Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Pourquoi Google refuse-t-il désormais certaines directives dans le robots.txt ?
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
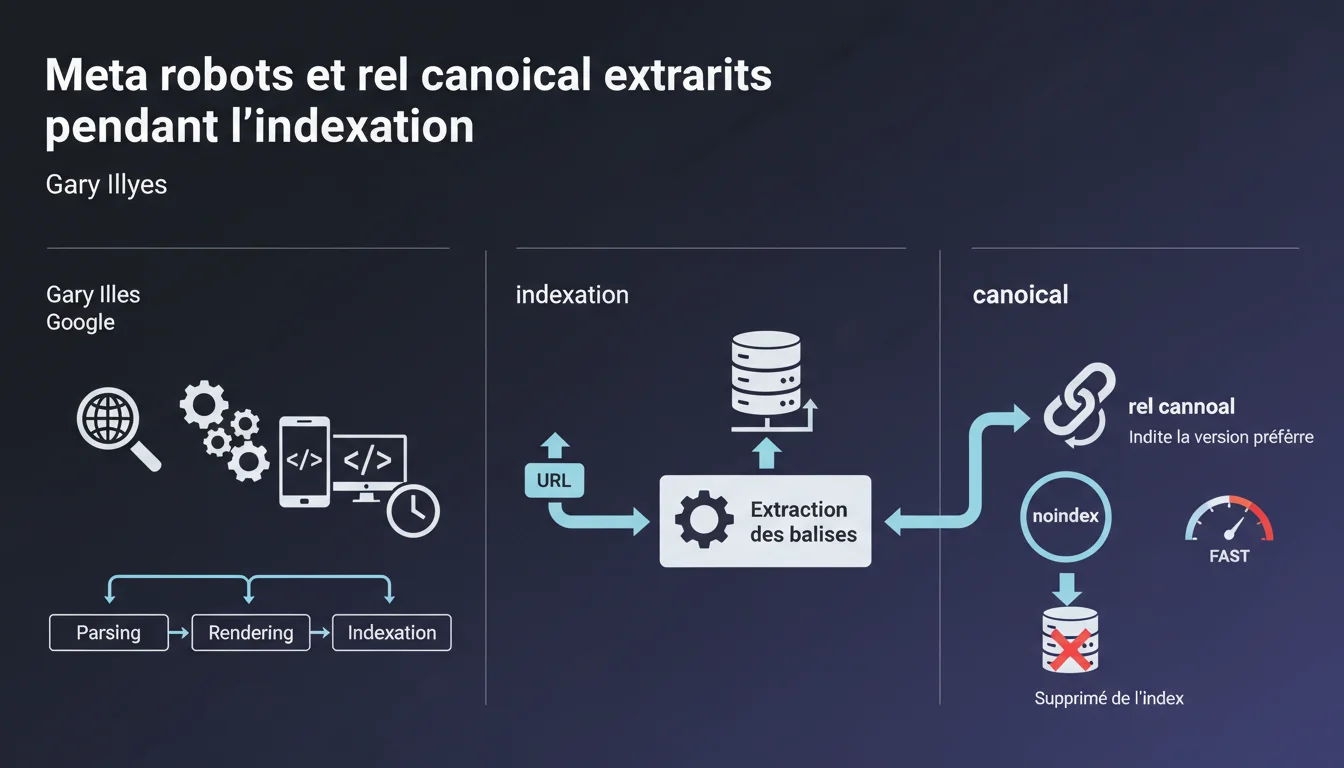
Google extrait les balises meta robots noindex et rel canonical pendant la phase d'indexation, pas au moment du crawl. Ces directives sont lues lors du parsing et du rendering du contenu. Concrètement : une page peut être crawlée plusieurs fois avant que Google ne détecte et applique un noindex.
Ce qu'il faut comprendre
Quelle est la différence entre crawl et indexation dans ce contexte ?
Le crawl est la simple récupération du code HTML par Googlebot. L'indexation intervient ensuite : c'est à ce moment que Google parse le contenu, exécute le JavaScript si nécessaire, et analyse les balises.
Cette distinction explique pourquoi une page avec un meta robots noindex peut apparaître temporairement dans la Search Console comme "Crawled - currently not indexed". Le bot l'a visitée, mais n'a pas encore traité les directives d'indexation.
Que se passe-t-il concrètement avec un noindex ?
Si Google détecte meta robots noindex pendant l'indexation, l'URL sera retirée de l'index. Mais attention : ce retrait n'est pas instantané.
Entre le crawl et le traitement complet, un délai existe. Sur des sites à faible crawl budget, ce délai peut être long. C'est là que ça coince pour les migrations ou les corrections urgentes.
Le rendering joue-t-il un rôle ici ?
Oui, et c'est crucial. Si votre noindex est injecté en JavaScript, Google doit d'abord effectuer le rendering pour le détecter.
Cela ajoute une couche de complexité et de délai. Le rendering n'intervient pas systématiquement au premier crawl — parfois bien après, surtout sur les sites avec un faible budget crawl ou des ressources bloquées.
- Les balises meta robots et canonical sont lues pendant l'indexation, pas au crawl initial
- Un délai existe entre crawl et application effective d'un noindex
- Le rendering JavaScript peut retarder encore la détection de ces balises
- Une URL peut être crawlée plusieurs fois avant d'être désindexée suite à un noindex
Avis d'un expert SEO
Cette déclaration correspond-elle aux observations terrain ?
Oui, largement. On observe régulièrement des pages avec noindex qui restent visibles dans la Search Console pendant des jours, voire des semaines, marquées comme "Discovered - currently not indexed" ou "Crawled - currently not indexed".
Gary Illyes confirme ici ce qu'on constate : Google ne traite pas les directives meta robots instantanément. Le crawl et l'indexation sont deux processus distincts, avec un pipeline qui peut être long.
Quelles zones d'ombre subsistent ?
La déclaration reste vague sur les délais réels. Combien de temps entre le crawl et le parsing complet ? Ça dépend de quoi exactement — crawl budget, priorité de l'URL, charge serveur de Google ?
[À vérifier] : Google ne précise pas si certaines balises sont prioritaires sur d'autres. Par exemple, un noindex injecté en JavaScript sera-t-il traité avec la même célérité qu'un noindex en HTML statique ? Les observations suggèrent que non, mais Google ne le dit pas explicitement.
Autre point trouble : que se passe-t-il si une page oscille entre noindex et index (erreur de déploiement, A/B test mal configuré) ? Google garde-t-il une "mémoire" de l'état précédent ou réinitialise-t-il à chaque crawl ?
Le cas du canonical mérite-t-il une attention particulière ?
Absolument. Google parle de rel canonical comme d'une directive extraite pendant l'indexation, mais rappelons que le canonical reste un signal, pas une directive absolue.
Contrairement au noindex qui est impératif, Google peut choisir d'ignorer un canonical s'il détecte des incohérences (canonical cross-domain suspect, canonical vers une 404, canonical en boucle). Cette déclaration ne dit rien sur les critères de validation ou de rejet d'un canonical.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser ces directives ?
Placez vos balises meta robots et canonical en HTML statique, dans le <head>, avant tout JavaScript. Google les détectera plus vite et plus sûrement.
Évitez d'injecter ces balises via JavaScript client-side sauf si vous maîtrisez parfaitement le rendering côté Google. Le risque : un délai supplémentaire entre crawl et détection, voire une non-détection si le rendering échoue.
Comment gérer une migration ou une correction urgente ?
Si vous devez désindexer rapidement des pages (migration ratée, contenu en double massif), combinez plusieurs leviers :
- Ajoutez le noindex en HTML statique dans le
<head> - Complétez avec un X-Robots-Tag: noindex en en-tête HTTP pour doubler la sécurité
- Utilisez l'outil de suppression d'URL dans la Search Console pour accélérer le retrait (temporaire, 6 mois)
- Vérifiez que Googlebot peut bien accéder à la page pour crawler le noindex — pas de blocage robots.txt
- Surveillez les rapports de couverture pour confirmer la désindexation effective
Quelles erreurs éviter absolument ?
Ne bloquez jamais une URL en robots.txt tout en espérant qu'un noindex fonctionne. Si Google ne peut pas crawler la page, il ne peut pas lire le noindex. L'URL restera indexée indéfiniment avec un snippet vide.
Évitez les conflits entre canonical et noindex. Une page en noindex ne devrait pas pointer via canonical vers une autre URL — c'est incohérent. Google risque d'ignorer l'une ou l'autre directive.
Ne multipliez pas les balises canonical sur une même page (HTML + HTTP header + JavaScript). Privilégiez une source unique et fiable, de préférence en HTML statique.
L'extraction des balises meta robots et canonical pendant l'indexation plutôt qu'au crawl impose une rigueur technique stricte. Privilégiez l'HTML statique, anticipez les délais, et combinez plusieurs leviers en cas d'urgence.
Ces optimisations demandent une expertise pointue en architecture technique et un suivi rigoureux des processus d'indexation. Pour les sites à fort enjeu ou les migrations complexes, l'accompagnement d'une agence SEO spécialisée peut s'avérer déterminant pour éviter les erreurs coûteuses et garantir une mise en œuvre conforme aux recommandations de Google.
❓ Questions frequentes
Pourquoi mon noindex ne fonctionne-t-il pas immédiatement ?
Puis-je bloquer une page en robots.txt et ajouter un noindex ?
Le canonical en JavaScript est-il aussi efficace qu'en HTML ?
Google respecte-t-il toujours le canonical que je définis ?
Comment accélérer la désindexation d'une page avec noindex ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.