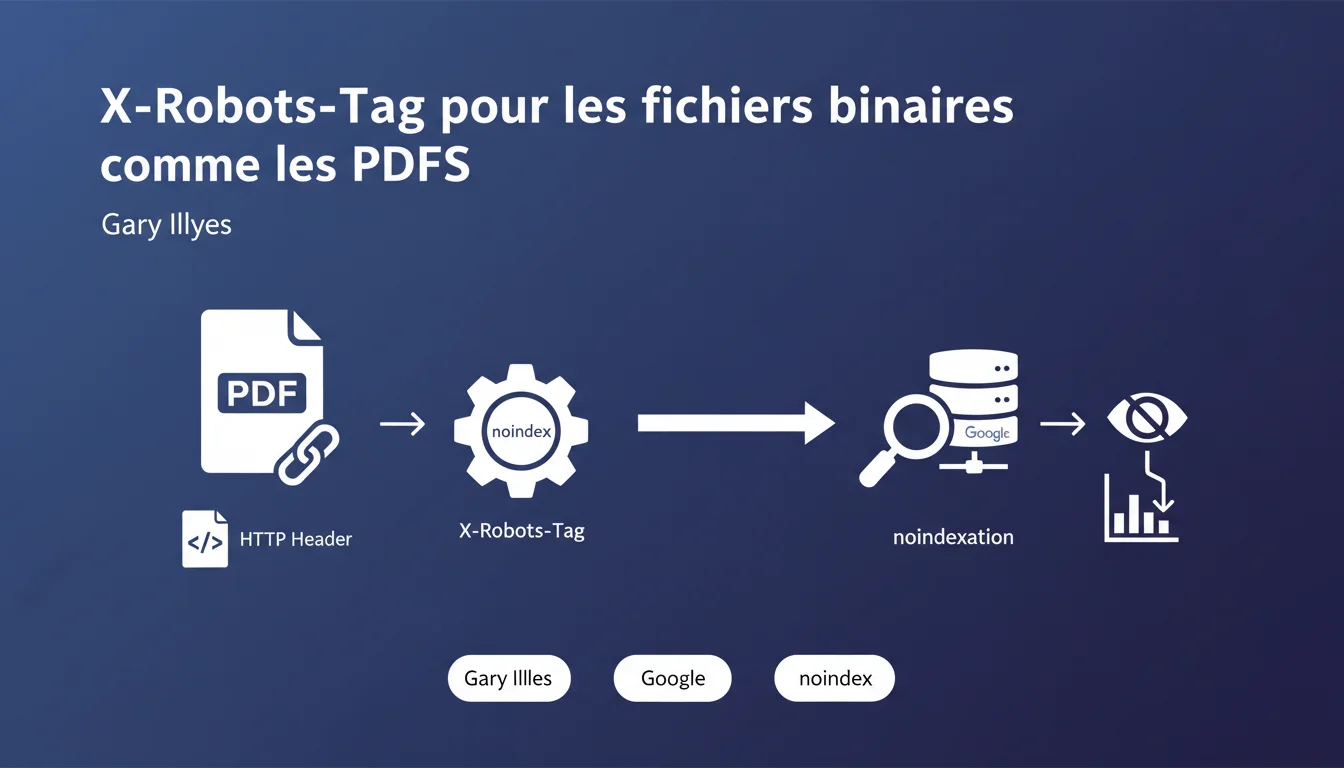
Google accepte l'en-tête HTTP x-robots-tag avec la directive noindex pour bloquer l'indexation des fichiers binaires comme les PDFs, où une balise meta HTML classique ne peut pas être insérée. Cet en-tête fonctionne exactement comme une meta robots noindex et sera respecté lors de la phase d'indexation.
Ce qu'il faut comprendre
Pourquoi cette précision technique est-elle nécessaire ?
Les fichiers binaires — PDFs, images, documents Office — ne sont pas du HTML. Impossible d'y insérer une balise meta robots classique dans le <head>. Pourtant, Google peut les indexer et les faire apparaître dans les résultats de recherche.
L'en-tête HTTP X-Robots-Tag répond à ce problème. Il se configure au niveau serveur, dans la réponse HTTP, pas dans le contenu du fichier. Ça fonctionne exactement comme une meta robots, mais sans dépendre du format du document.
Dans quels cas concrets utiliser cet en-tête ?
Typique : vous avez des PDFs internes, des rapports confidentiels, des documents de travail que vous ne voulez pas voir remonter dans les SERP. Ou encore des fiches produits obsolètes au format PDF que vous devez conserver en ligne mais désindexer.
Autre cas fréquent : les images. Si vous hébergez des photos sous embargo ou des visuels de clients que vous ne souhaitez pas exposer publiquement via Google Images, X-Robots-Tag avec noindex fait le job.
Quelle différence avec un robots.txt ou un 404 ?
Le robots.txt bloque le crawl, pas l'indexation. Google peut indexer une URL même sans l'avoir crawlée si elle reçoit des liens. Le X-Robots-Tag, lui, laisse Googlebot accéder au fichier mais interdit son indexation.
Un 404 ou une suppression pure ? Ça marche, mais vous perdez la ressource. Avec X-Robots-Tag noindex, le fichier reste accessible aux utilisateurs qui ont le lien direct, mais disparaît de l'index Google.
- X-Robots-Tag s'applique à tous types de fichiers : PDFs, images, vidéos, documents Office
- Syntaxe HTTP :
X-Robots-Tag: noindexdans l'en-tête de réponse - Fonctionne comme une meta robots HTML, mais au niveau serveur
- Google traite cette directive lors de l'indexation, pas du crawl
- Compatible avec d'autres directives :
nofollow,nosnippet,noarchive
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Oui, et c'est documenté depuis des années dans la Search Central. Le X-Robots-Tag fonctionne tel qu'annoncé — les tests terrain le confirment. Quand on configure correctement l'en-tête, les PDFs disparaissent de l'index en quelques semaines.
Le timing compte : Google doit recrawler le fichier pour voir l'en-tête. Si le PDF n'est jamais recrawlé, il reste indexé indéfinablement. Pas de magie instantanée.
Quelles nuances faut-il apporter à cette déclaration ?
Gary Illyes parle d'« indexation », mais il faut comprendre que l'en-tête est interprété lors du crawl. Si Googlebot ne revient jamais sur votre PDF, la directive ne sera jamais lue. [À vérifier] : aucune indication de Google sur la fréquence de recrawl des fichiers binaires peu populaires.
Deuxième point — la configuration serveur. Apache, Nginx, IIS : chacun a sa syntaxe. Une erreur de config et l'en-tête n'est jamais envoyé. Les logs serveur ne mentent pas, mais combien de sites vérifient réellement les headers HTTP sur leurs PDFs ?
Dans quels cas cette technique échoue-t-elle ?
Cas classique : vous ajoutez l'en-tête, mais le fichier est servi via un CDN qui ne respecte pas vos headers custom. Résultat : Googlebot voit le PDF sans directive noindex.
Autre piège : certains CMS ou gestionnaires de fichiers écrasent les en-têtes HTTP configurés manuellement. Si vous passez par un plugin ou un module, vérifiez qu'il respecte bien vos directives.
Impact pratique et recommandations
Que faut-il faire concrètement pour désindexer un PDF ?
Première étape : configurer l'en-tête HTTP au niveau serveur. Sur Apache, ça passe par le .htaccess ou la config du vhost. Sur Nginx, directement dans le bloc location. Sur IIS, via web.config ou les custom headers.
Syntaxe Apache typique :
<FilesMatch "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>Une fois en place, vérifiez avec curl -I ou les DevTools Chrome que l'en-tête apparaît bien dans la réponse HTTP. Pas de header visible = configuration ratée.
Comment vérifier que Google a bien pris en compte la directive ?
Utilisez la Search Console : faites un test d'URL en direct sur votre PDF. Google affichera les en-têtes HTTP récupérés. Si X-Robots-Tag apparaît, c'est bon.
Ensuite, patience. Google doit recrawler le fichier. Vous pouvez forcer un recrawl via « Demander une indexation », mais pour un PDF déjà indexé avec beaucoup de liens, ça peut prendre plusieurs semaines avant disparition totale de l'index.
Surveillez avec site:votredomaine.com filetype:pdf dans Google. Quand le PDF ne remonte plus, c'est validé.
Quelles erreurs éviter lors de la mise en place ?
Ne confondez pas X-Robots-Tag et robots.txt. Bloquer le crawl d'un PDF dans robots.txt empêche Google de voir l'en-tête noindex — mauvaise idée si l'URL est déjà indexée.
Autre erreur : appliquer noindex sur tous vos PDFs par défaut. Certains documents ont une vraie valeur SEO — guides, white papers, études de cas. Soyez sélectif.
- Configurer l'en-tête
X-Robots-Tag: noindexau niveau serveur pour les fichiers ciblés - Vérifier la présence de l'en-tête avec
curl -Iou DevTools - Tester l'URL dans Search Console pour confirmer que Google voit l'en-tête
- Demander une réindexation si le fichier est déjà dans l'index
- Surveiller la disparition progressive via
site:domaine.com filetype:pdf - Ne pas bloquer le crawl dans robots.txt si le fichier doit être désindexé
- Documenter quels PDFs sont noindexés et pourquoi — évite les mauvaises surprises
❓ Questions frequentes
L'en-tête X-Robots-Tag fonctionne-t-il aussi pour les images et les vidéos ?
Peut-on combiner X-Robots-Tag avec d'autres directives comme nofollow ou noarchive ?
Si je configure X-Robots-Tag après que le PDF soit déjà indexé, combien de temps avant qu'il disparaisse ?
Est-ce que X-Robots-Tag empêche l'exploration des liens contenus dans un PDF ?
Faut-il supprimer les PDFs de mon sitemap XML si je les noindex avec X-Robots-Tag ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.