Official statement
What you need to understand
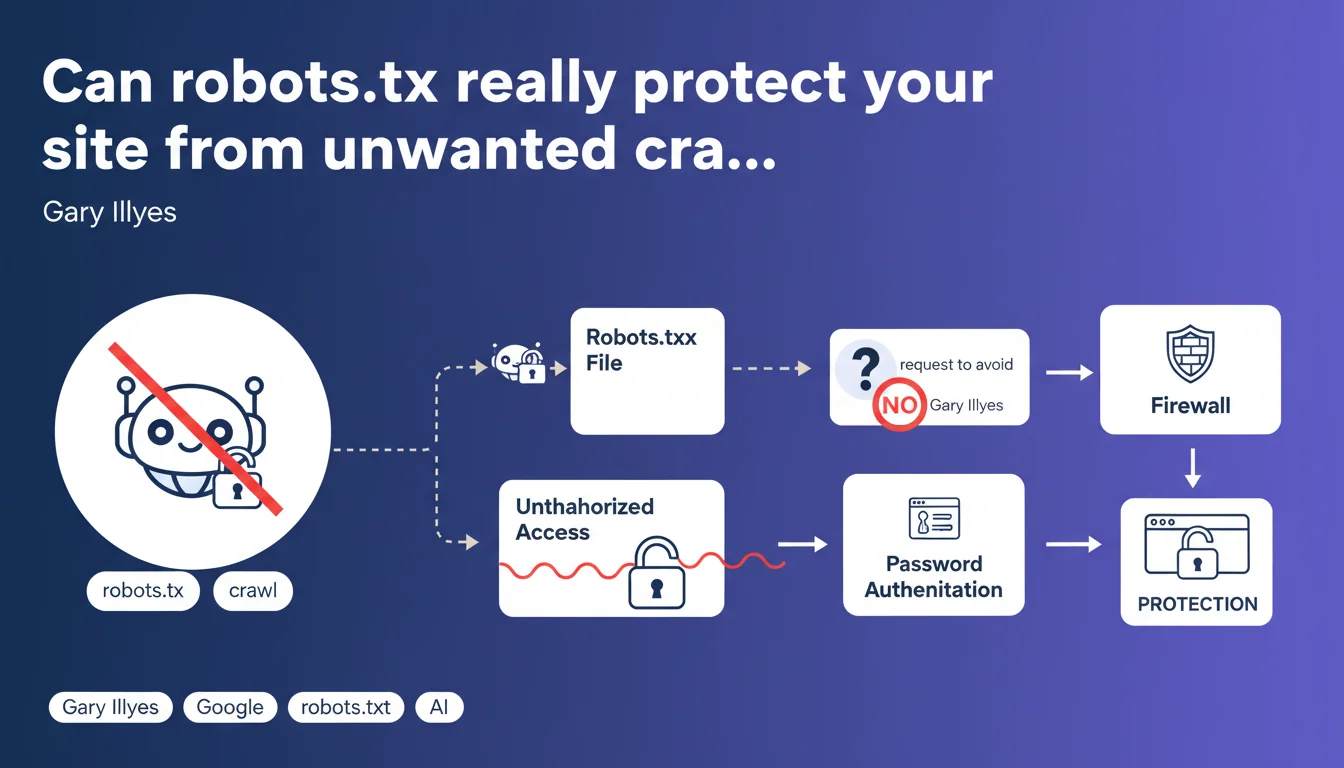
The robots.txt file is often mistakenly perceived as a security barrier. In reality, it is simply a directive file that search engine robots are invited to respect, without any guarantee of enforcement.
Google is emphasizing a fundamental truth here: robots.txt is merely a polite request, not a security mechanism. Any malicious or non-compliant crawler can choose to completely ignore it and access the content you thought you had protected.
This clarification is essential because many site owners use robots.txt to hide sensitive content: staging pages, personal data, or sections under development. This approach creates a false sense of security.
- Robots.txt = recommendation, not a technical block
- Respectful crawlers (Google, Bing) follow these directives
- Malicious bots can completely ignore these instructions
- The robots.txt file is public and viewable by everyone
- Real protection requires authentication or a firewall
SEO Expert opinion
This statement is perfectly consistent with what we've been observing in the field for years. Experienced SEO professionals know that robots.txt is used to manage crawl budget and indexation, never to secure content.
The important nuance concerns the dual purpose of the file. On one hand, it remains a valuable tool for optimizing how legitimate search engines crawl your site: blocking duplicate pages, infinite faceted filters, or URLs with parameters. On the other hand, it should never be your only line of defense.
In cases involving development or staging environments, the classic mistake is to rely solely on robots.txt. These environments must absolutely be protected by HTTP authentication, IP restriction, or hosting on a private domain.
Practical impact and recommendations
- Immediately audit your current robots.txt file: identify all blocked sections and ask yourself why
- Identify sensitive content currently "protected" only by robots.txt (admin, staging, private data)
- Implement password authentication (.htaccess, HTTP Basic Auth) for all truly confidential content
- Configure IP restrictions for development and pre-production environments
- Use the meta noindex tag (or X-Robots-Tag) to prevent indexation of pages that can be crawled
- Strategically combine robots.txt and noindex: block crawling of pages with no SEO value, use noindex for crawlable but non-indexable pages
- Regularly check in Google Search Console for URLs blocked by robots.txt that still appear in the index
- Train development teams on this fundamental distinction between directive and protection
- Document your strategy: create a table specifying why each section is blocked in robots.txt (crawl optimization vs. security attempt)
Implementing a robust security and indexation architecture requires a deep understanding of the interactions between robots.txt, meta tags, HTTP headers, and authentication mechanisms. These technical aspects affect both web security and advanced SEO.
For large-scale sites or complex architectures, working with a specialized SEO agency enables you to establish a coherent strategy that genuinely protects your sensitive content while optimizing the discoverability of your important pages. A comprehensive technical audit can reveal unsuspected vulnerabilities in your current configuration.
💬 Comments (0)
Be the first to comment.