Official statement
Other statements from this video 12 ▾
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi Google extrait-il les balises meta robots et canonical pendant l'indexation plutôt qu'au crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
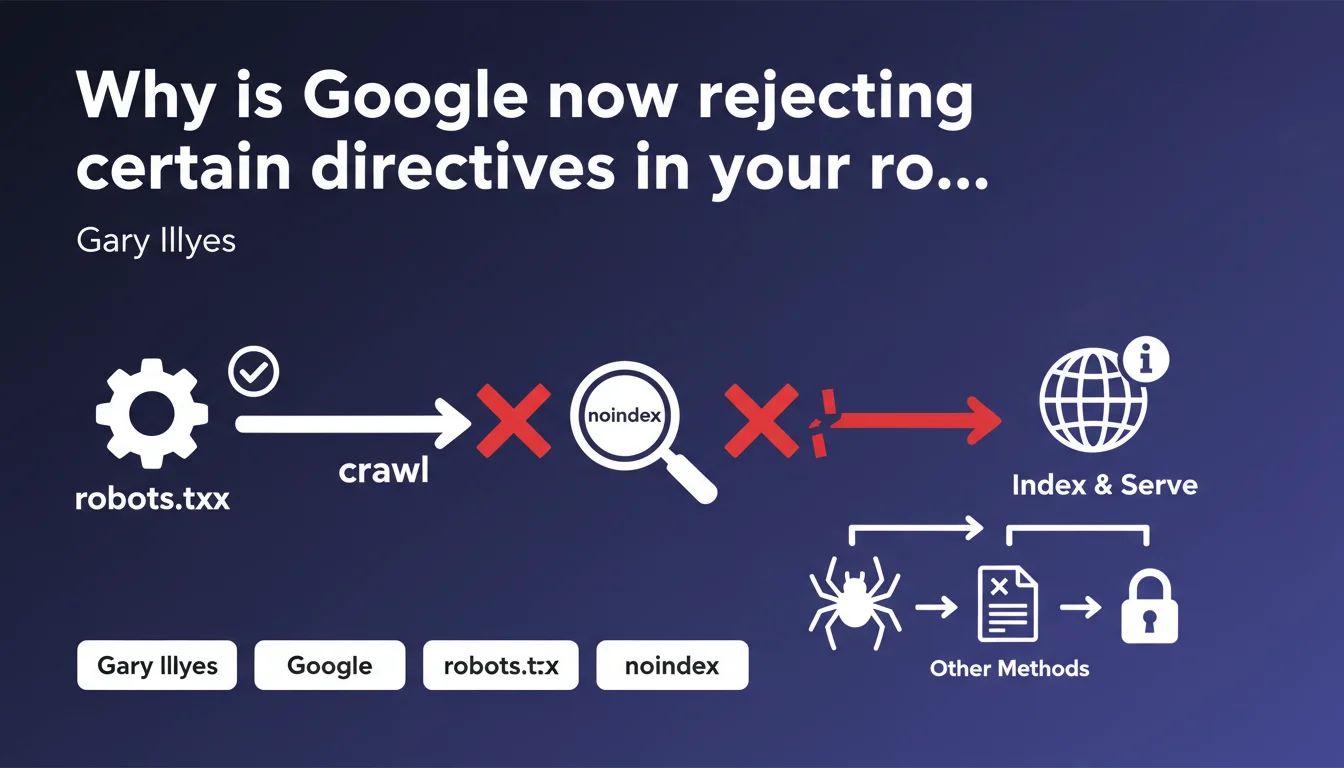
Google removed the noindex directive from its robots.txt parser and made it clear: this file should only control crawling, not indexing. A clarification that's forcing SEO professionals to reconsider some practices that are still widespread in the field.
What you need to understand
What is the real purpose of the robots.txt file?
The robots.txt is a crawl control file — nothing more. It tells search engine bots which URLs should not be explored, which helps you manage your crawl budget and avoid exploring unnecessary areas.
It's not an indexing tool. Blocking a URL in robots.txt prevents Googlebot from crawling it, but it doesn't guarantee that the URL will disappear from the index if it has already been discovered through other means — backlinks, sitemaps shared elsewhere, etc.
Why did Google remove the noindex directive from robots.txt?
Because it never concerned crawling. The noindex directive, originally supported by some search engines as an unofficial extension, was used to control indexation — which falls outside the strict scope of the robots.txt file.
Google formalized this position by removing the directive from its parser. The message is clear: use meta robots, X-Robots-Tag HTTP headers, or Search Console to manage indexation.
What are the practical consequences of this decision?
- robots.txt remains effective only for blocking crawling
- Any indexation directive (noindex, nofollow in robots.txt) is now ignored
- Sites using noindex in robots.txt must migrate to official methods
- A URL blocked in robots.txt can still appear in the index if it has external backlinks
- To properly remove a page from the index, you must allow crawling AND add a noindex tag
SEO Expert opinion
Does this clarification really change the game in practice?
Let's be honest — most serious SEO professionals weren't using noindex in robots.txt anyway. This directive was never part of the official standard, even though Google tolerated it for years.
What changes is the formalization. Google is dropping support, which forces laggards to clean up their practices. Some legacy sites were still using this method out of habit or lack of knowledge — they're about to discover that their directives have become useless.
Is this position from Google consistent with observed practices?
Absolutely. We've observed for a long time that blocking a URL in robots.txt doesn't prevent its indexation if it receives external signals (links, mentions). Google can index a page without crawling it — it just needs to know about its existence and have relevance signals.
The problem is that some SEO professionals still believe that robots.txt blocking = guaranteed de-indexation. Wrong. If you want to remove a URL from the index, it must be crawlable AND carry a noindex directive — otherwise Google can't read the instruction.
What gray areas remain despite this clarification?
Google doesn't always specify what happens when a URL already in the index is then blocked in robots.txt. In theory, it should remain in the index with a "no description available" note — but behavior varies. [To be verified] depending on contexts and external signals.
Practical impact and recommendations
What should you check immediately on your site?
Open your robots.txt and search for any mention of noindex, nofollow, noarchive or other indexation directives. If you find any, they're being ignored — you need to migrate to valid methods.
Also check URLs blocked in robots.txt that still appear in Google's index (search site:yourdomain.com). If they're present, that's normal — crawl blocking is not de-indexation.
How do you properly manage indexation now?
To block indexation of a page, you have three official options:
<meta name="robots" content="noindex">tag in the HTML <head>- X-Robots-Tag: noindex HTTP header (useful for PDFs, images, non-HTML files)
- Removal via Search Console (temporary — 6 months, then renew or implement a technical solution)
For all three methods, it's essential that the URL is crawlable. Never block in robots.txt a URL you want to de-index — otherwise Google can't read the noindex directive.
What mistakes must you absolutely avoid?
Never confuse crawling and indexation. Blocking crawling doesn't prevent indexation. Allowing crawling doesn't force indexation. These are two distinct mechanisms with distinct tools.
Avoid blocking entire sections in robots.txt just to "save crawl budget" if those sections contain pages you don't want indexed. You risk seeing them appear in the index without a description or control.
❓ Frequently Asked Questions
Puis-je encore utiliser noindex dans le robots.txt ?
Une URL bloquée en robots.txt peut-elle être indexée ?
Comment désindexer proprement une page ?
Le fichier robots.txt impacte-t-il le ranking ?
Que faire si j'ai des directives noindex dans mon robots.txt actuel ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 04/08/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.