Official statement
Other statements from this video 12 ▾
- □ Pourquoi Google refuse-t-il désormais certaines directives dans le robots.txt ?
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
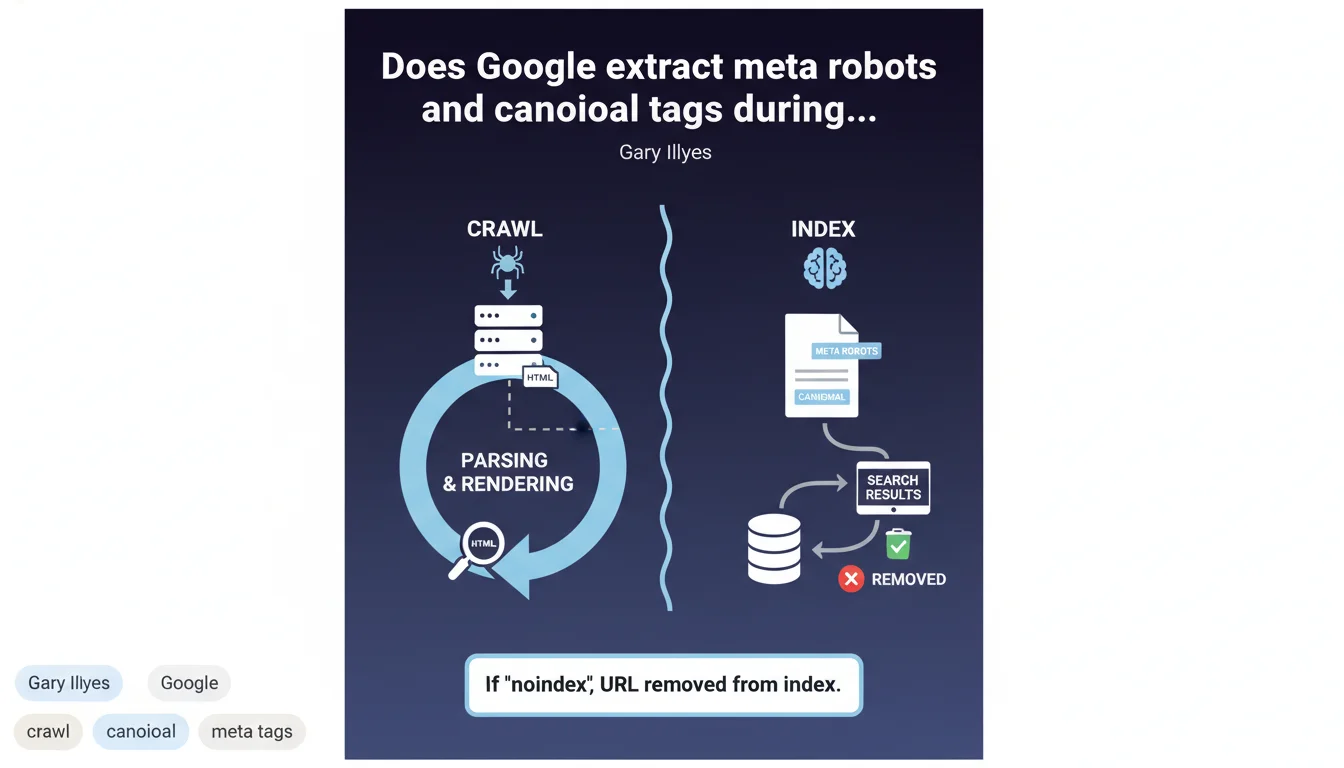
Google extracts meta robots noindex and rel canonical tags during the indexing phase, not during the initial crawl. These directives are read when the content is parsed and rendered. In practice: a page can be crawled multiple times before Google detects and applies a noindex directive.
What you need to understand
What's the actual difference between crawling and indexing in this context?
The crawl is simply Googlebot fetching the HTML code. Indexing happens next: this is when Google parses the content, executes JavaScript if needed, and analyzes the tags.
This distinction explains why a page with meta robots noindex can temporarily appear in Search Console as "Crawled - currently not indexed". The bot visited it, but hasn't processed the indexing directives yet.
What actually happens when a noindex is deployed?
If Google detects meta robots noindex during indexing, the URL will be removed from the index. But here's the catch: this removal isn't instantaneous.
A delay exists between the crawl and full processing. On sites with low crawl budget, this delay can be significant. This is where things get tricky for migrations or urgent fixes.
Does rendering play a role here?
Yes, and it's critical. If your noindex is injected via JavaScript, Google must perform rendering first to detect it.
This adds another layer of complexity and delay. Rendering doesn't happen on every first crawl—sometimes much later, especially on sites with low crawl budget or blocked resources.
- Meta robots and canonical tags are read during indexing, not during the initial crawl
- A delay exists between crawl and effective application of noindex
- JavaScript rendering can further delay detection of these tags
- A URL can be crawled multiple times before being deindexed due to a noindex directive
SEO Expert opinion
Does this match what we observe in practice?
Yes, largely. We regularly observe pages with noindex remaining visible in Search Console for days, even weeks, marked as "Discovered - currently not indexed" or "Crawled - currently not indexed".
Gary Illyes confirms here what we're seeing in the field: Google doesn't process meta robots directives instantly. Crawling and indexing are two distinct processes, with a pipeline that can be lengthy.
What gray areas remain?
The statement stays vague on actual timelines. How much time between crawl and full parsing? It depends on what—crawl budget, URL priority, Google's server load?
[To verify]: Google doesn't clarify if certain tags take priority over others. For example, will a JavaScript-injected noindex be processed as quickly as a static HTML noindex? Field observations suggest no, but Google doesn't say so explicitly.
Another unclear point: what happens if a page oscillates between noindex and index (deployment error, misconfigured A/B test)? Does Google retain "memory" of the previous state or reset on each crawl?
Does the canonical tag warrant special attention?
Absolutely. Google mentions rel canonical as a directive extracted during indexing, but let's remember that canonical remains a signal, not an absolute directive.
Unlike noindex, which is imperative, Google can choose to ignore a canonical if it detects inconsistencies (suspicious cross-domain canonical, canonical to a 404, canonical loops). This statement says nothing about validation criteria or reasons for rejecting a canonical.
Practical impact and recommendations
What should you do concretely to optimize these directives?
Place your meta robots and canonical tags in static HTML, in the <head>, before any JavaScript. Google will detect them faster and more reliably.
Avoid injecting these tags via client-side JavaScript unless you fully understand Google's rendering process. The risk: additional delay between crawl and detection, or even non-detection if rendering fails.
How do you handle an urgent migration or fix?
If you need to quickly deindex pages (failed migration, massive duplicate content), combine multiple strategies:
- Add noindex in static HTML within the
<head> - Reinforce with X-Robots-Tag: noindex in the HTTP header for extra security
- Use the URL removal tool in Search Console to accelerate removal (temporary, 6 months)
- Verify that Googlebot can access the page to crawl the noindex—no robots.txt blocking
- Monitor coverage reports to confirm effective deindexing
What mistakes should you absolutely avoid?
Never block a URL in robots.txt while hoping a noindex will work. If Google can't crawl the page, it can't read the noindex. The URL will remain indexed indefinitely with an empty snippet.
Avoid conflicts between canonical and noindex. A page with noindex shouldn't point via canonical to another URL—it's contradictory. Google will likely ignore one or the other directive.
Don't place multiple canonical tags on the same page (HTML + HTTP header + JavaScript). Use a single, reliable source, preferably in static HTML.
The extraction of meta robots and canonical tags during indexing rather than crawl requires strict technical rigor. Prioritize static HTML, anticipate delays, and combine multiple tactics in emergencies.
These optimizations demand specialized expertise in technical architecture and rigorous monitoring of indexation processes. For high-stakes sites or complex migrations, working with a specialized SEO agency can be crucial to avoid costly mistakes and ensure implementation aligned with Google's recommendations.
❓ Frequently Asked Questions
Pourquoi mon noindex ne fonctionne-t-il pas immédiatement ?
Puis-je bloquer une page en robots.txt et ajouter un noindex ?
Le canonical en JavaScript est-il aussi efficace qu'en HTML ?
Google respecte-t-il toujours le canonical que je définis ?
Comment accélérer la désindexation d'une page avec noindex ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 04/08/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.